














之前在做数据分析的时候,用过一个自动化生成数据探索报告的Python库:ydata_profiling。
一般我们在做数据处理前会进行数据探索,包括看统计分布、可视化图表、数据质量情况等,这个过程会消耗很多时间,可能需要上百行代码才能实现。
ydata_profiling能够直接完成数据探索的工作,只需要几行代码,它会生成互动网页形式的报告,里面包含数据概览、字段分布、统计学特征、相关性、缺失值、样本信息等。
# 导入库
from ydata_profiling import ProfileReport
import pandas as pd
# 读取数据
df = pd.read_csv('housing.csv')
# 自动生成数据探索报告
profile = ProfileReport(df, title="Profiling Report")
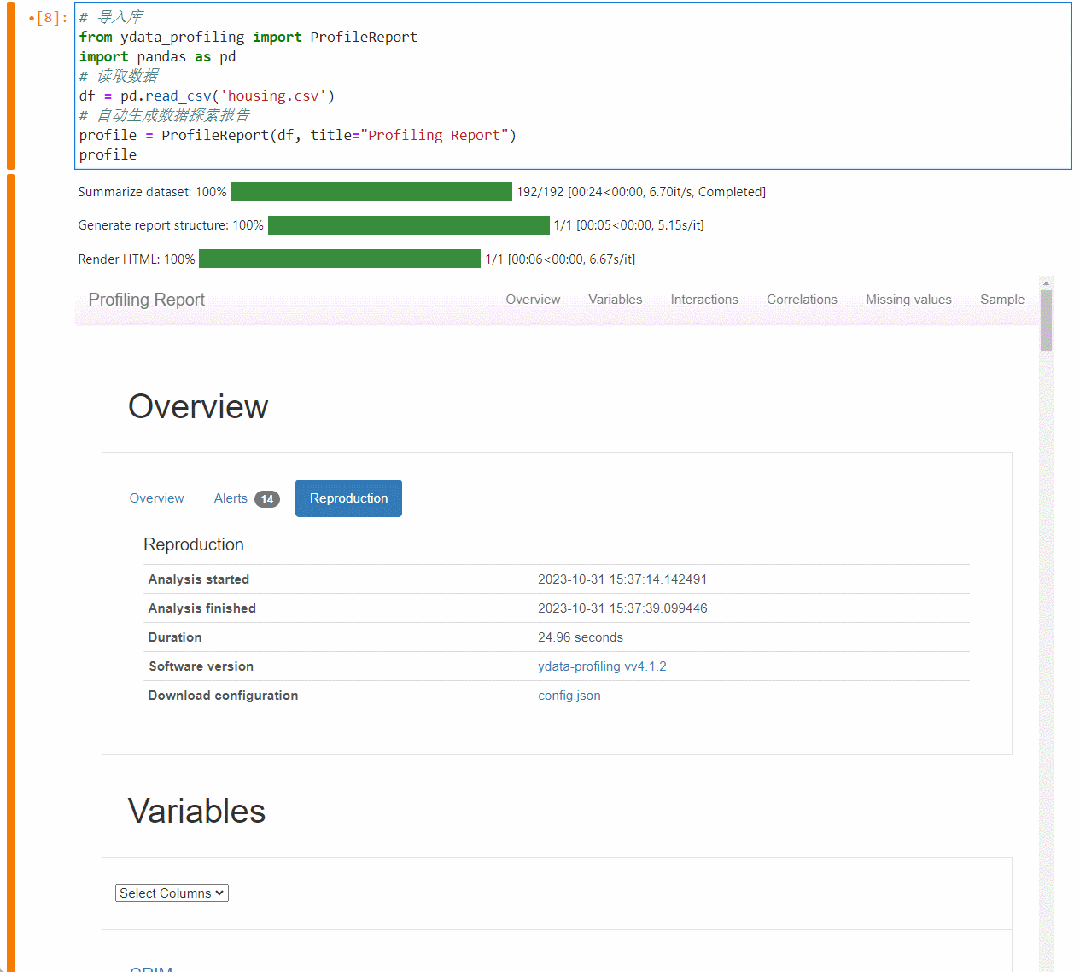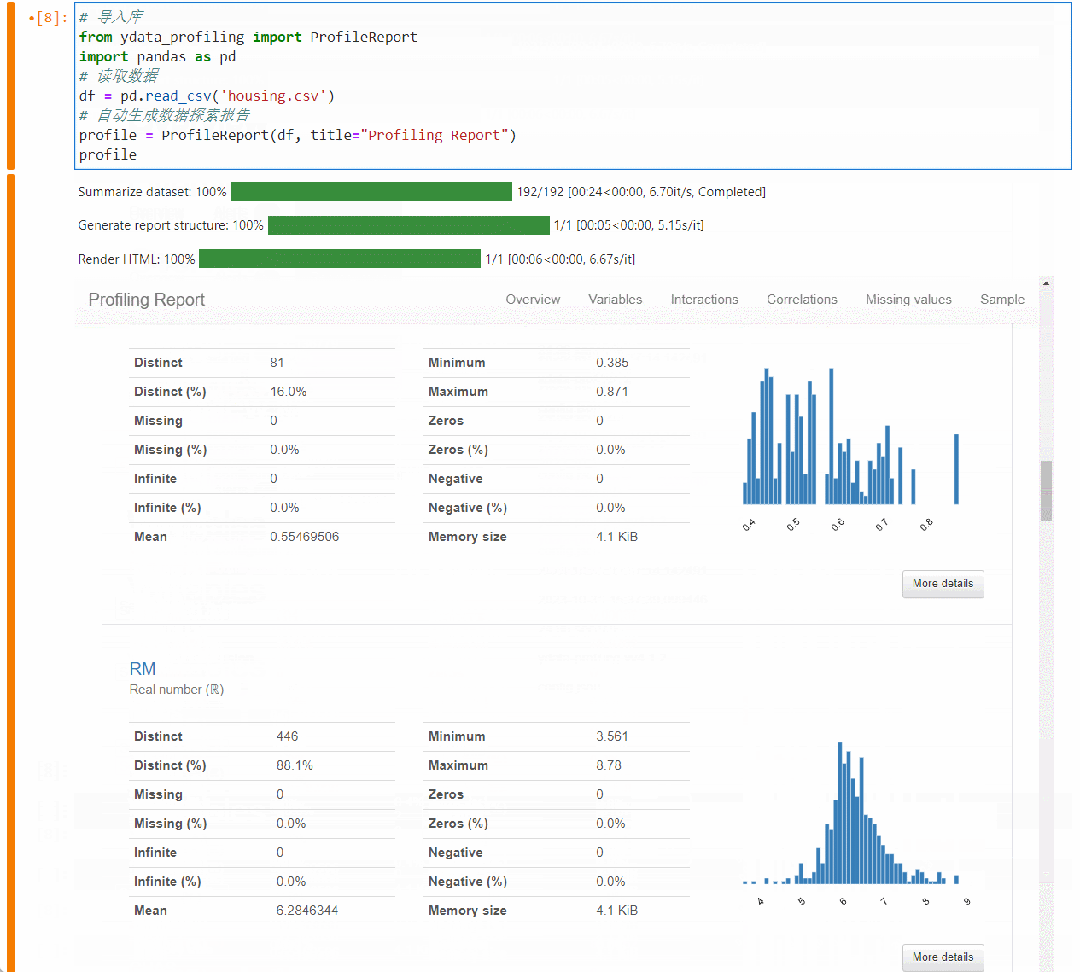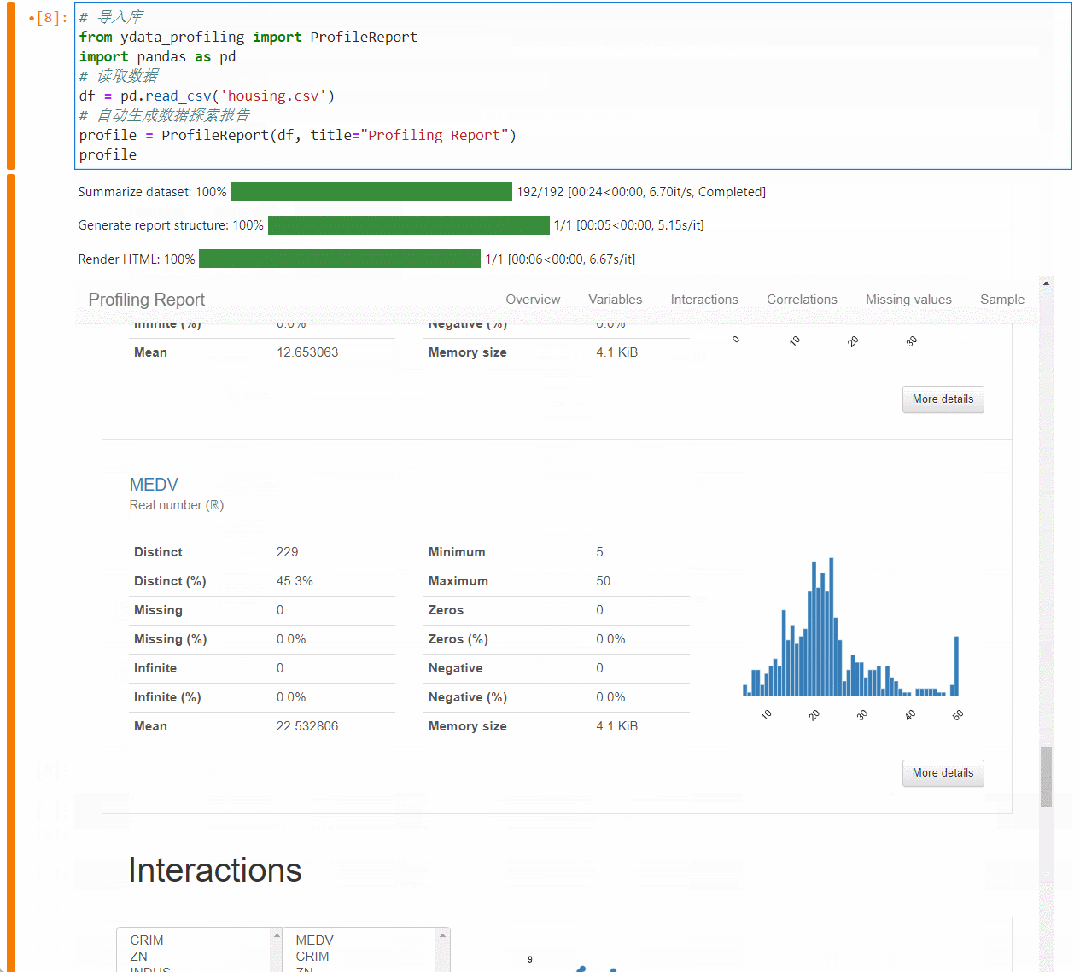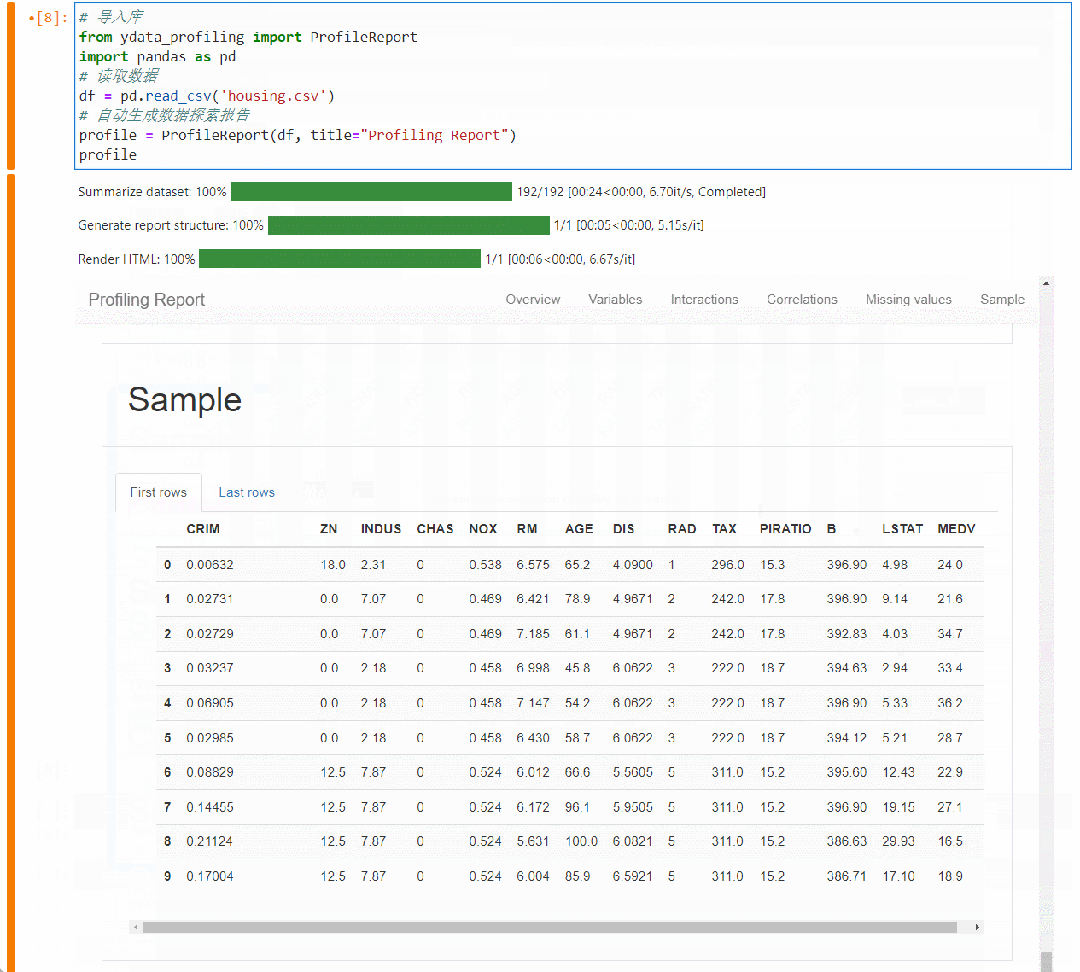
profile以上代码在Jupyter notebook中执行,生成数据探索报告如下:
ydata_profiling文档提了几个用途,我觉得还是比较实用的。
- 提供数据概览:包括广泛的统计数据和可视化图表,提供数据的整体视图。该报告可以作为html文件共享,也可以作为小部件集成在Jupyter笔记本中。
- 数据质量评估:识别缺失数据、重复数据和异常值。这些对于数据清理和准备很重要,确保分析的可靠性,并及早发现问题。
- 易于与其他流集成:数据分析的所有度量都可以以标准JSON格式使用。
- 大型数据集的数据探索:即使体量很大的数据集,ydata_profiling也可以轻松生成报告,它同时支持Pandas数据帧和Spark数据帧。
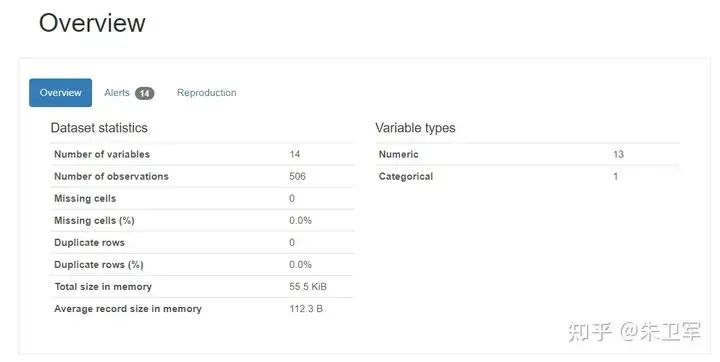
数据集概览 Overview
首先可以看到数据集的整体信息,包括字段数、缺失值行、重复行、占内存大小等等。
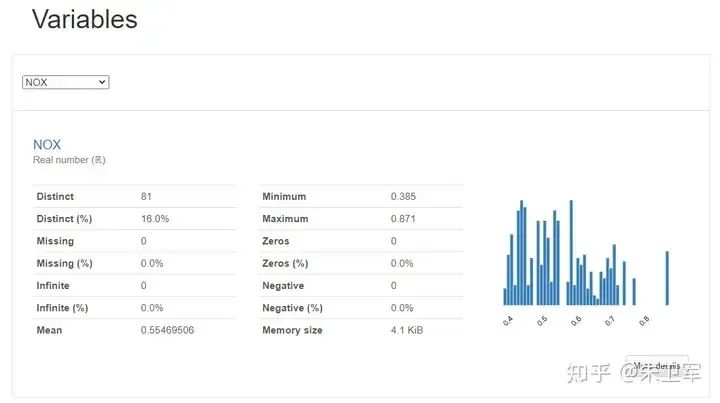
字段详细信息 Variables
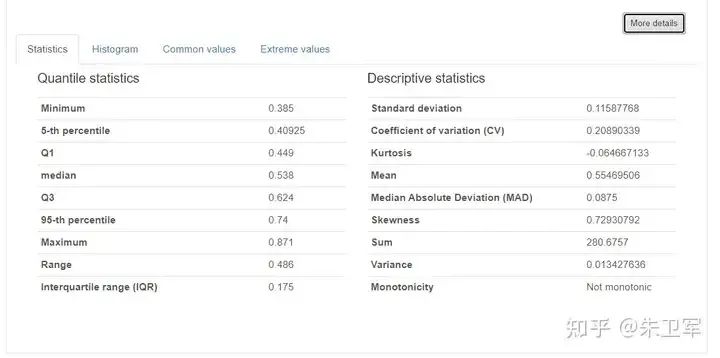
你可以看到所有字段的统计学特征以及分布情况,包括均值、分位值、最大最小值
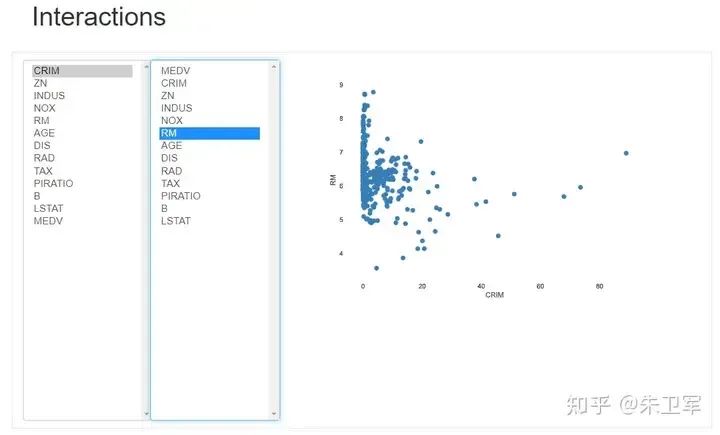
字段分布关系 Interactions
这是个交互可视化图,可以选择任意两个字段,看他们的散点分布关系,通过这个你可以很直观的知道各个字段的关联关系是什么样的,正相关、负相关、无相关等
字段相关性 Correations
这里通过热力图展示每个字段的相关性,也可以看到具体的值。
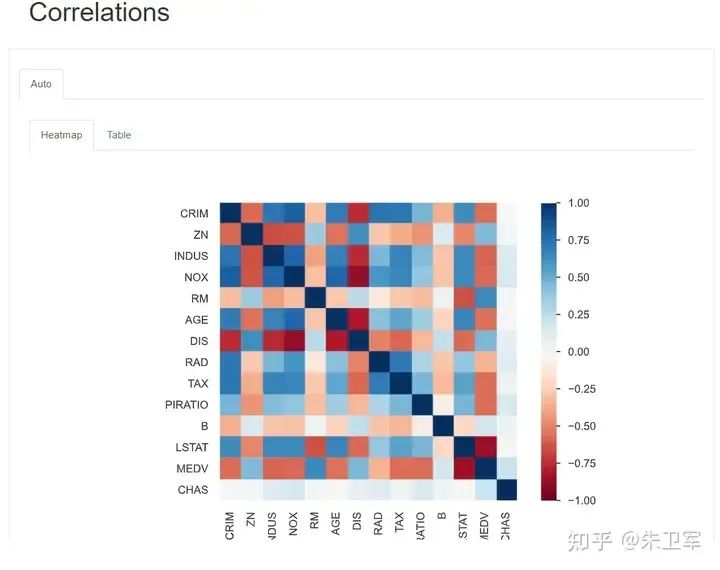
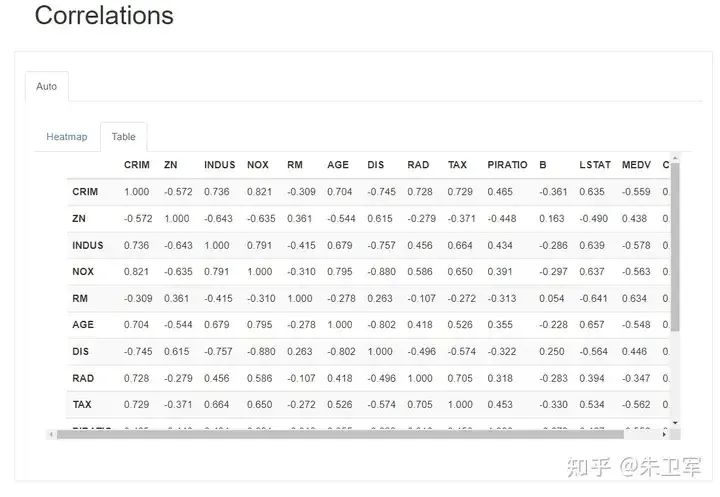
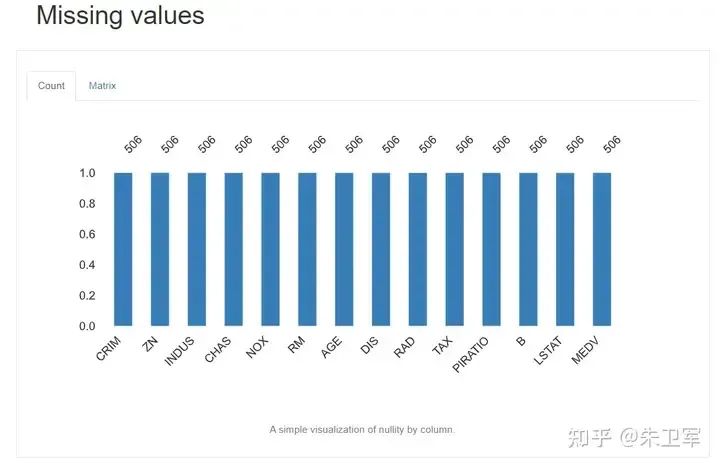
缺失值 Missing values
通过柱状图可以清晰看到每个字段缺失值情况。
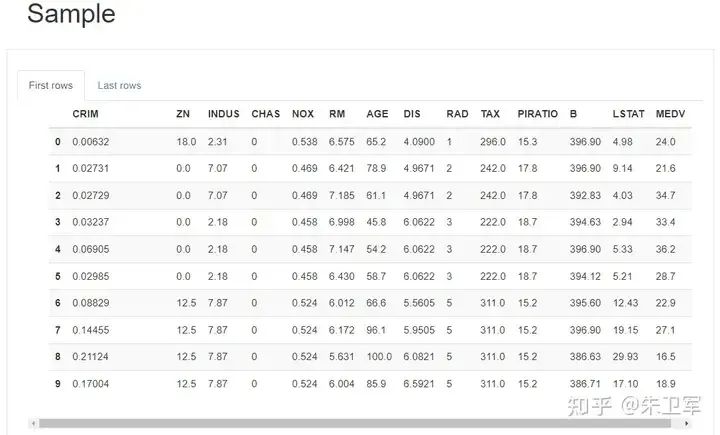
样本 Sample
可以展示前10、尾10的样本数据。
如果你想加快数据分析的速度,可以好好把ydata_profiling利用起来,前期数据探索阶段可以省很多时间。
























