译者 | 朱先忠
审校 | 重楼
“生成对抗性网络”(GANs)在生成与过去的真实数据无法区分的真实合成数据方面表现出了卓越的性能。不幸的是,GANs因为其缺乏职业道德的的应用程序deepfakes而引起了公众的注意。

本文实例将使用GANs作为数据增强工具,试图解决与不平衡数据集相关的欺诈检测这一经典问题。更具体地说,GANs可以生成少数欺诈类的真实合成数据,并将不平衡的数据集完美平衡地转换。
简介
原则上,欺诈检测是二元分类算法的一种应用:对每笔交易进行分类,无论是否是欺诈类型的交易。其实,欺诈类型的交易往往只占交易领域的一小部分。一般来说,欺诈交易属于少数类别;因此,数据集高度不平衡。欺诈交易越少,交易系统就越健全。这一点是非常简单和直观的。
一个矛盾的问题是这种健全的条件很可能是过去欺诈侦查极具挑战性的主要原因之一。这仅仅是因为分类算法很难学习少数类别欺诈的概率分布。
一般来说,数据集越平衡,分类预测器的性能就越好。换句话说,数据集越不平衡(或越不平衡),分类器的性能就越差。
这描绘了欺诈检测的经典问题:具有高度不平衡数据集的二分类应用程序。
在这种情况下,我们可以使用生成对抗性网络(GANs)作为数据增强工具来生成少数欺诈类别的真实合成数据,以便更为平衡地转换整个数据集,从而提高欺诈检测分类器模型的性能。
本文将分为以下几个部分展开探讨:
- 第1节:算法概述(GANs的双层优化体系结构)
- 第2节:欺诈数据集
- 第3节:用于数据增强的GANs的Python代码解析
- 第4节:欺诈检测概述(基准场景与GANs场景)
- 第5节:结论
总的来说,我将主要介绍GANs的相关主题(包括算法和代码)。对于GANs之外的模型开发的其他方面的内容,如数据预处理和分类器算法,我将只概述其过程,而不讨论其细节。在这种情况下,本文假设读者对二进制分类器算法(特别是我为欺诈检测选择的集成分类器)有基本的了解,并对数据清理和预处理也有大致的了解。
有关详细代码,欢迎读者访问以下链接:
第1节:算法概述(GANs的双层优化体系架构)
GANs是一种特殊类型的生成算法,由两个神经网络组成:生成网络(生成器)和对抗性网络(鉴别器)。其中,生成器试图生成真实的合成数据,鉴别器将合成数据与真实数据区分开来。
最初的GANs是在一篇标题为《生成对抗性网络》的开创性的论文(Goodfellow等人共同发表,Generative Adversarial Nets,2014年出版,原文地址:https://arxiv.org/abs/1406.2661)中引入的。最初的GANs的合著者用造假者-警察的类比来描述GANs:一款迭代游戏,生成器充当造假者,鉴别器扮演警察的角色来检测生成器伪造的赝品。
最初的GANs在某种意义上是具有创新性的,它解决并克服了过去训练深度生成算法的传统困难。作为其核心,它被设计为具有均衡寻求目标设置(相对于最大似然导向目标设置)的双层优化架构。
从那以后,人们对GANs的许多变体架构进行了探索。本文将仅参考原始GANs的原型架构。
生成器和鉴别器
再强调一下,在GANs的架构中,两个神经网络——生成器和鉴别器——相互竞争。在这种情况下,竞争是通过前向传播和后向传播的迭代进行的(根据神经网络的一般框架原理)。
一方面,鉴别器是一个设计上的二元分类器:它对每个样本是真实的(标签:1)还是假的/合成的(标签为0)进行分类。在前向传播期间向鉴别器馈送真实样本和合成样本;在反向传播过程中,它学习从混合数据馈送中检测合成数据。
另一方面,生成器被设计为一个噪声分布。在正向传播期间向生成器提供真实样本。然后,在反向传播过程中,生成器学习真实数据的概率分布,以便更好地模拟其合成样本。
然后,通过“双层优化”框架对这两个代理进行交替训练。
双层训练机制(双层优化方法)
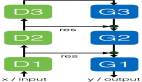
在最初的GAN论文中,为了训练这两个追求完全相反目标的代理,合著者设计了一个“双层优化(训练)”架构,其中一个内部训练块(鉴别器的训练)嵌套在另一个高级训练块(生成器的训练)中。
下图说明了嵌套训练循环中的“双层优化”结构。鉴别器在嵌套的内部循环中训练,而生成器在更高级别的主循环中训练。

GANs在这种双层训练架构中交替训练这两个代理(Goodfellow等人2014年合著论文《生成对抗性神经网络(Generative Adversarial Nets)》的第3页)。换言之,在交替过程中训练一个代理时,我们需要冻结另一个代理的学习过程(Goodfellow I.于2015年发表论文第3页的结论)。
Mini-Max优化目标
除了能够交替训练这两个代理的“双层优化”机制之外,GANs与传统神经网络原型的另一个独特之处是其最小-最大优化目标。简单地说,与传统的最大搜索方法(如最大似然)相比,GANs追求均衡搜索优化目标。
那么,什么是追求平衡的优化目标呢?
让我们把这个问题分解开来作解释。
GANs的两个代理有两个截然相反的目标。虽然鉴别器作为一种二元分类器,旨在最大限度地提高对真实样本和合成样本的混合物进行正确分类的概率,但生成器的目标是最大限度地降低鉴别器正确分类合成数据的概率:因为生成器需要欺骗鉴别器。
在这种情况下,最初GANs的合著者将总体目标称为“最小最大游戏”。(Goodfellow等人2014年合著论文的第3页)
总体而言,GANs的最终最小-最大优化目标不是搜索这些目标函数中的任何一个的全局最大值/最小值。相反,它被设置为寻求一个平衡点,该平衡点可以被解释为:
- “鞍点是分类器的局部最大值和生成器的局部最小值”(Goodfellow I.,2015,第2页)。
- 其中的两个代理都不能再提高它们的性能。
- 其中的生成器学会创建的合成数据已经变得足够现实,足以欺骗鉴别器。
平衡点在概念上可以用随机猜测的概率0.5(50%)来表示,对于鉴别器:D(z)=>0.5。
让我们根据GANs的目标函数来转录GANs的极大极小优化的概念框架。
鉴别器的目标是使下图中的目标函数最大化:

为了解决潜在的饱和问题,他们将生成器的原始对数似然目标函数的第二项转换如下,并建议将转换后的版本最大化为生成器的目标:
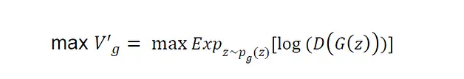
总体而言,GANs的“双层优化”架构可以转化为以下算法:

有关GANs算法设计的更多细节,请阅读我的另一篇文章:《生成对抗性网络的Mini-Max优化设计(Mini-Max Optimization Design of Generative Adversarial Nets):https://towardsdatascience.com/mini-max-optimization-design-of-generative-adversarial-networks-gan-dc1b9ea44a02》。
现在,让我们开始使用数据集进行实际的编程分析。
为了强调GANs算法,我将在本文主要关注GANs的实现代码,只概述一下其余的过程。
第2节:欺诈数据集
为了进行欺诈检测,我从Kaggle网站选择了以下信用卡交易数据集:https://www.kaggle.com/datasets/mlg-ulb/creditcardfraud
数据许可证:Database Contents License(DbCL)v1.0。
以下是该数据集的简要说明。
该数据集包含284807笔交易。在数据集中,我们只有492起欺诈交易(包括29起重复案件)。
由于欺诈类仅占所有交易的0.172%,因此这一部分数据形成了一个占极少数的类别。该数据集适用于说明与不平衡数据集相关的欺诈检测的经典问题。
该数据集具有以下30个特征:
- V1,V2,…V28:这28个主要成分通过PCA获得。出于保护隐私的目的,未披露数据来源。
- “Time”:每个事务与数据集的第一个事务之间经过的秒数。
- “Amount”:交易的金额。
- “Class”:标签设置为“Class”。欺诈情况下为1;否则,为0。
数据预处理:特征选择
由于数据集已经被清理得很干净,如果不是很完美的话,我只需要做几件事来清理数据:消除重复数据和去除异常值。
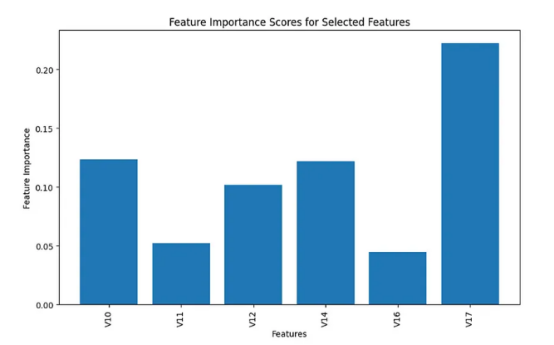
此后,在数据集中给定30个特征的情况下,我决定运行特征选择,通过在训练过程之前消除不太重要的特征来减少特征的数量。我选择了scikit-learn开源库中的随机森林分类器中内置的特征重要性分数来估计所有30个特征的分数。
下图显示了实验结果的摘要信息。如果您对其详细的流程感兴趣的话,请参阅我上面列出地址处的代码。
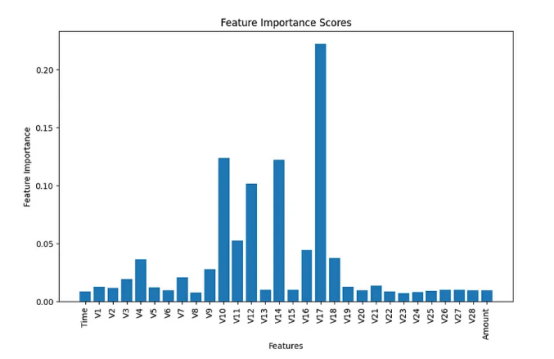
根据上面条形图中显示的结果,我做出了主观判断,选择了前6个特征进行分析,并从模型构建过程中删除了所有剩余的不重要特征。
以下是选定的前6个重要特征。
为了今后的模型构建目的,我重点介绍了这6个选定的特征。在数据预处理之后,我们得到了如下形状的工作数据帧df:
- df.shape=(282513,7)现在,我们希望特征选择能降低最终模型的复杂性并稳定其性能,同时保留优化二元分类器的关键信息。
第3节:用于数据增强的GANs的Python代码解析
现在是我们使用GANs进行数据增强的时候了。
那么,我们需要创建多少合成数据呢?
首先,我们对数据增强的兴趣仅限于模型训练。由于测试数据集中没有提供样本数据;所以,我们希望保留测试数据集的原始形式。其次,因为我们的目的是完美地转换不平衡的数据集;所以,我们不想增加占大多数的非欺诈性质的案例。
简言之,我们只想增加少数欺诈类型的训练数据集,而不想增加其他数据集。
现在,让我们使用分层数据拆分方法,将工作数据帧按80/20的比例拆分为训练数据集和测试数据集。
#分离特征和目标变量
X = df.drop('Class', axis=1)
y = df['Class']
#将数据拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
#组合训练数据集的特征和标签
train_df = pd.concat([X_train, y_train], axis=1)因此,训练数据集的形状如下:
- train_df.shape=(226010,7)
让我们看看训练数据集的组成(欺诈案例和非欺诈案例)。
# 加载数据集(欺诈和非欺诈数据)
fraud_data = train_df[train_df['Class'] == 1].drop('Class', axis=1).values
non_fraud_data = train_df[train_df['Class'] == 0].drop('Class', axis=1).values
# 计算要生成的合成欺诈样本的数量
num_real_fraud = len(fraud_data)
num_synthetic_samples = len(non_fraud_data) - num_real_fraud
print("# of non-fraud: ", len(non_fraud_data))
print("# of Real Fraud:", num_real_fraud)
print("# of Synthetic Fraud required:", num_synthetic_samples)
# of non-fraud: 225632
# of Real Fraud: 378
# of Synthetic Fraud required: 225254上面的输出告诉我们,训练数据集(226010)由225632个非欺诈数据和378个欺诈数据组成。换句话说,它们之间的差值是225254。这个数字是我们需要增加的合成欺诈数据(num_synthetic_samples)的数量,以便与训练数据集中这两个类别的数量完全匹配。注意,我们确实保留了原始测试数据集。
接下来,让我们对GANs进行编码。
首先,让我们创建几个自定义函数来确定两个代理:鉴别器和生成器。
对于生成器,我创建了一个噪声分布函数build_generator(),它需要两个参数:
latent_dim(噪声的维度)作为其输入的形状,以及其输出的形状output_dim——对应于特征的数量。
#定义生成器网络
def build_generator(latent_dim, output_dim):
model = Sequential()
model.add(Dense(64, input_shape=(latent_dim,)))
model.add(Dense(128, activation='sigmoid'))
model.add(Dense(output_dim, activation='sigmoid'))
return model对于鉴别器,我创建了一个自定义函数build_descriminator(),它接受一个input_dim参数,对应于特性的数量。
#定义鉴别器网络
def build_discriminator(input_dim):
model = Sequential()
model.add(Input(input_dim))
model.add(Dense(128, activation='sigmoid'))
model.add(Dense(1, activation='sigmoid'))
return model然后,我们可以调用这些函数来创建生成器和鉴别器。在这里,对于生成器,我随便将latent_dim设置为32:如果您愿意,当然也可以使用其它的值。
#生成器输入噪声的尺寸
latent_dim = 32
#构造生成器和鉴别器模型
generator = build_generator(latent_dim, fraud_data.shape[1])
discriminator = build_discriminator(fraud_data.shape[1])在这个阶段,我们需要编译鉴别器,它稍后将嵌套在主(更高)优化循环中。我们可以使用以下参数设置来编译鉴别器。
- 鉴别器的损失函数:二值分类器的通用交叉熵损失函数。
- 评价指标:准确度和召回率。
# 编译鉴别器模型
from keras.metrics import Precision, Recall
discriminator.compile(optimizer=Adam(learning_rate=0.0002, beta_1=0.5), loss='binary_crossentropy', metrics=[Precision(), Recall()])对于生成器,我们将在构建主(上)优化循环时对其进行编译。
在这个阶段,我们可以定义生成器的自定义目标函数,如下所示。请记住,推荐的目标是最大化以下公式:

注意,上面返回值前面的负号是必需的,因为默认情况下损失函数被设计为最小化。
然后,我们便可以构建双层优化架构的主(上)循环build_GANs(generator, discriminator)。在这个主循环中,我们隐式编译生成器。在这种情况下,当我们编译主循环时,我们需要使用生成器的自定义目标函数generator_loss_log_d。
如上所述,当我们训练生成器时,我们需要冻结鉴别器。
#结合生成器和鉴别器,构建并编译GANs主优化循环
def build_gan(generator, discriminator):
discriminator.trainable = False
model = Sequential()
model.add(generator)
model.add(discriminator)
model.compile(optimizer=Adam(learning_rate=0.0002, beta_1=0.5), loss=generator_loss_log_d)
return model
# 调用主循环函数
gan = build_gan(generator, discriminator)在上面的最后一行,GANs调用build_gan()函数,以便使用Keras框架中的model.train_on_batch()方法实现下面的批处理训练。
注意,当我们训练鉴别器时,我们需要冻结生成器的训练;当我们训练生成器时,我们需要冻结鉴别器的训练。
这是在双层优化框架下结合两个代理的交替训练过程的批量训练代码。
# 设置超参数
epochs = 10000
batch_size = 32
#训练GANs的循环
for epoch in range(epochs):
#训练鉴别器(冻结发生器)
discriminator.trainable = True
generator.trainable = False
#从真实的欺诈数据中随机抽样
real_fraud_samples = fraud_data[np.random.randint(0, num_real_fraud, batch_size)]
# 使用生成器生成虚假欺诈样本数据
noise = np.random.normal(0, 1, size=(batch_size, latent_dim))
fake_fraud_samples = generator.predict(noise)
#为真实和伪造的欺诈样本数据创建标签
real_labels = np.ones((batch_size, 1))
fake_labels = np.zeros((batch_size, 1))
#训练针对真伪欺诈样本的鉴别器
d_loss_real = discriminator.train_on_batch(real_fraud_samples, real_labels)
d_loss_fake = discriminator.train_on_batch(fake_fraud_samples, fake_labels)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)
#训练生成器(冻结鉴别器)
discriminator.trainable = False
generator.trainable = True
#生成合成欺诈样本并创建标签以训练生成器
noise = np.random.normal(0, 1, size=(batch_size, latent_dim))
valid_labels = np.ones((batch_size, 1))
# 训练生成器生成“欺骗”鉴别器的样本
g_loss = gan.train_on_batch(noise, valid_labels)
#打印进度
if epoch % 100 == 0:
print(f"Epoch: {epoch} - D Loss: {d_loss} - G Loss: {g_loss}")这里,我即兴想到一个问题,请你回答一下。
下面我们摘录了上面代码中与生成器训练相关的内容。
你能解释一下这个代码是做什么的吗?
# 生成合成欺诈样本并创建标签以训练生成器
noise = np.random.normal(0, 1, size=(batch_size, latent_dim))
valid_labels = np.ones((batch_size, 1))在第一行中,noise生成合成数据。在第二行中,valid_labels指定合成数据的标签。
为什么我们需要用1来标记它,这应该是真实数据的标签?你没有发现代码违反直觉吗?
女士们,先生们,欢迎来到造假者的世界!
这就是训练生成器创建可以欺骗鉴别器的样本的标记魔法!
现在,让我们使用经过训练的生成器为少数欺诈类型创建合成数据。
#训练后,使用生成器创建合成欺诈数据
noise = np.random.normal(0, 1, size=(num_synthetic_samples, latent_dim))
synthetic_fraud_data = generator.predict(noise)
#将结果转换为Pandas DataFrame格式
fake_df = pd.DataFrame(synthetic_fraud_data, columns=features.to_list())最后,创建合成数据。
在下一节中,我们可以将这些合成的欺诈数据与原始训练数据集相结合,使整个训练数据集完全平衡。我希望此完全平衡的训练数据集能够提高欺诈检测分类模型的性能。
第4节:欺诈检测概述(基准场景与GANs场景)
我们一再强调,本项目中使用的GANs仅用于数据增强,而不用于分类。
首先,我们需要一个基准模型作为比较的基础,以便评估基于GANs的数据增强对欺诈检测模型性能的改进。
作为一种二值分类器算法,我选择了Ensemble方法来构建欺诈检测模型。作为基准场景,我只使用原始的不平衡数据集开发了一个欺诈检测模型:因此,没有数据增强。然后,对于通过GANs进行数据增强的第二种场景,我可以使用完全平衡的训练数据集训练相同的算法,该数据集包含由GANs创建的合成欺诈数据。
- 基准场景:没有数据增强的集成分类器
- GANs场景:使用GANs数据增强的集成分类器(Ensemble Classifier)
基准场景:没有数据增强的集成
接下来,让我们定义基准场景(没有数据增强)。我决定使用集成分类器:用投票法作为元学习器,这将包括以下3个基本学习器:
- 梯度增强
- 决策树
- 随机森林
由于原始数据集特别不平衡——而不是准确性方面,所以我将从以下3个选项中选择评估指标:准确性、召回率和F1分数。
以下自定义函数ensemble_training(X_train,y_train)定义了训练和验证过程。
def ensemble_training(X_train, y_train):
#初始化基础学习器
gradient_boosting = GradientBoostingClassifier(random_state=42)
decision_tree = DecisionTreeClassifier(random_state=42)
random_forest = RandomForestClassifier(random_state=42)
#定义基型模型
base_models = {
'RandomForest': random_forest,
'DecisionTree': decision_tree,
'GradientBoosting': gradient_boosting
}
# 初始化元学习器
meta_learner = VotingClassifier(estimators=[(name, model) for name, model in base_models.items()], voting='soft')
# 用于存储训练和验证指标的列表
train_f1_scores = []
val_f1_scores = []
# 将训练集进一步拆分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=42, stratify=y_train)
# 训练和验证
for model_name, model in base_models.items():
model.fit(X_train, y_train)
#训练指标
train_predictions = model.predict(X_train)
train_f1 = f1_score(y_train, train_predictions)
train_f1_scores.append(train_f1)
#使用校验集合的校验指标
val_predictions = model.predict(X_val)
val_f1 = f1_score(y_val, val_predictions)
val_f1_scores.append(val_f1)
# 在整个训练集中训练元学习器
meta_learner.fit(X_train, y_train)
return meta_learner, train_f1_scores, val_f1_scores, base_models下一个函数ensemble_evaluations(meta_learner, X_train, y_train, X_test, y_test)负责计算元学习器级别的性能评估指标。
def ensemble_evaluations(meta_learner,X_train, y_train, X_test, y_test):
#两个训练的GANs测试数据集上集成模型的指标
ensemble_train_predictions = meta_learner.predict(X_train)
ensemble_test_predictions = meta_learner.predict(X_test)
#计算集成模型的指标
ensemble_train_f1 = f1_score(y_train, ensemble_train_predictions)
ensemble_test_f1 = f1_score(y_test, ensemble_test_predictions)
# 计算训练和测试数据集的精度和召回率
precision_train = precision_score(y_train, ensemble_train_predictions)
recall_train = recall_score(y_train, ensemble_train_predictions)
precision_test = precision_score(y_test, ensemble_test_predictions)
recall_test = recall_score(y_test, ensemble_test_predictions)
#输出训练和测试数据集的精度、召回率和f1分数
print("Ensemble Model Metrics:")
print(f"Training Precision: {precision_train:.4f}, Recall: {recall_train:.4f}, F1-score: {ensemble_train_f1:.4f}")
print(f"Test Precision: {precision_test:.4f}, Recall: {recall_test:.4f}, F1-score: {ensemble_test_f1:.4f}")
return ensemble_train_predictions, ensemble_test_predictions, ensemble_train_f1, ensemble_test_f1, precision_train, recall_train, precision_test, recall_test下面,让我们来看一看基准集成分类器的性能数据。
Training Precision: 0.9811, Recall: 0.9603, F1-score: 0.9706
Test Precision: 0.9351, Recall: 0.7579, F1-score: 0.8372可见,在元学习器水平上,基准模型生成了0.8372的合理水平的F1分数。
接下来,让我们转到使用GANs进行数据增强的场景。我们想看看使用GAN的场景的性能是否能优于基准场景。
GANs场景:通过GANs增强数据进行欺诈检测
最后,我们将原始的不平衡训练数据集(包括非欺诈和欺诈案例)train_df和GAN生成的合成欺诈数据集fake_df相结合,构建了一个完全平衡的数据集。在这里,我们不将测试数据集包含在此过程中,以便将其保留为原始数据集。
wdf = pd.concat([train_df, fake_df], axis=0)我们将使用混合平衡数据集训练相同的集成方法,看看它是否会优于基准模型。
现在,我们需要将混合平衡的数据集拆分为特征和标签。
X_mixed = wdf[wdf.columns.drop("Class")]
y_mixed = wdf["Class"]请记住,当我早些时候运行基准场景时,我已经定义了必要的自定义函数来训练和评估集成分类器。我也可以在此使用这些自定义函数并使用组合起来的平衡数据来训练相同的Ensemble算法。
我们可以将特征和标签(X_mixed,y_mixed)传递到自定义集成分类器函数Ensemble_training()中。
meta_learner_GANs, train_f1_scores_GANs, val_f1_scores_GANs, base_models_GANs=ensemble_training(X_mixed, y_mixed)最后,我们可以使用测试数据集对模型进行评估。
ensemble_evaluations(meta_learner_GANs, X_mixed, y_mixed, X_test, y_test)结果如下:
Ensemble Model Metrics:
Training Precision: 1.0000, Recall: 0.9999, F1-score: 0.9999
Test Precision: 0.9714, Recall: 0.7158, F1-score: 0.8242结论
现在,我们终于可以评估GANs的数据增强是否如我所期望的那样提高了分类器的性能了。
让我们来比较一下基准场景和GANs场景之间的评估指标。
以下是基准场景的结果:
# The Benchmark Scenrio without data augmentation by GANs
Training Precision: 0.9811, Recall: 0.9603, F1-score: 0.9706
Test Precision: 0.9351, Recall: 0.7579, F1-score: 0.8372以下是GANs场景的结果:
Training Precision: 1.0000, Recall: 0.9999, F1-score: 0.9999
Test Precision: 0.9714, Recall: 0.7158, F1-score: 0.8242当我们回顾训练数据集上的评估结果时,很明显,在所有三个评估指标中,GANs场景的表现都优于基准场景。
然而,当我们关注样本外测试数据的结果时,GANs情景仅在精度方面优于基准情景(基准场景:0.935相对于GANs场景:0.9714):在召回和F1得分方面未能做到这一点(基准场景:0.7579;0.8372相对于GANs场景:0.7158;0.8242)。
更高的精度意味着,与基准场景相比,该模型对欺诈交易的预测中包含的非欺诈交易比例更低。
召回率较低意味着,该模型未能检测到某些类型的实际欺诈交易。
这两个比较表明:虽然GANs的数据增强成功地模拟了训练数据集中的真实欺诈数据,但未能捕捉到样本外测试数据集中实际欺诈案例的多样性。
GANs在模拟训练数据的特定概率分布方面做得太好了。具有讽刺意味的是,使用GANs作为数据增强工具,考虑到对训练数据的过拟合,导致了所产生的欺诈检测(分类)模型的泛化能力较差。
很矛盾的是,上面提供的这个特定的例子提出了一个反直觉的情况,即与更简单的传统算法相比,更复杂的算法可能不一定能保证更好的性能。
此外,我们还可以考虑到另一个意想不到的后果,即碳能耗问题:在模型开发中添加耗能高的算法可能会增加我们日常生活中使用机器学习的碳能耗。这种情况展示了一个不必要的浪费能耗的例子,此时不必要地浪费了能量而没有提供更好的性能。
在这里,我想给您留下一些关于机器学习能耗知识的链接,供参考:
- https://spectrum.ieee.org/ai-energy-consumption
- https://www.cell.com/joule/fulltext/S2542-4351(23)00365-3?_returnURL=https%3A%2F%2Flinkinghub.elsevier.com%2Fretrieve%2Fpii%2FS2542435123003653%3Fshowall%3Dtrue
今天,我们已经拥有许多的GANs变体。在未来的文章中,我想探索GANs的其他变体,看看是否有任何变体可以捕获更广泛的原始样本多样性,从而提高欺诈检测器的性能。
参考资料
- Borji, A. (2018, 10 24)。Pros and Cons of GAN Evaluation Measures,链接地址: https://arxiv.org/abs/1802.03446。
- Goodfellow, I. (2015, 5 21). On distinguishability criteria for estimating generative models,链接地址:https://arxiv.org/abs/1412.6515。
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozairy, S., . . . Bengioz, Y. (2014, 6 10). Generative Adversarial Nets,链接地址:https://arxiv.org/abs/1406.2661。
- Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozairy, S., . . . Bengioz, Y. (2014, 6 10). Generative Adversarial Networks,链接地址:https://arxiv.org/abs/1406.2661。
- Knight, W. (2018, 8 17). Fake America great again. Retrieved from MIT Technology,链接地址:https://www.technologyreview.com/2018/08/17/240305/fake-america-great-again/。
- Suginoo, M. (2024, 1 13). Mini-Max Optimization Design of Generative Adversarial Networks (GAN) ,链接地址:
https://towardsdatascience.com/mini-max-optimization-design-of-generative-adversarial-networks-gan-dc1b9ea44a02。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Fraud Detection with Generative Adversarial Nets (GANs),作者:Michio Suginoo