文本标注工作是将标签或标记与文本的特定部分(如短语、单词或句子)相关联的过程。其目的是提供有关文本的额外信息,用于进一步的分析或处理,特别是在人工智能领域。

文本标注对于人工智能应用中的监督机器学习任务至关重要。用于训练AI模型,有助更准确地理解自然语言文本信息,提高文本分类、情感分析和语言翻译等任务的性能。通过文本标注,我们可以教AI模型识别文本中的实体、理解上下文,并在出现新的类似数据时做出准确的预测。
本文主要推荐一些较好的开源文本标注工具。
1.Label Studio
https://github.com/HumanSignal/label-studio

Label Studio是一个开源数据标注工具,支持各种数据类型并导出为多种模型格式。用于准备原始数据或增强现有的训练数据,以获得更准确的机器学习模型。
2.Doccano
https://github.com/doccano/doccano
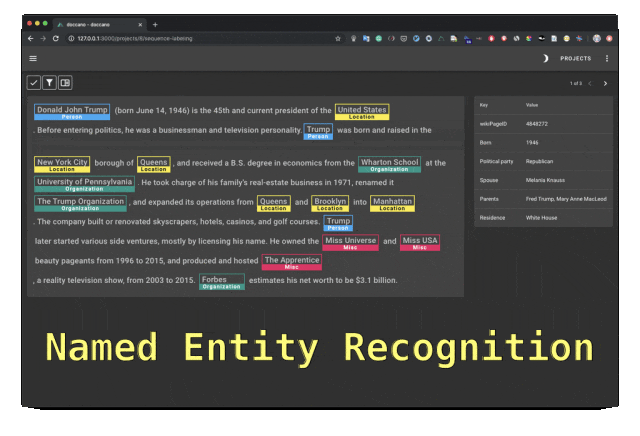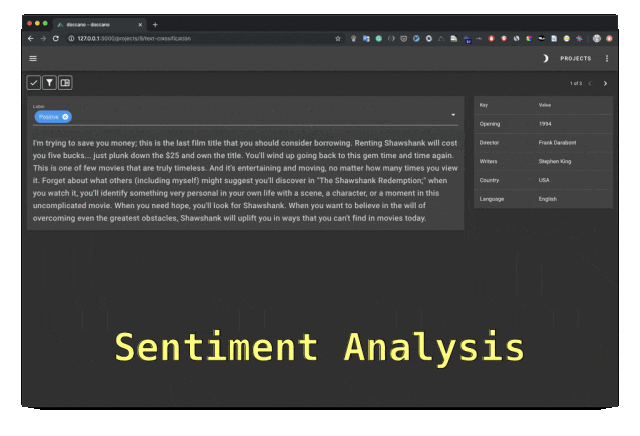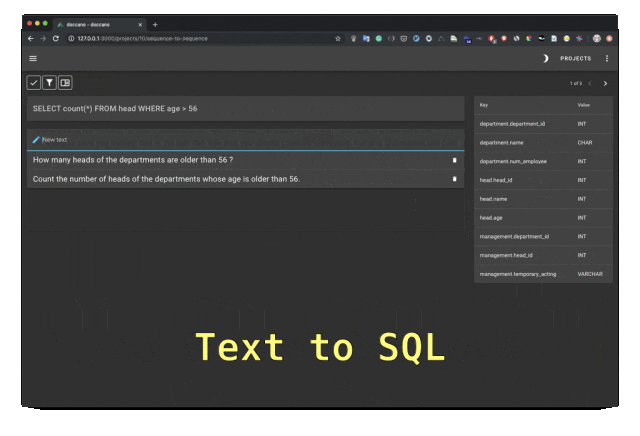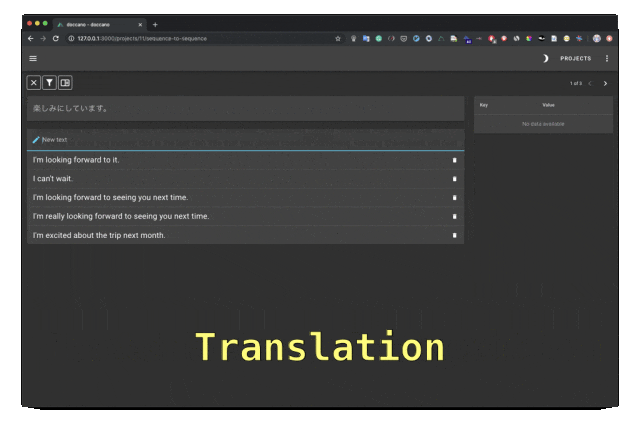
Doccano是一个开源文本标注工具,提供文本分类、序列标记和序列任务的功能。它支持文本标注团队协作、多语言、移动应用、表情符号、深色主题和REST风格的API。可以使用Docker和Docker Compose安装。
3.Universal Data Tool
https://github.com/UniversalDataTool/universal-data-tool
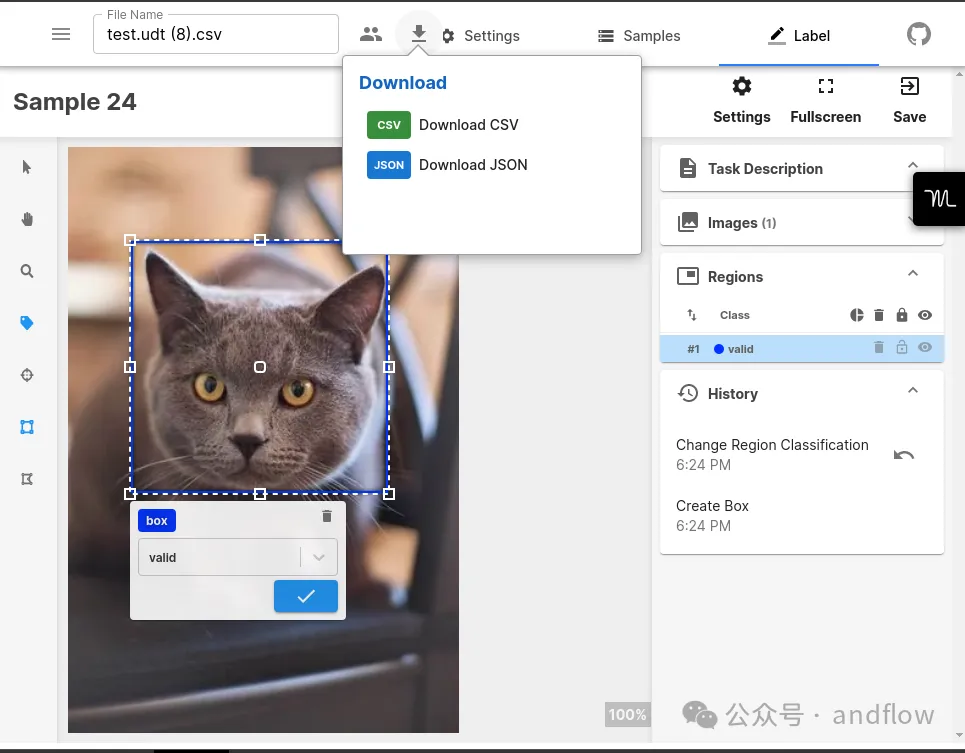
Universal Data Tool是一个用于编辑和注释各种类型的数据(包括图像、文本、音频和文档)的多功能应用程序。它支持广泛的数据类型,并提供实时协作、易于使用的GUI、为文本标注人员创建培训课程等功能。该工具可以在网络上使用,也可以作为桌面应用程序使用,并支持CSV或JSON格式的数据下载和上传。
4.YEDDA
https://github.com/jiesutd/YEDDA
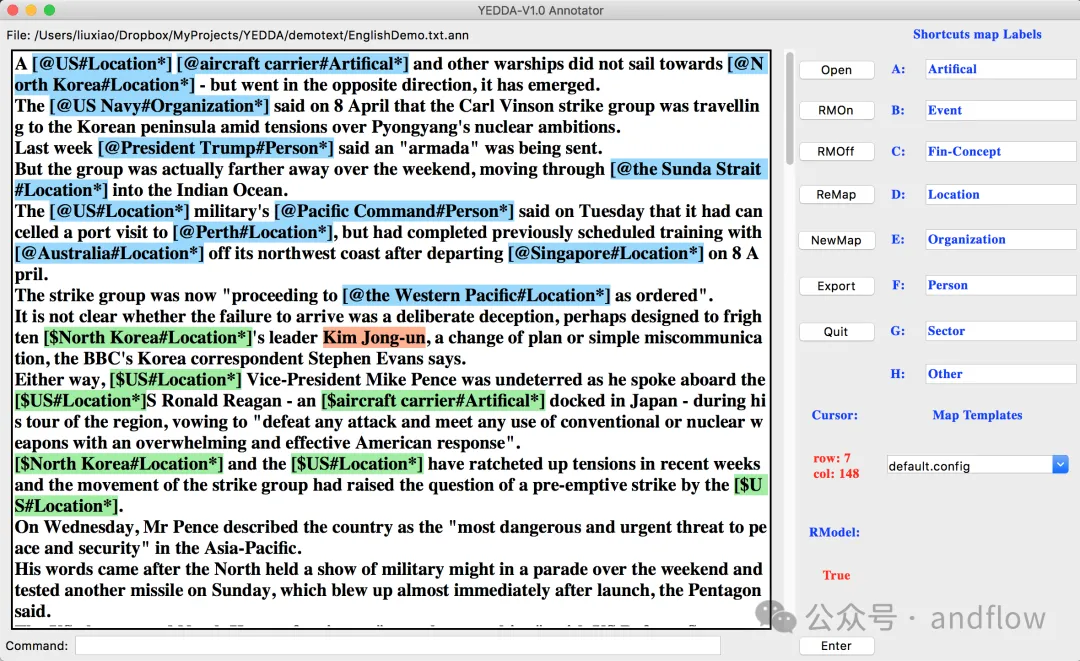
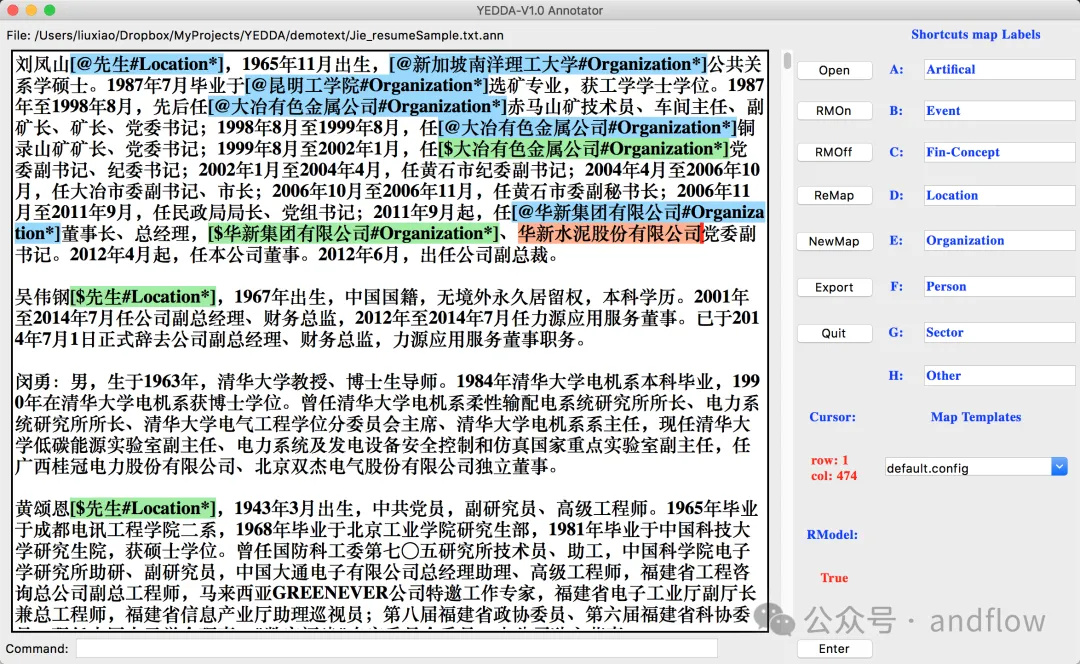
YEDDA是一个可以用于各种语言、符号和表情符号的文本标注工具。它支持使用快捷方式、命令模型,并将标注文本导出为序列文本。支持智能推荐和管理员分析等功能。
YEDDA兼容所有主流操作系统,包括Windows、Linux和MacOS。
5.Argilla
https://github.com/argilla-io/argilla
Argilla是一个面向人工智能工程师和领域专家的开源数据协作平台,提供高质量、高效率的数据输出。
它有助于控制数据质量并提高AI输出质量,并通过实现数据和模型的快速迭代来提高效率。Argilla还提供了数据管理和模型训练工具。
6.KernAI Refinery
https://github.com/code-kern-ai/refinery
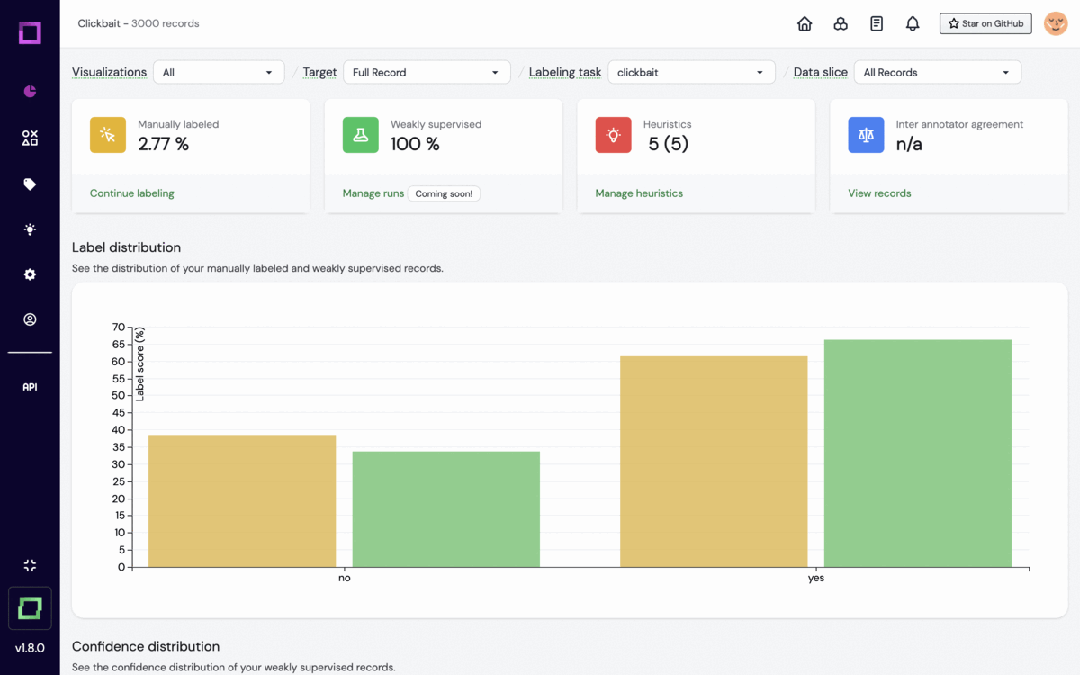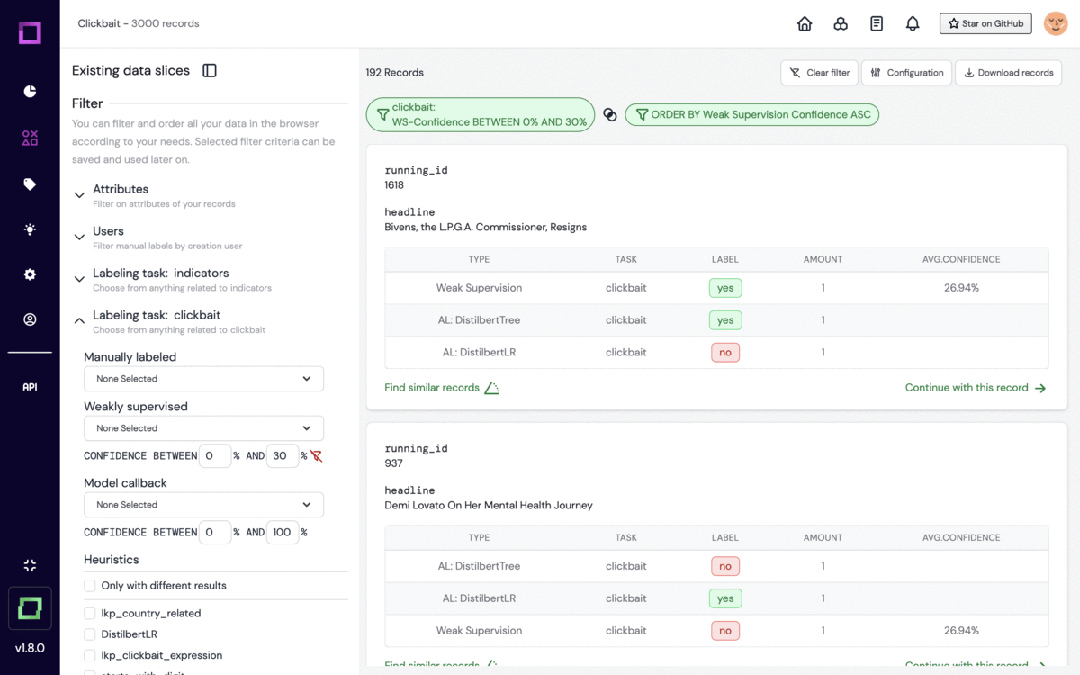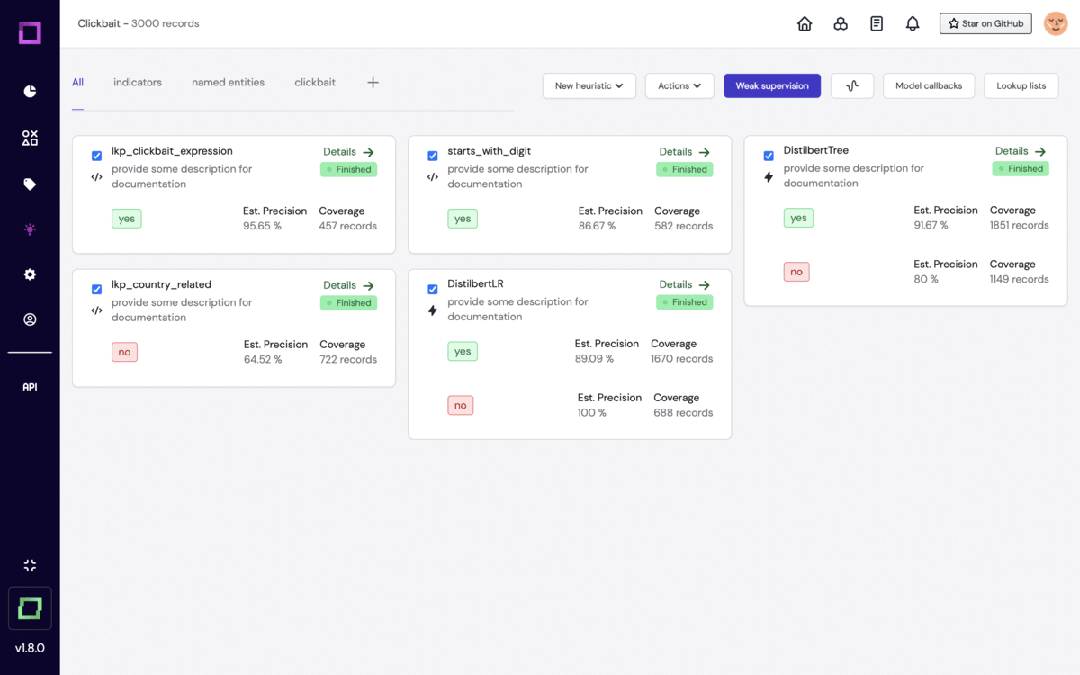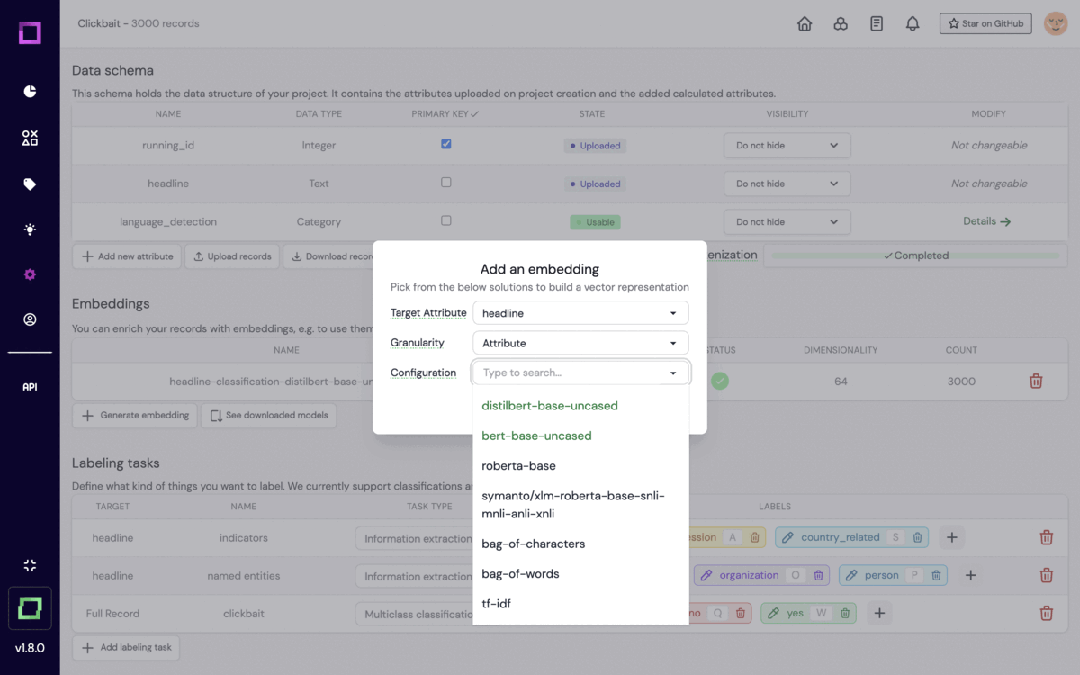
Refinery是KernAI的一个开源平台,专为处理自然语言数据的数据科学家设计。它提供半自动化数据标注、数据子集质量评估和集中数据监控等功能,旨在提高人工标记效率。
该工具利用Hugging Face和spaCy等技术构建预建语言模型,并与其他标签工具集成,以实现灵活的数据处理。
功能特征:
- NLP任务的(半)自动化标签工作流程
- 手动和程序化分类以及跨度标签
- 支持与最先进的库和框架集成
- 创建和管理查找表/知识库
- 基于神经搜索的相似记录和离群值检索
- 可切片标签会话
- 每个项目多个标签任务
- 丰富的自动化库
- 广泛的数据管理和监控
- 与Hugging Face集成,用于自动创建嵌入
- 基于JSON的数据模型用于数据上传/下载
- 项目指标概述
- 通过Python SDK访问和扩展数据
- 在位属性修改
- 托管版本中的团队协作
- 面向多个用户的基于角色的访问和最小化的标签视图
- 集成群组标签工作流
- 自动计算注释者之间的协
7.Recogito.js
https://github.com/recogito/recogito-js
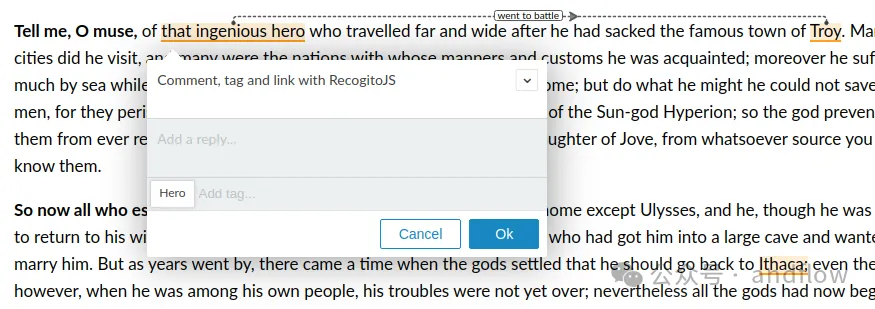
ApplitoJS是一个用于文本注释的JavaScript库,用于向网页添加文本标注功能或构建自定义文本标注程序。可以通过npm或下载最新版本来安装。
8.Label Sleuth
https://github.com/label-sleuth/label-sleuth

Label Sleuth是一个用于文本标注和分类的开源、无代码系统。它使医生、律师、心理学家等领域的专家也能够在没有NLP专家配合的情况下构建自定义NLP模型。
通常NLP模型创建需要领域和机器学习专业知识。Label Sleuth通过直观的文本标注和AI模型构建,绕开了对NLP专业知识的要求。当用户在标注数据时,机器学习模型在后台进行训练,进行预测并建议下一步标记什么。
作为一个无代码系统,它不需要机器学习知识,并允许快速开发模型,从任务定义到完成模型只需几个小时。
9.Markup
https://github.com/samueldobbie/markup
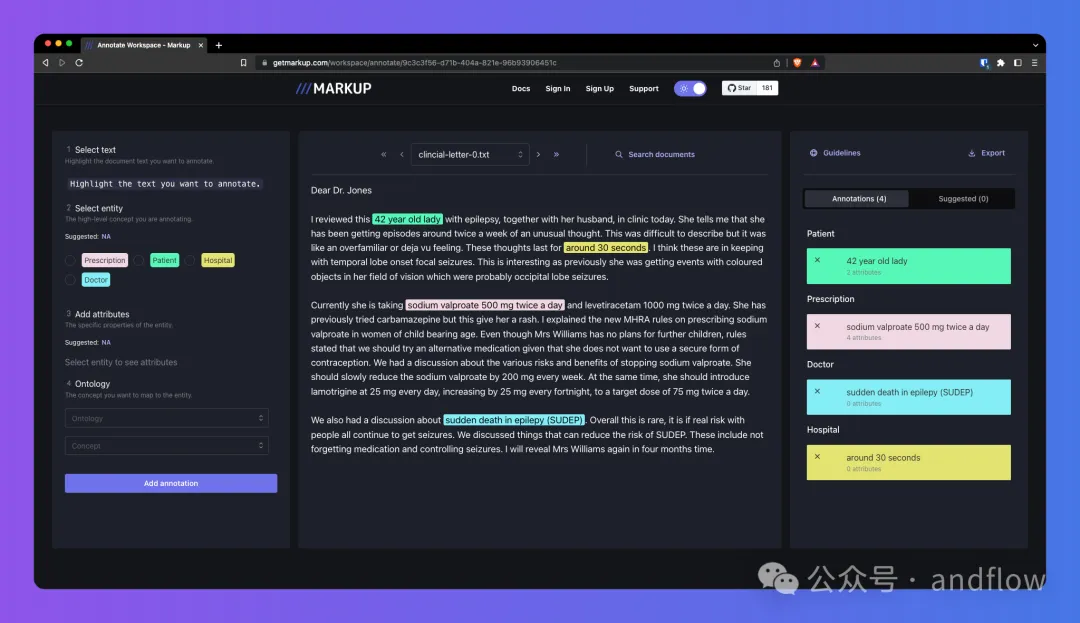
Markup是一种在线标注工具,可用于将非结构化文档转换为NLP和ML任务的结构化格式,例如:实体识别。在您标注时进行同步学习,以预测和推荐更为复杂的标注,并且还提供对用于概念映射的通用和自定义本体的集成访问。
功能特征:
- 预测性注释:Markup的机器学习驱动的预测性标注功能,可在您工作时推荐更复杂的标注,使标注的过程更加高效。
- 集成本体访问标记:提供了对广泛的通用本体(例如UMLS、SNOMED-CT、ICD-10)的集成访问,以及上传自定义本体的能力,用于概念映射。
- 预测性本体映射:Markup的预测性本体映射功能使用机器学习,根据您正在标注的文本,推荐到标准和自定义术语的适当映射。
- 友好的用户界面:无论您是技术专家还是初学者,标记的用户友好的界面使任何人都可以轻松地以最小的设置开始注释文档。
10.Potato
https://github.com/davidjurgens/potato
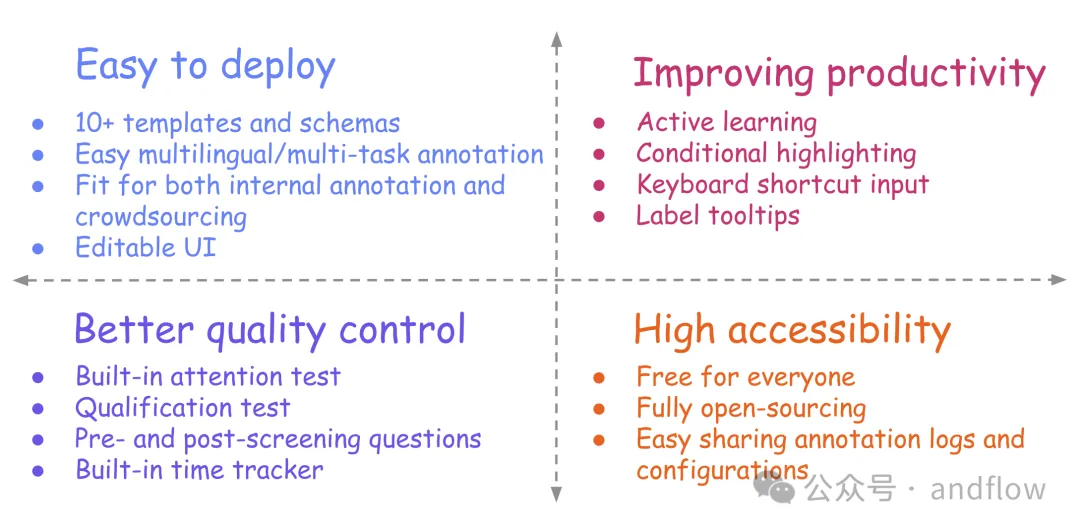
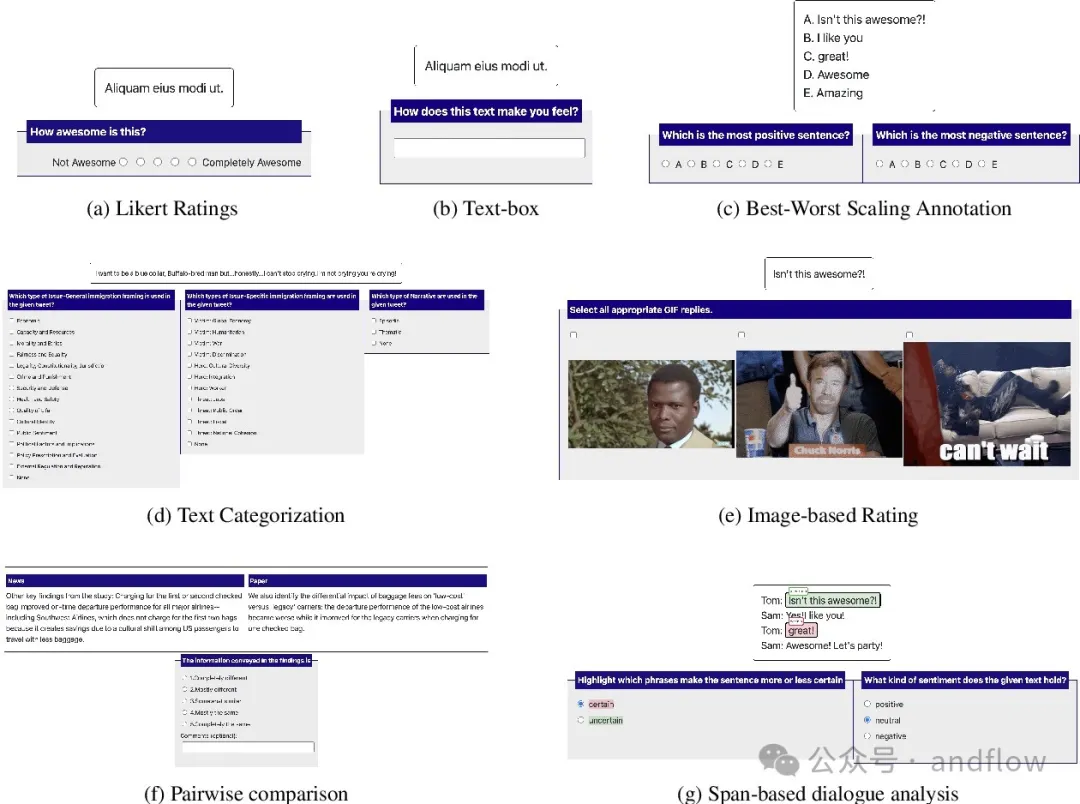
Potato是一个基于Web的文本标注工具,支持快速设置和部署各种文本标注任务。可以作为Web服务器运行,由单个配置文件驱动,不需要启动编码。但Potato很容易自定义,通常不需要额外的网页设计,就可以调整文本标注人员的操作界面。
关键特征:
- 易于设置和定制
- 广泛的内置模式和模板
- 支持多种数据类型
- 支持多任务设置
- 通过键盘快捷键、动态高亮显示和标签工具提示等功能提高标注效率
- 更好地了解注释者的功能,例如筛选前和筛选后的问题
- 质量控制功能,如注意力测试、资格测试和内置时间检查