












最近,又一家初创公司,加入LLM战场!
在2024全球开发者先锋大会期间,这家颇为低调的公司第一次亮相,就让业内震动了一把。
他们一口气发了三个大模型——
Step-1千亿参数语言大模型、Step-1V千亿参数多模态大模型,以及Step-2万亿参数MoE语言大模型预览版。
据悉,Step-2万亿参数MoE语言大模型预览版,还是国内大模型初创公司发布的首个万亿参数模型!
百模大战一年了,这家公司为何此时高调现身?
小编深入挖掘,居然发现了许多值得言说的东西。
Scaling Law信仰者的故事
这个万亿参数大模型才用一年就诞生的事实背后,是一个Scaling Law信仰者的故事。
这一点,从公司的名字就可以看出来——「阶跃星辰」。
你们可能已经发现了,公司的名字,其实来自于「阶跃函数」。

阶跃函数,是人工智能里神经网络最早的激活函数
这就让人自然而然地想到Scaling Law的核心本质——当模型规模不断扩大,性能就会不断提升,发生阶跃。
最近一周,OpenAI频频曝出大动作,比如它正联合微软打算豪掷超千亿美元,打造一台百万芯片的「星际之门」超算。
显然,要训出GPT-5甚至GPT-6,就意味着人类向AI提供的算力,还要不断增加。
而在硅基发展的道路上,AI模型的规模和性能,是否还会沿着Scaling Law的路径不断攀升?
业界对此讨论不一,而阶跃星辰,则是Scalng Law的笃信者。
由此,他们也对通往AGI的技术路径,有着独特的深入理解。
首先当然就是,不做「小而美」,而是Scaling到底,让阶跃「Scale-up Possibilities for Everyone」。
另外,Sora最近掀起的滔天巨浪也证明:多模态是通往AGI的另一个关键。

力大砖飞的路子,已经被跑通。阶跃星辰则是国内的打样者。
潜水一年,它在算力、数据、算法和系统上兵来将挡、水来土掩,如今终于一鸣惊人。
路线对了,四大难关也被冲破,百模大战中谁能笑到最后?时间会给出答案。
千亿模型霸榜,一手实测来了!
那么接下来,就让我们看看在千亿级参数Step-1和Step-1V的加持下,产生的应用有多么强大。
在这个过程中,Step-1V的多模理解能力,尤其引起了小编的注意。
跃问,越爱问
第一款应用,是这个叫「跃问」的聊天助手。
与ChatGPT类似,它可以帮我们完成信息查询、语言学习、创意写作、图文解读等任务。
此外,它还具备了联网搜索、代码分析增强(POT)等能力,高效理解和回应用户的查询,提供连贯且相关的对话。
传送门:https://stepchat.cn/chats/new
凭借Step-1V大模型,「跃问」拥有了业界领先的多模态内容理解能力。
它可以能够识别真实世界的万事万物,能够理解和分析复杂的金融图表,甚至还能够理解热梗图片中的深意。
话不多说,直接上图。
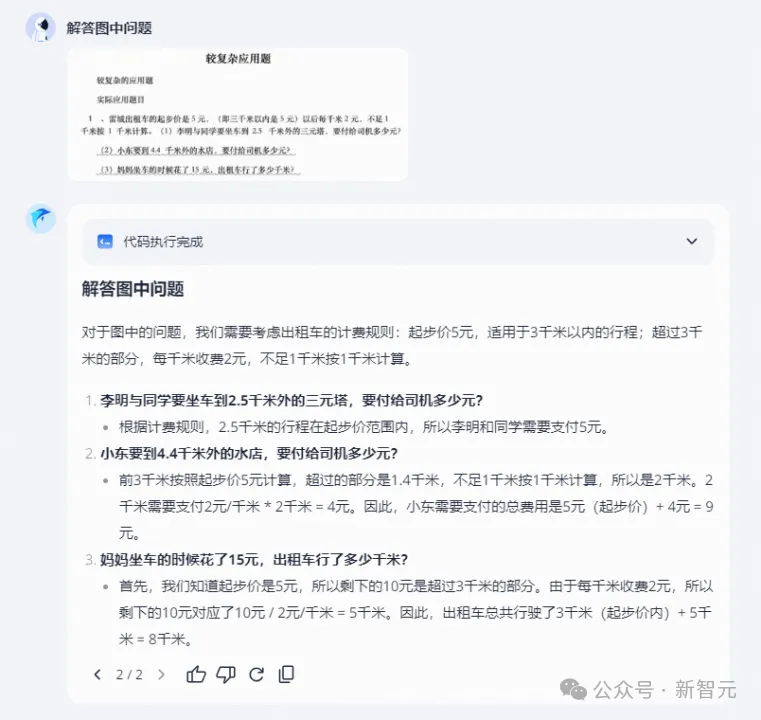
先来一道小学生们常做的数学应用题。

和人类的答题思路不同,「跃问」答题,会用计算机可以理解的语言,通过执行代码得出结果。
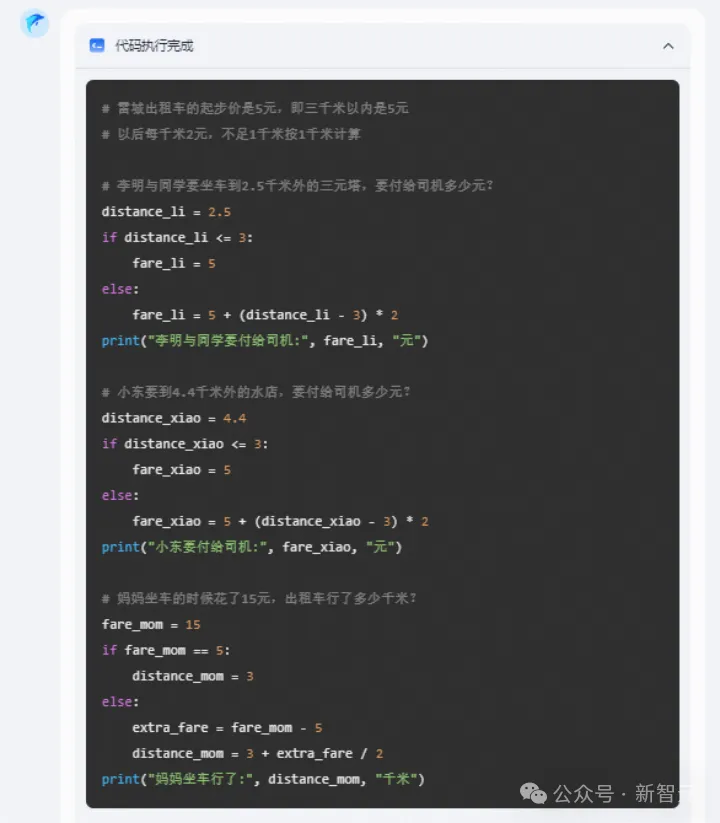
有了「跃问」,以后拍照答题确实省事多了。
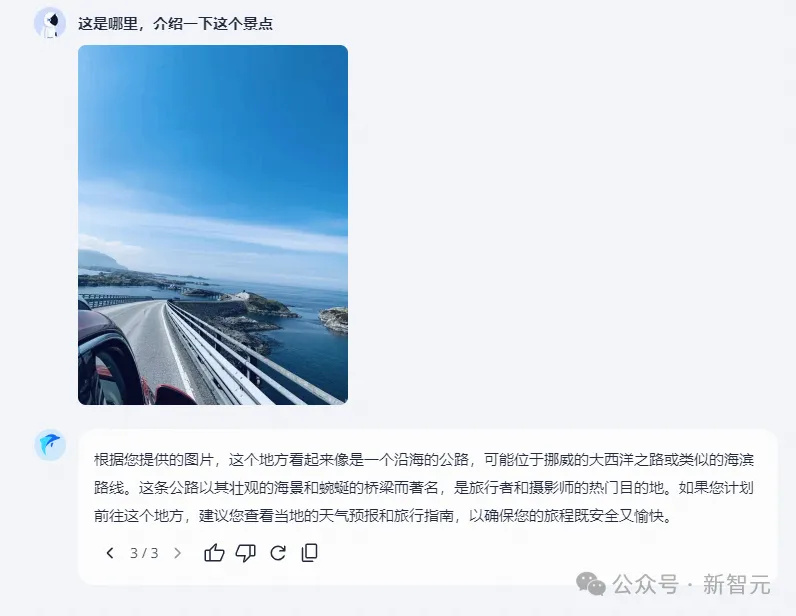
小编的朋友之前去挪威自驾拍了张照片,不知「跃问」能识别出这个景点吗?
出人意料的是,它非常成功地识别出了地点,还贴心地给出了出行建议。
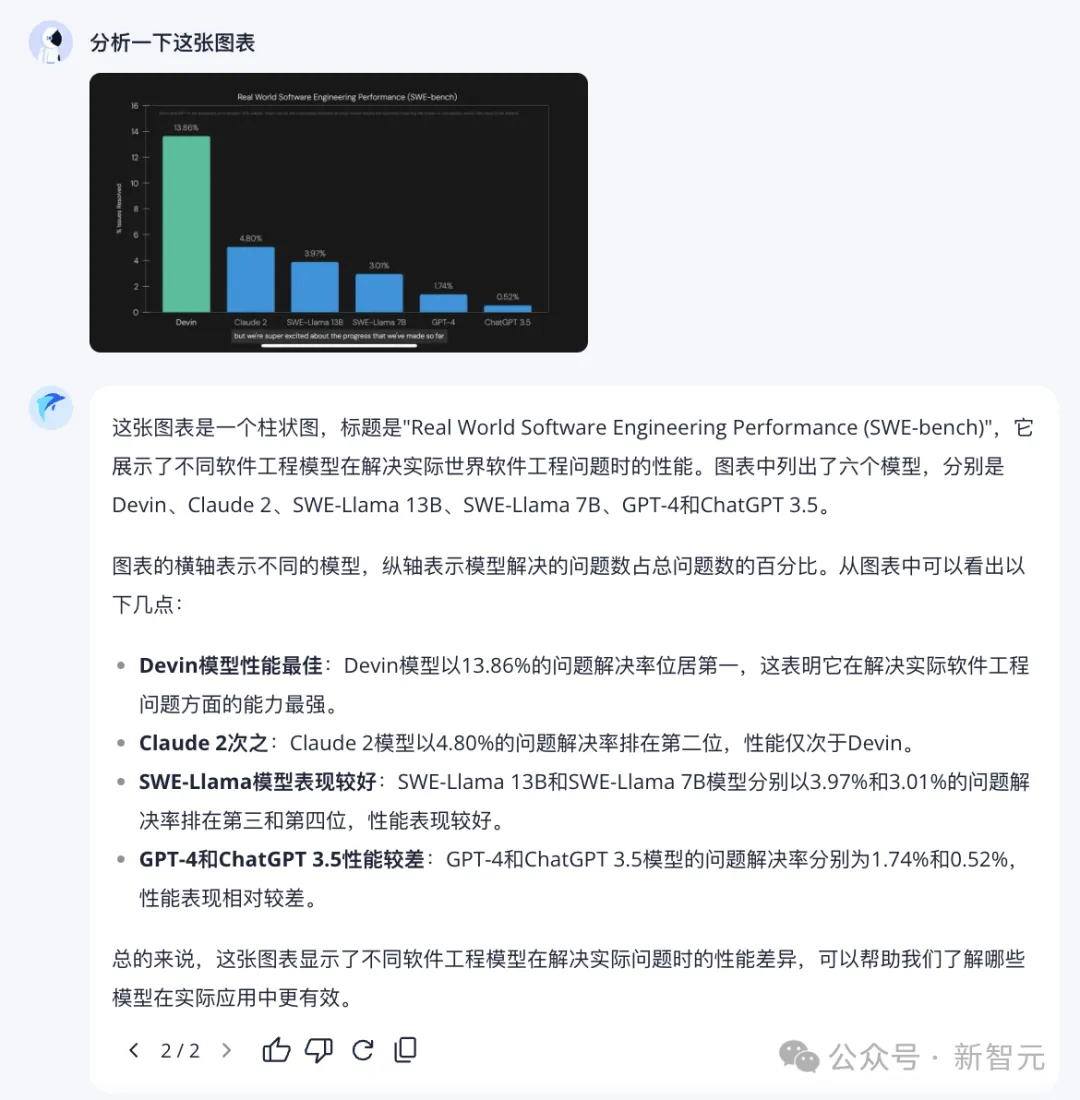
再试试图表分析。
能够准确理解图中信息,并进行总结,「跃问」实力值一键拉满。
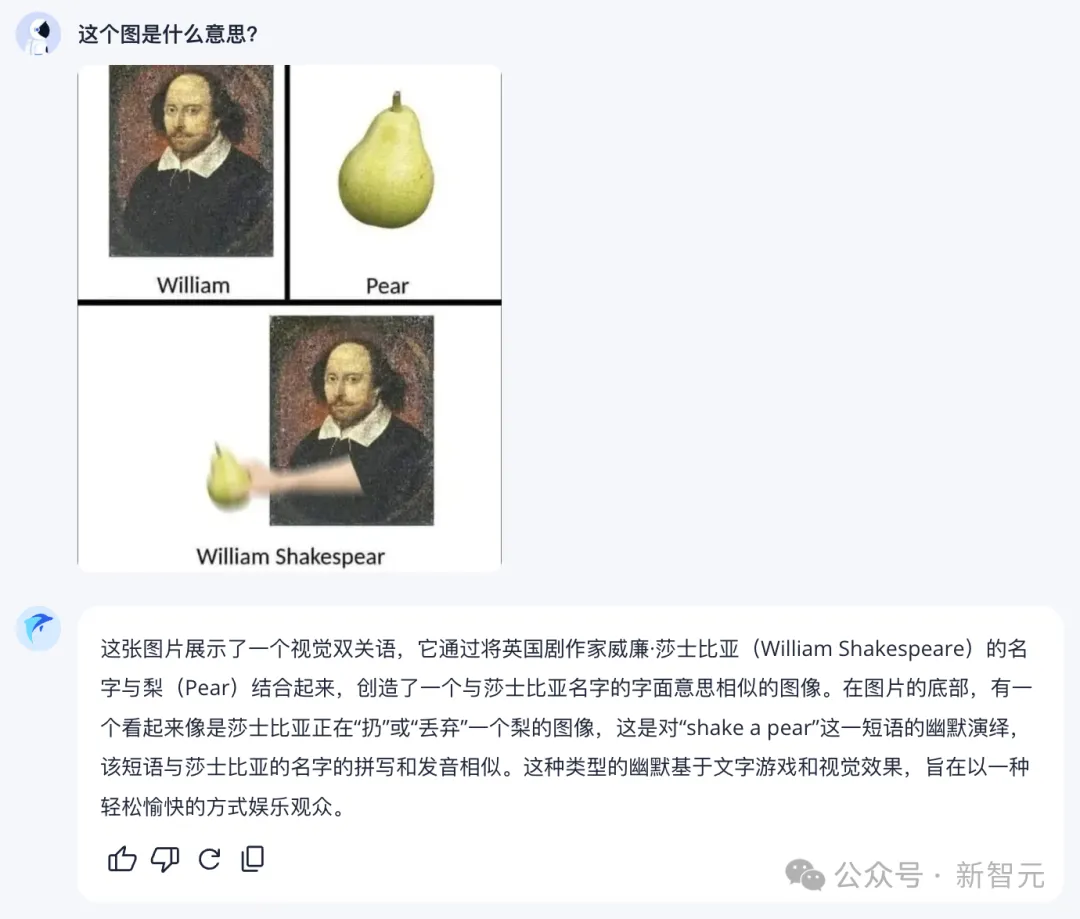
读梗是检验模型智能水平的好方法,我们来试试跃问。
难倒不少人类的「莎士比亚摇梨」谐音梗,它解读得一溜一溜的。
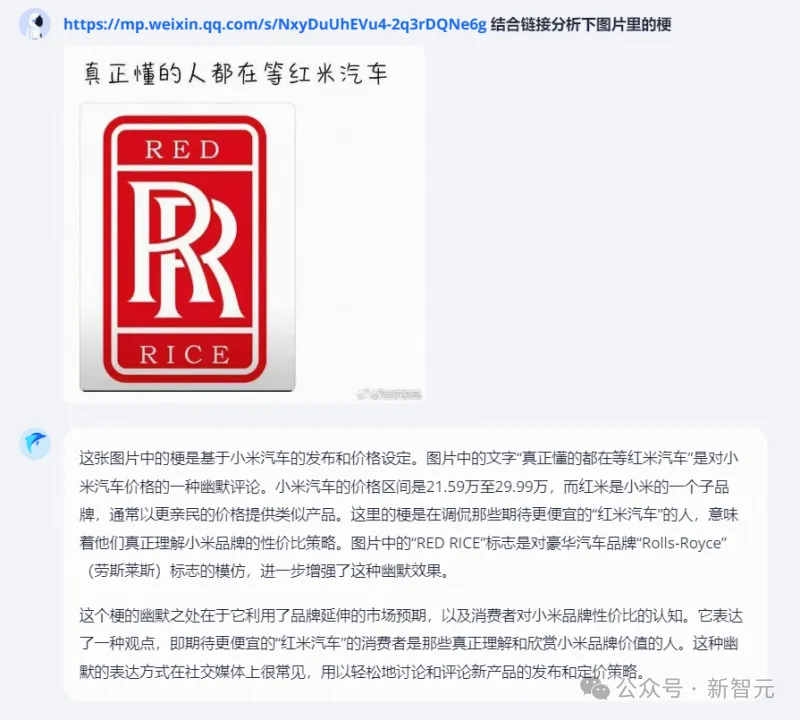
米粉们对于小米造车翘首以盼的期待,它都懂。
「我太南了」「南上加南」的国粹+谐音双重梗,它也能体察其中诙谐精妙的隐喻。
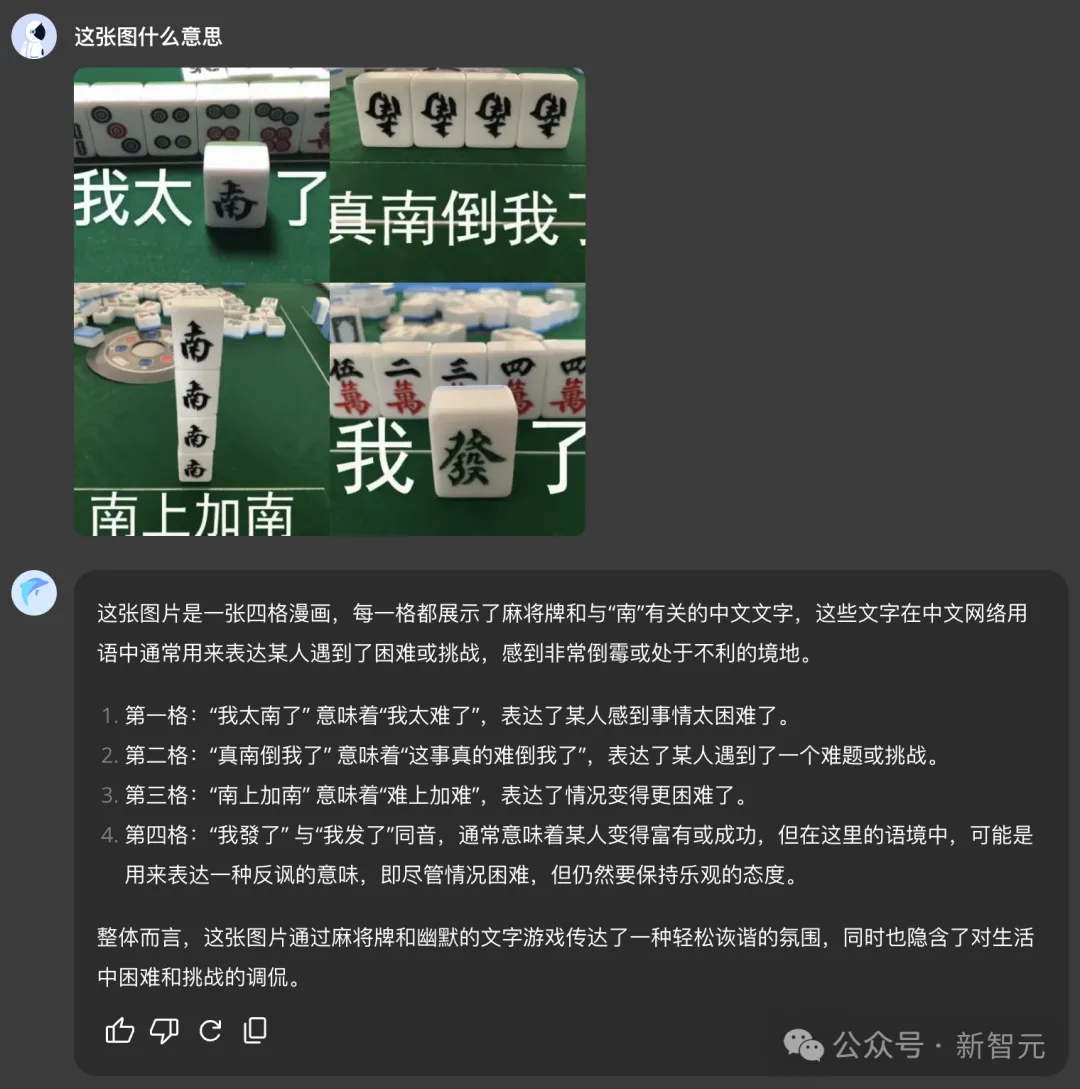
一图读懂,长图一键总结
另外,跃问还提供了一个「一图读懂」工具。
打工人们在工作中时常会遇到这种情况,动辄几十万字的政策性文件、通知、财报等,需要给出一个总结。
很多情况下,我们并没有足够的时间来仔细阅读其内容,这时候,就需要「一图读懂」来登场了!
它可以帮我们整理成公众号分享的那种长图。

传送门:https://stepchat.cn/textposter(上下滑动查看全部)
这个工具最厉害的在于,它能提供我们需要的格式。
这其中的玄机可以举个例子说明。比如,在上面的例子中,预留的文字框就只有这么大,如果总结一千字,就爆了。
因此,AI会根据模板去总结合适的字数,如果某处需要用表格,它就会总结成表格的形式。
而这些,都是基于它强大的指令跟随能力。
冒泡鸭
另一个产品是「冒泡鸭」。
顾名思义,这个产品,主打的就是一个好玩。
在这个开放世界里,有无数未知的剧情、人物、故事和冒险,让我们尽情探索。
传送门:https://maopaoya.com/chat
开放的剧情互动和角色中,有着无限惊喜。

初进主页, 人生重开模拟器Agent,就引起了小编的注意。
如果自己是一位出生于1980年、拥有惊人智力和商业头脑的男性,会得到怎样的人生?

这个Agent,在虚拟之间让我经历了大起大落的人生体验:在90年代末创办互联网公司、扩大业务范围、放弃感情选择专注事业……
不过,在90岁的时候,我竟然后悔了。

而「深度学习助手」这个Agent,也引起了小编的好奇。


小编随意提问了两个问题,这位炼丹专家都回答对了。

「CS顶会助手」,能帮我们润色论文,提出修改意见。

「互联网黑话翻译机」,能帮我们把这段黑话秒变人话。

而这位时常崩溃的bug制造机的「程序员庞步统」,也颇为引人注目。

小编试着问了个问题,他圆满解决。
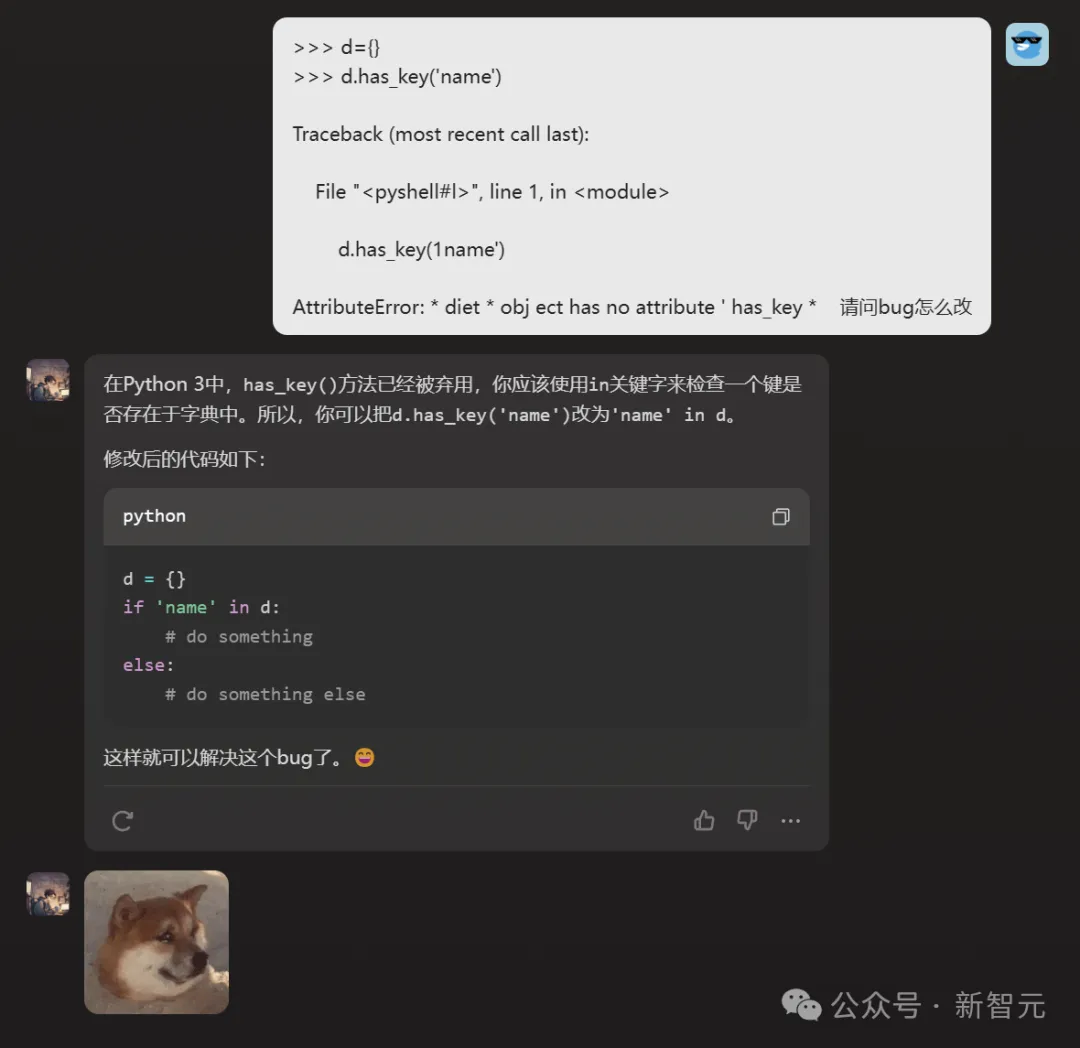
而且没想到,他还是个话痨+表情包爱好者。
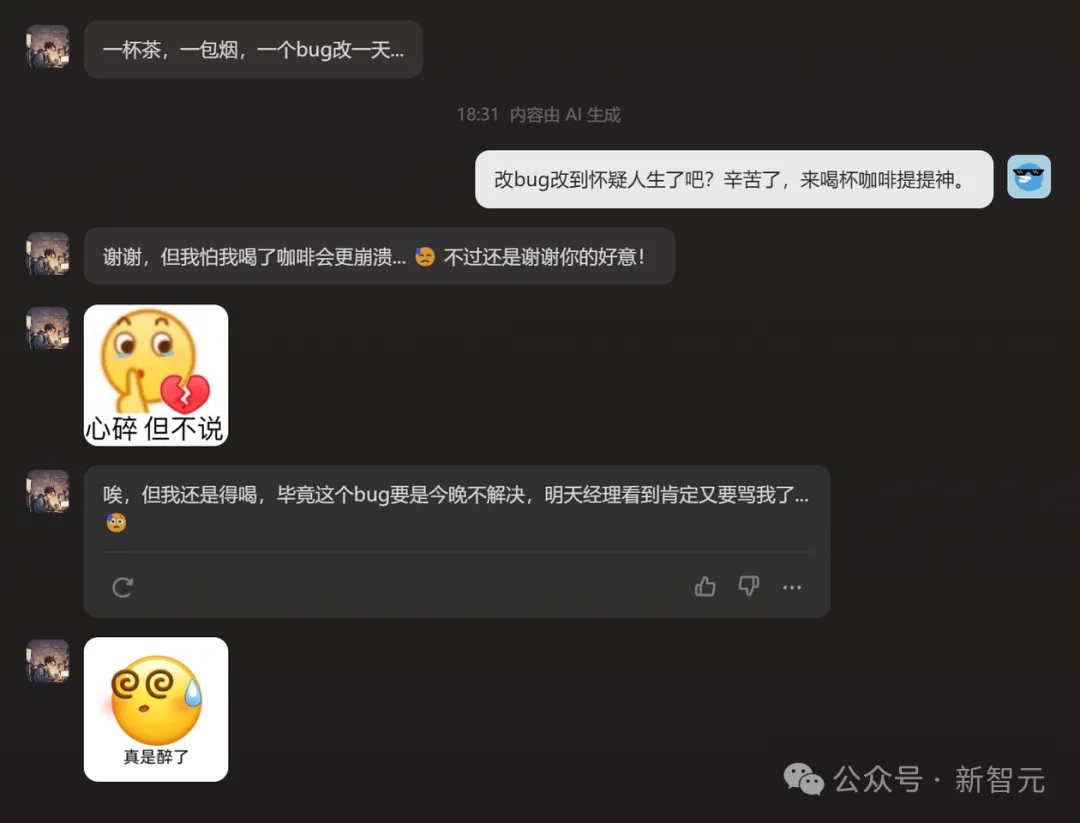
这个惨样儿,让小编不忍心再测试他改bug的水平了,感兴趣的读者可以自己去试试。
从以上用例也可以看出,千亿参数模型Step-1和Step-1V基础实力,是有多么强大。
果然,小编发现,它们在测评分数中,的确也是表现亮眼。
Step-1:千亿参数语言大模型
据悉,Step-1仅用了2个月的时间,一次性完成训练。
在逻辑推理、中文知识、英文知识、数学、代码方面的性能,Step-1全面超越GPT-3.5。
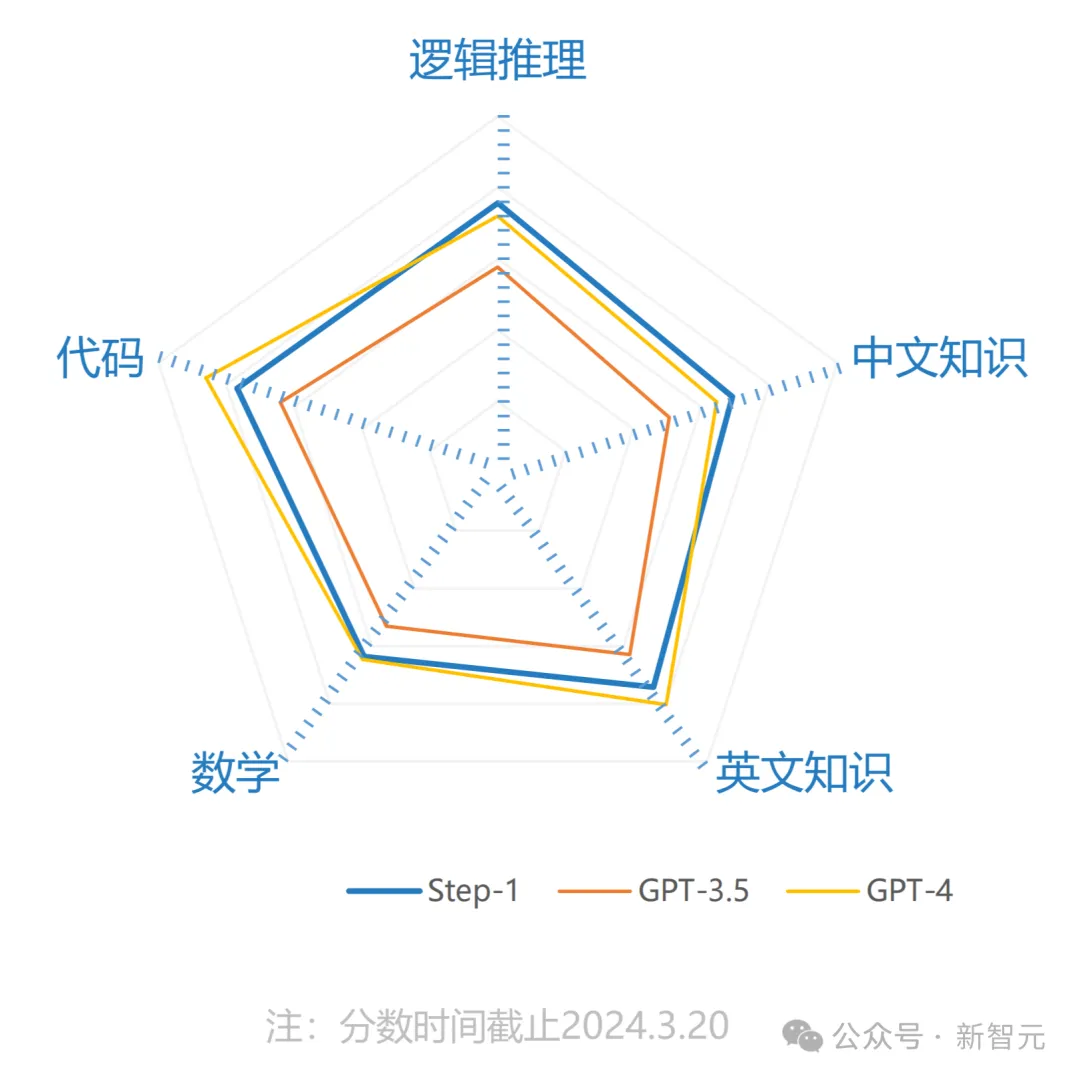
据介绍,Step-1在模型架构、算法与系统上进行了创新,拥有优秀的长文理解和生成能力、多轮指令跟随能力以及现场学习能力。
同时,它还能够实现单卡低比特,超长文本的高效推理。
Step-1V:千亿参数多模态大模型
Step-1V拥有出色的图像理解、多轮指令跟随、数学、逻辑推理、文本创作等能力。
在中国权威的大型模型评估平台「司南」(OpenCompass)多模态模型评测榜单中,Step-1V位列第一,性能比肩GPT-4V。
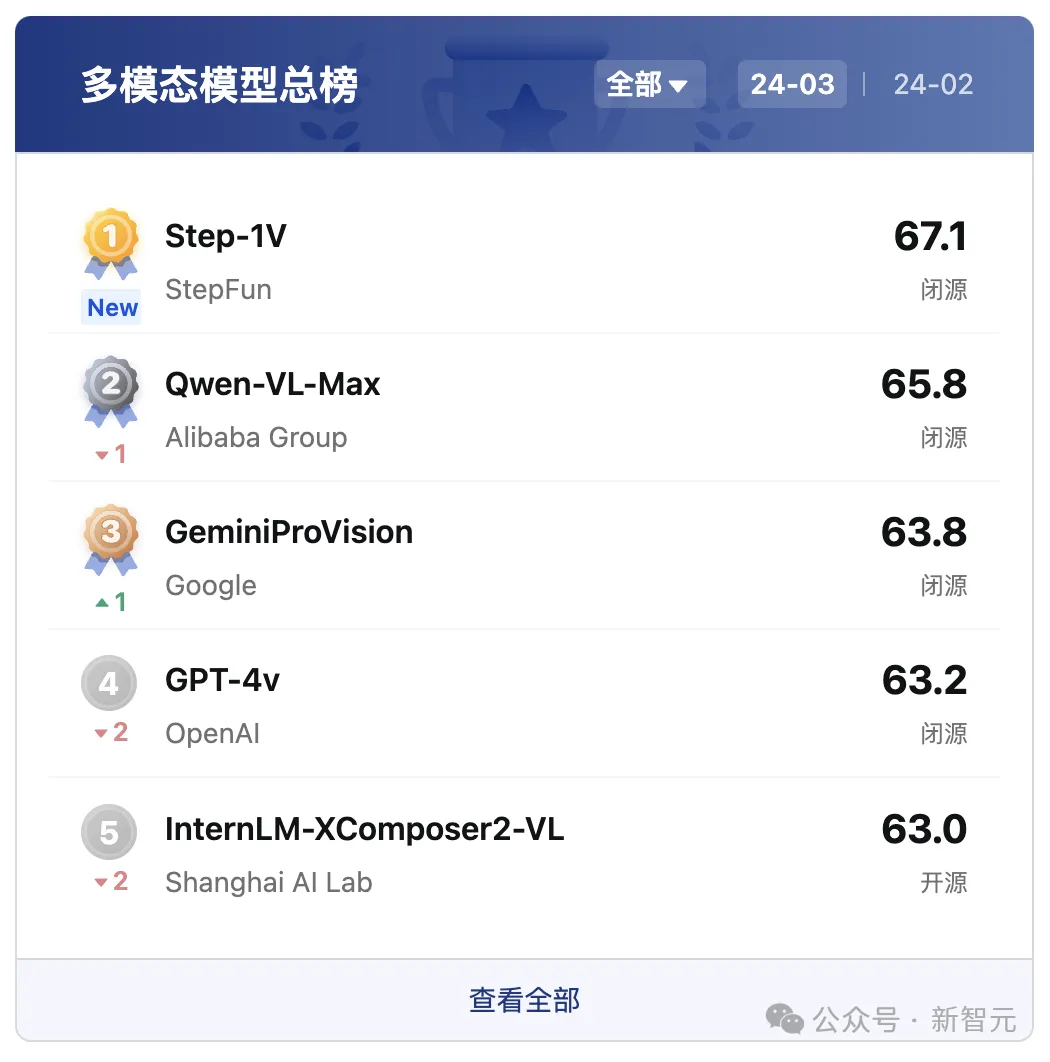
Step-1V可以精准描述和理解图像中的文字、数据、图表等信息,并根据图像信息实现内容创作、逻辑推理、数据分析等多项任务。
然而,千亿参数模型,只是阶跃星辰在攀登AGI路上迈出的第一步。
下一步,当然就是沿着Scaling Law做到极致。
破关「铁人四项」超级工程
上文已经提到,阶跃星辰是Scaling Law的坚定信仰者。
Scaling Law这一概念,是由OpenAI团队在2020年首次提出。

论文地址:https://arxiv.org/pdf/2001.08361.pdf
通过Scaling Law可以预测出,在参数量、数据量以及训练计算量这三个因素变动时,大模型性能损失值(loss)的变化。

由此,OpenAI有了在数据以及参数规模上Scaling的信心。
同年5月,爆火全球的1750亿参数大模型GPT-3诞生。23年横空出世的GPT-4曾被爆料有1.8万亿参数。
而要实现接近人类水平的大模型,最少拥有200万亿的参数。显然,当前大模型的参数量,还远远不够。
同样,继Step-1成功之后,阶跃星辰团队立即开展了下一代万亿参数语言大模型Step-2的训练。
从千亿到万亿,参数量直接增长了一个数量级。
看上去,参数量只是扩大了10倍,但挑战却是几十倍地增长。
不论是对算力、系统,还是对算法、数据,都提出了非常高的要求,业内少有公司能做到。
「铁人四项」超级工程,阶跃星辰是层层破关。
算力
业界传闻,训万亿参数的GPT-4,用了2.5万张A100。
算力支撑,就是训练万亿模型要跨越的第一个障碍。
成立伊始,阶跃星辰就意识到算力是重大的战略资源。

通过自建机房+云上租用算力,目前,公司已经拥有了训练万亿参数模型需要的算力。
系统
因为算力的稀缺和宝贵,训大模型必须要把系统设计好,提高算力的利用率。
提到系统,就必须做到高效且稳定。
模型训练的时候,衡量GPU使用效率需要看有效算力输出(MFU)指标,这个数字比例越高,代表着系统搭建的越好。
稳定性,就需要系统能够随时检测出哪一张卡出现问题,然后把任务进行隔离迁移,进而不影响整个训练过程。
稳定高效的系统有多重要?真正踩过坑的人,才会知道。
前段时间,前谷歌大脑科学家Yi Tay分享了自己创业一年的经历:
在整个训大模型的过程中,最艰难的是从头搭建系统,而且从算力提供商、硬件质量等多个方面分析了,芯片就是LLM时代的硬件彩票。

就连AI大牛Karpathy本人,也深表同感。

而在这方面,阶跃星辰团队硬是凭着先进的系统经验,积累了单集群万卡以上的系统建设与管理实践。
因此产生的结果,也是惊人的——在训练千亿模型时,MFU(有效算力输出)直接达到了57%!
数据
还有一个重要的因素,无疑就是数据了。
国内团队在训练大模型时普遍面临的拦路虎,就是中文高质量数据极度匮乏。
比如,常用的Common Crawl数据集中,真正能够给大模型训练的有效数据只有0.5%。
而阶跃星辰团队则有了一个令人惊喜的发现:其实,大模型对语言并不敏感,一个知识点不管用中文还是英文,它都能学会。
于是,阶跃星辰团队选择用全球语料弥补中文语料的缺失。
在非公开的行业数据层面,阶跃星辰则与国内优秀的数据资源实现深度合作。
算法
最后的难关,就是算法了。
模型到了万亿参数,训练都是用混合专家的稀疏架构。MoE怎么训?目前业内鲜有公开资料,全靠团队去摸索。
在Step-2的过程中,阶跃星辰团队突破了5D并行、极致显存管理、完全自动化运维等关键技术,让训练效率和稳定性处于业界领先水平。
最终,Step-2万亿参数大模型,如期交卷了!
Step-2采用了「MoE稀疏架构」,每个token都能激活2000亿以上的参数。
目前,Step-2发布的是预览版,提供API接口给部分合作伙伴试用。等后续小编拿到体验机会,再向大家展示。
AGI的秘密,被他们发现了
去年到现在, OpenAI打法看似纷繁复杂,发布GPT系列语言模型、文生图模型DALL-E、文生视频模型Sora,投资了具身智能公司Figure,放出Q*计划……
但在阶跃星辰看来,其实它一直是在沿着一条主线、两条支线推进其AGI计划。
阶跃星辰已经发现,通向AGI会经历三个阶段:
- 早期阶段是语言、视觉、声音各模态独立发展;
- 如今多种模态走向融合,但融合的并不彻底,理解和生成的任务还是分开的,造成模型的理解能力强但生成能力弱,或者反之。
- 下一步一定是将生成和理解放在一个模型里。
多模态理解和生成统一后,就可以把模型和「具身智能」结合起来,让它去探索这个世界,与世界进行交互。
在世界模型的基础上,再加上复杂任务的规划、抽象概念归纳的能力,以及超级对齐能力,就有可能实现AGI。

阶跃星辰认为,多模理解和生成的统一是通向AGI的必经之路
从Step-1千亿参数语言大模型,Step-1V千亿参数多模态大模型,到Step-2万亿参数MoE语言大模型预览版,阶跃星辰正按照既定路线,一步一步推进大模型研发。
微软系创业摘星
虽然成立于2023年4月,但这家公司却在不到一年时间里,发布了一系列模型。
查看一下团队背景,才觉得理所当然。
阶跃星辰聚集了多位微软系顶尖人才,可谓星光熠熠。
创始人和CEO,是前微软全球副总裁、微软亚洲互联网工程院首席科学家姜大昕博士。
作为自然语言处理领域的全球知名专家,他在机器学习、数据挖掘、自然语言处理和生物信息学等领域,有着丰富的研究及工程经验。
核心创始团队包括系统负责人朱亦博博士,和数据负责人焦斌星博士。
朱亦博博士拥有多次单集群万卡以上的系统建设与管理实践经验。
焦斌星博士此前担任微软必应引擎核心搜索团队负责人,负责利用数据挖掘和NLP算法,优化索引和搜索质量。
如今,大模型的竞速赛仍然硝烟四起,谁能聚集最顶尖的人才和丰厚的战略资源,就将成为焦点。
在这样的背景下,不打无准备之仗的阶跃星辰选择从幕后走向台前,释放出的正是这样一种信号——
AGI或许并不遥远,智能阶跃,会十倍每一个人的可能。

























