一、通过关联表(N-N)
正常两张表进行关联,我们可以采用中间表的方式,这是最灵活的方式,它可以直接将两张表的数据根据某个字段直接关联起来。
下面是一个简单的例子来解释这个概念: 假设我们有两个表:students(学生)和 courses(课程)。一个学生可以选修多门课程,同时一门课程也可以被多个学生选修。这就是一个典型的多对多关系。
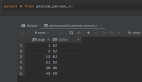
1.students 表
2.courses 表
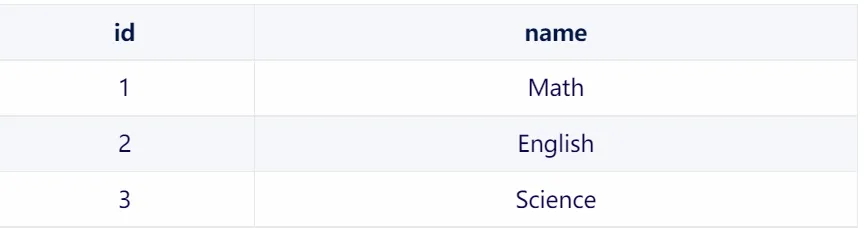
为了表示学生和课程之间的多对多关系,我们可以使用一个中间表 student_courses:
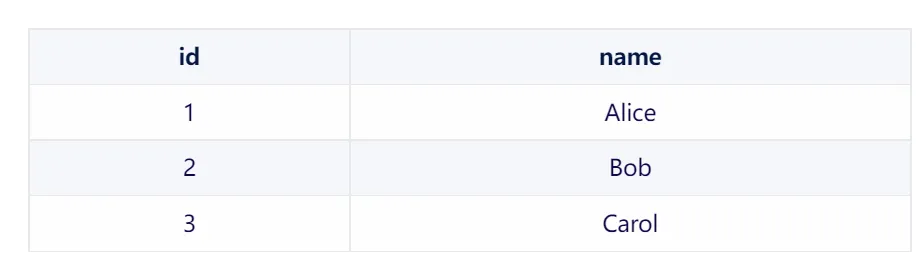
3.student_courses 表
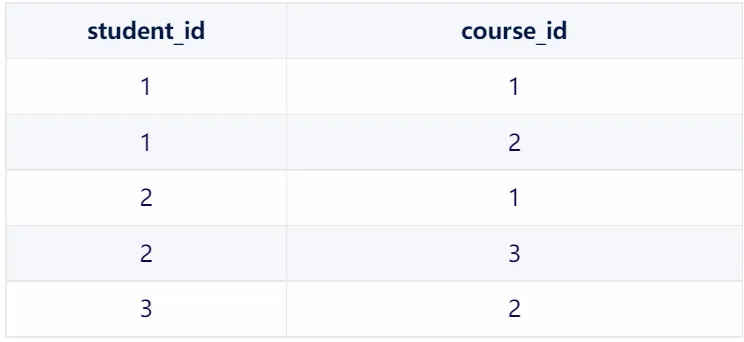
在这个中间表中,每一行都表示一个学生和一门课程之间的关联。例如,第一行表示 Alice(学生ID为1)选修了 Math(课程ID为1)。 通过查询这个中间表,我们可以轻松地获取某个学生选修的所有课程,或者获取选修了某门课程的所有学生。 这种使用中间表的方式非常灵活,因为它允许我们轻松地添加、删除或修改学生和课程之间的关联,而不需要修改原始的 students 或 courses 表。
二、主从设计(1-N)
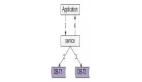
除了上面那种方式,还有一种主从设计,就是一张主表,一张明细表(或者叫做从表)。
主从设计或称为父子表设计是数据库中常见的另一种表关联方式。在这种设计中,主表通常存储主要实体的信息,而明细表或从表则存储与主表实体相关的详细或子项信息。这种设计常用于一对多关系,即一个主表记录对应多个明细表记录。 以下是一个主从设计的例子:
1.主表:orders(订单)
order_id | customer_id | order_date | total_amount |
1 | 101 | 2023-04-01 | 100.00 |
2 | 102 | 2023-04-02 | 150.00 |
2.明细表:order_items(订单项)
item_id | order_id | product_id | quantity | unit_price |
1 | 1 | 1001 | 2 | 50.00 |
2 | 1 | 1002 | 1 | 20.00 |
3 | 2 | 1003 | 3 | 50.00 |
在这个例子中:
- orders 表是主表,它存储了订单的基本信息,如订单ID、客户ID、订单日期和总金额。
- order_items 表是明细表或从表,它存储了每个订单的详细项,如订单项ID、所属的订单ID、产品ID、数量和单价。
通过 order_id 字段,order_items 表与 orders 表建立了关联。这样,我们可以轻松地查询某个订单的所有项,或者查询某个产品的所有订单项。 主从设计的优点是:
- 结构清晰:主表和明细表各司其职,主表存储总体信息,明细表存储详细信息。
- 灵活扩展:如果需要添加更多的与主表相关的详细信息,可以在明细表中添加更多字段,而不会影响主表的结构。
- 易于维护:由于主表和明细表是分离的,所以对其中一个表的修改不会影响到另一个表。
需要注意的是,在设计数据库时,应根据实际业务需求和数据关系来选择合适的表关联方式。有时,可能需要结合使用中间表、主从设计或其他设计模式来满足复杂的业务需求。
三、关联设计(1-N)
除了上面说的主从设计,还有一些情况,就是两张表并非主从关系,但是也有一定的逻辑关联性。比如一个手机生产订单,我们要根据这个订单生成一个多个工单,分为原料采购工单,组装工单,包装工单等。这种也是一对多的关系,但并非主从关系,针对这种情况,我们需要做关联设计。
我们可以为手机订单表和工单表创建相应的数据库表结构,并模拟一些基础数据。以下是使用SQL语言创建表和插入数据的示例:
- 创建手机订单表 (phone_orders)
CREATE TABLE phone_orders (
sid INT PRIMARY KEY NOT NULL,
phone_name VARCHAR(100) NOT NULL,
phone_quantity INT NOT NULL
);- 创建工单表 (work_orders)
CREATE TABLE work_orders (
sid INT PRIMARY KEY NOT NULL,
sSrcSlaveId INT NOT NULL, -- 源单号,即手机订单表的sid
dProductPQty INT NOT NULL, -- 产品数量
FOREIGN KEY (sSrcSlaveId) REFERENCES phone_orders(sid) ON DELETE CASCADE
);这里,我们为work_orders表的sSrcSlaveId字段设置了外键约束,以确保它引用的是phone_orders表中存在的sid。使用ON DELETE CASCADE选项意味着当删除一个手机订单时,与该订单相关联的所有工单也会被自动删除。
3. 模拟基础数据
首先,向手机订单表中插入一些数据:
INSERT INTO phone_orders (sid, phone_name, phone_quantity) VALUES
(1, 'iPhone 13', 0),
(2, 'Galaxy S22', 0),
(3, 'Pixel 6', 0);然后,向工单表中插入与手机订单相关联的数据:
INSERT INTO work_orders (sid, sSrcSlaveId, dProductPQty) VALUES
(1, 1, 20), -- 对应phone_orders中sid为1的订单,产品数量为20
(2, 1, 30), -- 同一个订单的另一个工单,产品数量为30
(3, 2, 50), -- 对应phone_orders中sid为2的订单,产品数量为50这里的sid字段在两张表中都是唯一的,但在各自的表中可以重复。对于work_orders表,sSrcSlaveId字段对应于phone_orders表的sid,用于表示工单与哪个手机订单相关联。 手机订单的总数量为0,我们一般需要在生成工单的时候,去回填订单表的数量字段,这是很常见的需求。 尝试写sql如下:
update phone_orders A join (
SELECT sSrcSlaveId,SUM(dProductPQty) dProductPQty from work_orders GROUP BY sSrcSlaveId
) B on A.sid = B.sSrcSlaveId
set A.phone_quantity = B.dProductPQty
where A.sid = 1;基于您提供的SQL更新语句,这条语句的目的是更新phone_orders表中sid为1的记录,将其phone_quantity字段设置为与该订单相关联的所有工单的产品数量之和。
首先,我们来分析这条SQL语句的各个部分:
4.子查询:
SELECT sSrcSlaveId, SUM(dProductPQty) dProductPQty
FROM work_orders
GROUP BY sSrcSlaveId这个子查询从work_orders表中选取sSrcSlaveId(即源单号,对应于phone_orders表的sid)和每个源单号对应的所有工单的产品数量之和(通过SUM(dProductPQty)计算)。结果集包含两列:sSrcSlaveId和计算后的产品数量dProductPQty。
5.JOIN操作:
UPDATE phone_orders A
JOIN (
...子查询...
) B
ON A.sid = B.sSrcSlaveId这里使用了JOIN操作来连接phone_orders表(别名为A)和子查询的结果集(别名为B)。连接条件是A.sid = B.sSrcSlaveId,即phone_orders表的唯一键sid与子查询结果集中的sSrcSlaveId相匹配。
6.SET操作:
SET A.phone_quantity = B.dProductPQty此部分将phone_orders表(别名为A)中的phone_quantity字段更新为子查询结果集(别名为B)中对应的dProductPQty值。
7.WHERE条件:
WHERE A.sid = 1这个条件限制了更新的范围,只更新phone_orders表中sid为1的记录。
这条SQL语句的作用是:找出所有与phone_orders表中sid为1的订单相关联的工单,计算这些工单的产品数量之和,然后将phone_orders表中sid为1的记录的phone_quantity字段更新为这个总和。
执行后得到结果:
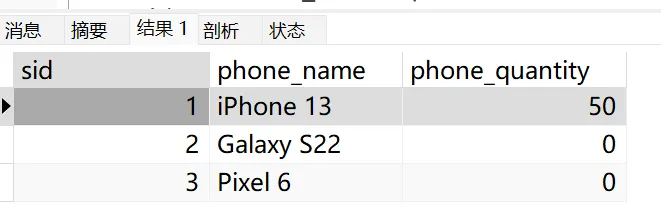
思考题
上面的例子,如果我们换成left join,并且去查询A.sid = 3会发生什么?
update phone_orders A left join (
SELECT sSrcSlaveId,SUM(dProductPQty) dProductPQty from work_orders GROUP BY sSrcSlaveId
) B on A.sid = B.sSrcSlaveId
set A.phone_quantity = B.dProductPQty
where A.sid = 3;