













广阔的战场,风暴兵在奔跑……

prompt:Wide shot of battlefield, stormtroopers running...
这段长达 1200 帧的 2 分钟视频来自一个文生视频(text-to-video)模型,尽管 AI 生成的痕迹依然浓重,但我们必须承认,其中的人物和场景具有相当不错的一致性。
这是如何办到的呢?要知道,虽然近些年文生视频技术的生成质量和文本对齐质量都已经相当出色,但大多数现有方法都聚焦于生成短视频(通常是 16 或 24 帧长度)。然而,适用于短视频的现有方法通常无法用于长视频(≥ 64 帧)。
即使是生成短序列,通常也需要成本高昂的训练,比如训练步数超过 260K,批大小超过 4500。如果不在更长的视频上进行训练,通过短视频生成器来制作长视频,得到的长视频通常质量不佳。而现有的自回归方法(通过使用短视频后几帧生成新的短视频,进而合成长视频)也存在场景切换不一致等一些问题。
为了克服现有方法的缺点和局限,Picsart AI Resarch 等多个机构联合提出了一种新的文生视频方法:StreamingT2V。这也是一种自回归方法,并配备了长短期记忆模块,进而可以生成具有时间一致性的长视频。

- 论文标题:StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text
- 论文地址:https://arxiv.org/abs/2403.14773
- 项目地址:https://streamingt2v.github.io/
如下是一段 600 帧 1 分钟的视频生成结果,可以看到蜜蜂和花朵都有非常出色的一致性:
为此,该团队提出了条件注意力模块(CAM)。得益于其注意力性质,它可以有效地借用之前帧的内容信息来生成新的帧,同时还不会让之前帧的结构 / 形状限制新帧中的运动情况。
而为了解决生成的视频中人与物外观变化的问题,该团队又提出了外观保留模块(APM):其可从一张初始图像(锚帧)提取对象或全局场景的外观信息,并使用该信息调节所有视频块的视频生成过程。
为了进一步提升长视频生成的质量和分辨率,该团队针对自回归生成任务对一个视频增强模型进行了改进。为此,该团队选择了一个高分辨率文生视频模型并使用了 SDEdit 方法来提升连续 24 帧(其中有 8 帧重叠帧)视频块的质量。
为了使视频块增强过渡变得平滑,他们还设计了一种随机混合方法,能以无缝方式混合重叠的增强过的视频块。
方法
首先,生成 5 秒时长的 256 × 256 分辨率的视频(16fps),然后将其增强至更高的分辨率(720 × 720)。图 2 展示了其完整的工作流程。
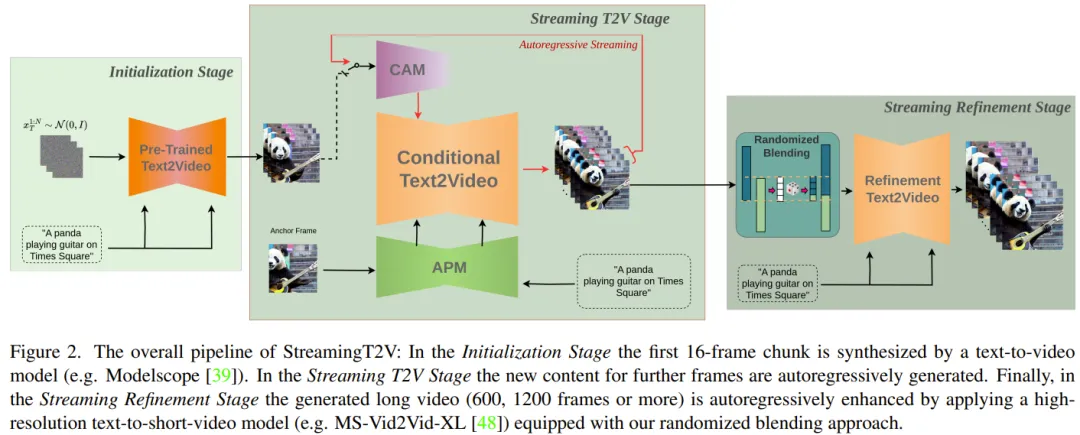
长视频生成部分由初始化阶段(Initialization Stage)和流式文生视频阶段(Streaming T2V Stage)构成。
其中,初始化阶段是使用一个预训练的文生视频模型(比如可以使用 Modelscope)来生成第一个 16 帧的视频块;而流式文生视频阶段则是以自回归方式生成后续帧的新内容。
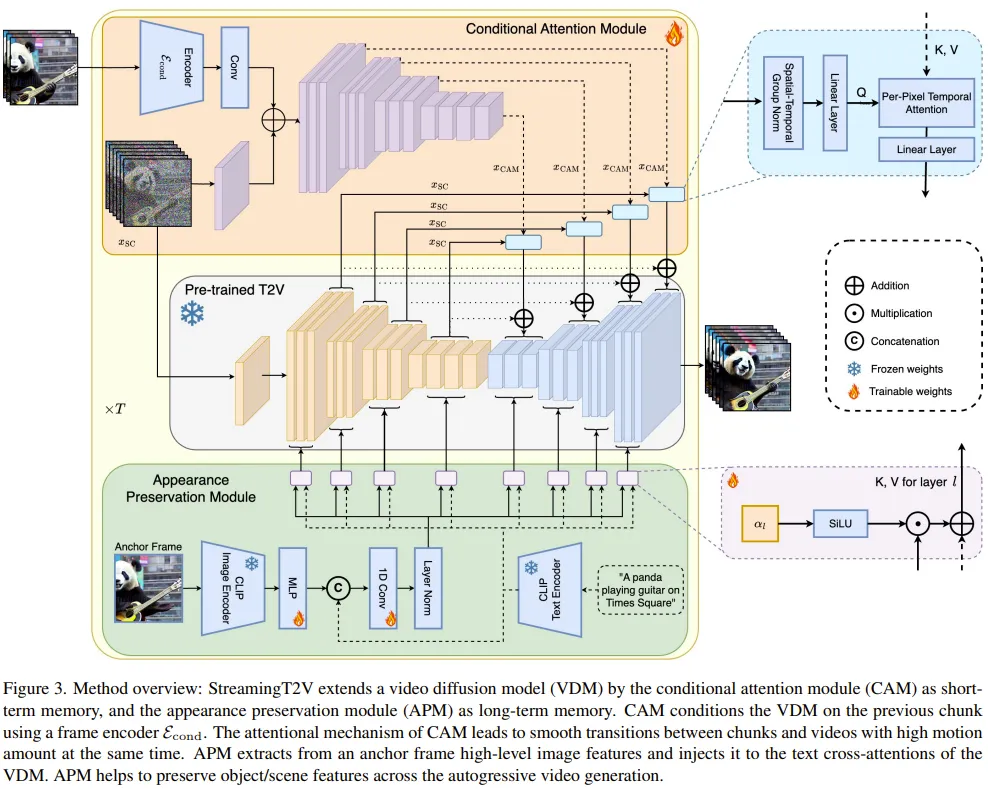
对于自回归过程(见图 3),该团队新提出的 CAM 可以利用之前视频块最后 8 帧的短期信息,实现块之间的无缝切换。另外,他们还会使用新提出的 APM 模块来提取一张固定锚帧的长期信息,使自回归过程能稳健地应对事物和场景细节在生成过程中的变化。
在生成得到了长视频(80、240、600、1200 或更多帧)之后,他们再通过流式优化阶段(Streaming Refinement Stage)来提升视频质量。这个过程会以自回归方式使用一个高分辨率文生短视频模型(如可使用 MS-Vid2Vid-XL),再搭配上新提出的用于无缝视频块处理的随机混合方法。而且后一步无需额外的训练,这使得该方法无需较高的计算成本。
条件注意力模块
首先,将所使用的预训练文生(短)视频模型记为 Video-LDM。注意力模块(CAM)的构成是一个特征提取器、一个向 Video-LDM UNet 注入的特征注入器。
其中特征提取器使用了逐帧的图像编码器,之后是与 Video-LDM UNet 直到中间层一直使用的一样的编码器层(并通过 UNet 的权重初始化)。
对于特征注入,这里的设计则是让 UNet 中的每个长程跳跃连接通过交叉注意力关注 CAM 生成的相应特征。
外观保留模块
APM 模块可通过使用固定锚帧中的信息来将长期记忆整合进视频生成过程中。这有助于维持视频块生成过程中的场景和对象特征。
为了让 APM 能平衡处理锚帧和文本指令给出的引导信息,该团队做出了两点改进:(1)将锚帧的 CLIP 图像 token 与文本指令的 CLIP 文本 token 混合起来;(2)为每个交叉注意力层引入了一个权重来使用交叉注意力。
自回归视频增强
为了自回归地增强 24 帧的生成视频块,这里使用的是高分辨率(1280x720)的文生(短)视频模型(Refiner Video-LDM,见图 3)。这个过程的做法是首先向输入视频块加入大量噪声,然后再使用这个文生视频扩散模型来进行去噪处理。
不过,这种方法不足以解决视频块之间的过渡不匹配的问题。
为此,该团队的解决方案是随机混合方法。具体详情请参阅原论文。
实验
在实验中,该团队使用的评估指标包括:用于评估时间一致性的 SCuts 分数、用于评估运动量和扭变误差的运动感知扭变误差(MAWE)、用于评估文本对齐质量的 CLIP 文本图像相似度分数(CLIP)、美学分数(AE)。
消融研究
为了评估各种新组件的有效性,该团队从验证集中随机采样 75 个 prompt 执行了消融研究。
用于条件处理的 CAM:CAM 能帮助模型生成更一致的视频,其 SCuts 分数比相比较的其它基线模型低 88%。
长期记忆:图 6 表明长期记忆能在自回归生成过程中极大帮助维持对象和场景的特征稳定。

在一个定量评估指标(人再识别分数)上,APM 实现了 20% 的提升。
用于视频增强的随机混合:与其它两个基准相比,随机混合能带来显著的质量提升,从图 4 中也能看到:StreamingT2V 可以得到更平滑的过渡。

StreamingT2V 对比基线模型
该团队通过定量和定性评估比较了集成上述改进的 StreamingT2V 与多种模型,包括使用自回归方法的图像到视频方法 I2VGen-XL、SVD、DynamiCrafter-XL、SEINE,视频到视频方法 SparseControl,文本到长视频方法 FreeNoise。
定量评估:从表 8 可以看出,在测试集上的定量评估表明,StreamingT2V 在无缝视频块过渡和运动一致性方面的表现最佳。新方法的 MAWE 分数也显著优于其它所有方法 —— 甚至比第二好的 SEINE 低 50% 以上。SCuts 分数上也有类似表现。
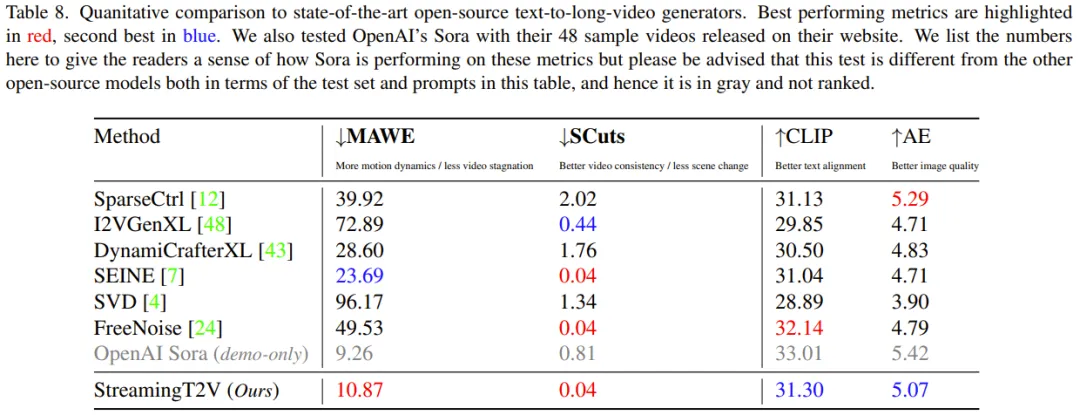
此外,在生成视频的单帧质量上,StreamingT2V 仅略逊于 SparseCtrl。这表明这个新方法能够生成高质量的长视频,并且比其它对比方法具有更好的时间一致性和运动动态。
定性评估:下图展示了 StreamingT2V 与其它方法的效果比较,可以看出新方法能在保证视频动态效果的同时维持更好的一致性。

更多研究细节,可参考原论文。























