













译者 | 李睿
审校 | 重楼
如今,人们对能够使大型语言模型(LLM)在很少或没有人为干预的情况下改进功能的技术越来越感兴趣。大型语言模型(LLM)自我改进的领域之一是指令微调(IFT),也就是让大型语言模型教会自己遵循人类指令。

指令微调(IFT)是ChatGPT和Claude等大型语言模型(LLM)获得成功的一个主要原因。然而,指令微调(IFT)是一个复杂的过程,需要耗费大量的时间和人力。Meta公司和纽约大学的研究人员在共同发表的一篇论文中介绍了一种名为“自我奖励语言模型”的新技术,这种技术提供了一种方法,使预训练的语言模型能够创建和评估示例,从而教会自己进行微调。
这种方法的优点是,当多次应用时,它会继续改进语言模型。自我奖励语言模型不仅提高了它们的指令遵循能力,而且在奖励建模方面也做得更好。
自我奖励的语言模型
对大型语言模型(LLM)进行微调以适应指令遵循的常用方法是基于人类反馈强化学习(RLHF)。
在人类反馈强化学习(RLHF)中,语言模型根据从奖励模型收到的反馈来学习优化其反应。奖励模型是根据人类注释者的反馈进行训练的,这有助于使语言模型的响应与人类的偏好保持一致。人类反馈强化学习(RLHF)包括三个阶段:预训练大型语言模型(LLM),创建基于人类排名输出的奖励模型,以及强化学习循环,其中大型语言模型(LLM)根据奖励模型的分数进行微调,以生成与人类判断一致的高质量文本。
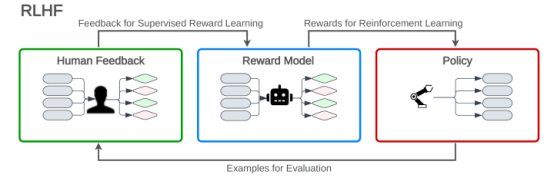 图1人类反馈强化学习(RLHF)
图1人类反馈强化学习(RLHF)
另一种方法是直接偏好优化(DPO),在这种方法中,语言模型可以生成多个答案,并从人类那里接收直接反馈得知哪一个答案更可取。在直接偏好优化(DPO)中,不需要创建单独的奖励模型。
虽然这些技术已被证明是有效的,但它们都受到人类偏好数据的大小和质量的限制。人类反馈强化学习(RLHF)具有额外的限制,即一旦训练完成,奖励模型就会被冻结,其质量在大型语言模型(LLM)的整个微调过程中都不会改变。
自我奖励语言模型(SRLM)的思想是创建一种克服这些限制的训练算法。研究人员在论文中写道:“这种方法的关键是开发一个拥有训练过程中所需的所有能力的代理,而不是将它们分成不同的模型,例如奖励模型和语言模型。”
自我奖励语言模型(SRLM)有两个主要功能:首先,它可以对用户的指令提供有益且无害的响应。其次,它可以创建和评估指令和候选响应的示例。
这使得它能够在人工智能反馈(AIF)上迭代训练自己,并通过创建和训练自己的数据来逐步改进。
在每次迭代中,大型语言模型(LLM)在遵循指令方面变得更好。因此,它在为下一轮训练创建示例方面也有所改进。
自我奖励语言模型(SRLM)的工作原理
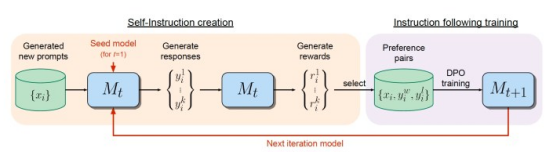 图2自我奖励语言模型(SRLM)创建自己的训练示例并对其进行评估
图2自我奖励语言模型(SRLM)创建自己的训练示例并对其进行评估
自我奖励的语言模型从在大量文本语料库上训练的一个基础大型语言模型(LLM)开始。然后,该模型在一小部分人类注释的示例上进行微调。其种子数据包括指令微调(IFT)示例,其中包括成对的指令和响应对。
为了改进结果,种子数据还可以包括评估微调(EFT)示例。在评估微调(EFT)中,为大型语言模型(LLM)提供一条指令和一组响应。它必须根据响应与输入提示的相关性对响应进行排序。评估结果由推理描述和最终分数组成,这些例子使大型语言模型(LLM)能够发挥奖励模型的作用。
一旦在初始数据集上进行了训练,该模型就可以为下一次训练迭代生成数据。在这个阶段,模型从原始的指令微调(IFT)数据集中采样示例,并生成一个新的指令提示符。然后,它为新创建的提示生成几个候选响应。
最后,该模型采用LLM-as-a-Judge对响应进行评估。LLM-as-a-Judge需要一个特殊的提示,包括原始请求、候选人回复和评估回复的说明。
 图3 LLM-as-a-judge提示
图3 LLM-as-a-judge提示
一旦模型创建了指令示例并对响应进行了排序,自我奖励语言模型(SRLM)就会使用它们来创建人工智能反馈训练(AIFT)数据集,也可以使用这些说明以及回答和排名分数来创建偏好数据集。有两种方法可以组装训练数据集。一个是该数据集可以与直接偏好优化(DPO)一起使用,以教会语言模型区分好响应和坏响应。另一个是可以创建一个仅包含最高排名响应的监督微调(SFT)数据集。研究人员发现,加入排名数据可以提高训练模型的性能。
一旦新创建的示例被添加到原始数据集中,就可以再次训练模型。这个过程将重复多次,每次循环都会创建一个模型,该模型既能更好地遵循指示又能更好地评估响应。
研究人员写道:“重要的是,由于该模型既可以提高其生成能力,又可以通过相同的生成机制作为自己的奖励模型,这意味着奖励模型本身可以通过这些迭代得到改进。我们相信,这可以提高这些学习模式未来自我完善的潜力上限,消除了制约瓶颈。”
实验自我奖励语言模型(SRLM)
研究人员以Llama-2-70B为基础模型测试了自我奖励语言模型。作为指令微调的种子数据,他们使用了包含数千个指令微调示例的Open Assistant数据集。Open Assistant还提供了具有多个排序响应的指令示例,这些指令可用于评估微调(EFT)。
他们的实验表明,自我奖励语言建模的每一次迭代都提高了大型语言模型(LLM)遵循指令的能力。此外,大型语言模型(LLM)在奖励建模方面变得更好,这反过来又使它能够为下一次迭代创建更好的训练示例。他们在AlpacaEval基准测试上的测试表明,三次迭代自我奖励语言模型(SRLM)的Llama-2表现优于Claude 2、Gemini Pro和GPT-4.0613。
但是,这种方法也有局限性。像其他允许大型语言模型(LLM)自我改进的技术一样自我奖励语言模型(SRLM)可能导致模型陷入“奖励黑客”陷阱,在这个陷阱中,它开始优化响应以获得所需的输出,但其原因是错误的。奖励黑客攻击可能导致不稳定的语言模型在现实世界的应用程序和不同于其训练示例的情况下表现不佳。也不清楚这个过程可以在多大程度上根据模型大小和迭代次数进行缩放。
但是自我奖励语言模型(SRLM)具有明显的优势,可以为训练数据提供更多信息。如果已经有一个带注释的训练示例的数据集,那么可以使用自我奖励语言模型(SRLM)来提高大型语言模型(LLM)的能力,而无需向数据集添加更多示例。
研究人员写道:“我们相信这是一个令人兴奋的研究方向,因为这意味着该模型能够在未来的迭代中更好地为改进指令遵循分配奖励——这是一种良性循环。虽然这种改进在现实情况下可能会饱和,但它仍然允许持续改进的可能性,而人类的偏好通常用于建立奖励模型和指令遵循模型。”
原文标题:How language models can teach themselves to follow instructions,作者:Ben Dickson





























