MatrixOne 是一款面向未来的超融合异构云原生数据库管理系统。通过全新设计和研发的统一分布式数据库引擎,能够同时灵活支持 OLTP、OLAP、Streaming 等不同工作负载的数据管理和应用,用户可以在公有云、自建数据中心和边缘节点上无缝部署和运行。其优点包括:简单易用,成本较低,性能优异,灵活扩展。本文将对 MatrixOne 存储格式设计进行详细解读。
一、MatrixOne 存储格式设计的初衷
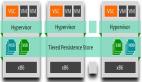
1. MatrixOne 架构解读

MatrixOne 整体架构分为三层,分别为:
计算层,设计为多节点结构,主要负责提取数据,完成计算功能。
中间层,事务处理与元数据层面、共享日志,主要功能是提供完整的日志服务以及元数据信息。
对接层,通过 File Service 对接底层各种不同的存储,比如 S3、用户的本地文件、NAS 等。
数据执行过程:
插入一条数据,系统接到请求后,这一条数据提交到事务处理层,之后系统将数据写到共享日志中,再返回给用户提示,表示操作成功。
有三点需要注意:
第一点:事务处理层(TN)刚开始写数据会比较小,系统会先在内存里面做组织结构,等积累到足够的量,比如几千行或 1 万行,再将这些数据落盘,落盘后的数据定义为一个 block。
第二点:刚开始用户写数据是比较小的,随着数据量的增长,系统会把数据都 MER merge 起来,然后不停地 merge,方便用户直接查数据,做分析。
第三点:遇到在写入数据过程中,操作多及数据量大的时候,系统会直接将数据写入 Database 或者写入 S3,写入完成后,通过发布 service,提交到系统后台。

如上图右边的结构,从上至下,第一层是 DB,第二层是 table,DB 和 table 存在元数据里,具体的数据分为多个 object,一个 object 又可以分为多个 block。
2. MatrixOne 存储格式设计的初衷

从 MatrixOne 0.5 开始,现在已经发布到 1.1,一直采用列存的结构,因为列存对 AP 容易优化,负载可以灵活适配;一个 Column 数据,和大多数数据库的 Hive 文件排列结构比较相似,每一个列有独立的 block,用户可以通过这些列来查询数据。
对于 MatrixOne 来说,需要满足所有的业务类型,比如数据库表的数据,table、DB、Catalog 的元数据管理、元数据落盘、再做 Replay。
业务数据在运行过程中,有很多 trace log、raw log,为了方便用户查看 log,也要对这些数据做足够的支撑。
遇到类似 AP 场景,有很大数据量的查询,查询结果后续可能还会调用,系统会把常用查询结果存储在本地文件或者是 S3 上,方便后续直接调用常用结果型数据。
为了满足所有的业务数据,不同的数据类型方便去访问,且不影响数据查询时效,采用 File Server 中的 S3 共享存储可以解决此问题。S3 的对象存储,每一个对象都需要存储指定的行,或者是指定 size,或者是指定的 block。block 有很多,存储一个对象可能会有多种类型的 block,可能 schema 都不一样,这些不同的 schema,需要哪些 block,需要用 block 的语言数据分析,之后更新 block 的源数据,才能得到真正的数据存放地址。这就是保证便捷高效的元数据请求访问的原理。
用户数据在正常运行一段时间之后,需要 scrub 任务来校验一下数据正确性,MatrixOne 提供了一些工具,来满足这些需求,帮助用户做数据维护。
3. 数据结构解析

结构图最上方 Header 会记录对象的版本信息、数据格式、元数据的位置、校验值位置,结构图最下方的 footer 是 head 的镜像。
结构图 Header 以下是数据区,写入的业务数据在内存打包处理后写到这个数据区,在数据区里将写入的数据称为一个 block,结构图再往下一层是整个对象的元数据区域。
首先是索引区域,比如现有的 feature 还有 Romec 都存在里面。
结构图最后一层是整个对象的 Meta 标记,包括整个对象怎么解析,怎么去读。
当用户写完数据成功后,系统会有一个 offset 指向整个 Meta data 区域。

Metadata 的结构如上图所示。
Tombstone 就是用户 data,用户写完后可能要删某一行,因为写入系统不能直接修改,需要删的那一行,系统会再记录一下,也就是软删。
SubMeta 会存储 catalog、block、object 等,用户读数据的时候,需要这些元数据,简称为 checkpoint。Checkpoint 存在 SubMeta 里面,有 20 多种。为了保障性能,用户要提取一套数据,系统只需要指针偏移,就可以去拿到对应的 Meta,记录这些 Meta 存在的位置,就需要 SubMetaIndex。
DataMeta、TombstoneMeta、SubMeta,每一个 Meta 都有 head 去记录整个 Meta 的信息。

Block 层结构如上图。
每个 block 有不同的值,整个数据的 Meta 的checkpoint、columncnt,rows或者 Bloom Fitter 这些索引,都记录在 supplement。还有一些 block 的 index 用来记录 block 的偏移,block 的数量不是固定的,所以系统要记录 index。否则如果先去读有多少 block,然后通过这些 block 去算需要的 block 具体在哪里,这样对整体性能要求很高,所以系统会记住 block index,记录固定的起止位置来标记 block 都在哪里,从而便于读取。

DBID、TableID、AccountID 等内容具体解释如上图所示。

ColumnMeta 记录第几列,当前列是什么 type;NDV 即 column 中有多少不同的值;NullCnt 记录的是这一列中有多少 null 值;DataExtent 记录的是数据位置,也会记录压缩前和压缩后的数据大小;Chksum 是数据的 checksum;ZoneMap 是指这列的 MinMax 索引,然后通过 index 当前寻找的偏行地址就可以读这个数据。

用户写完数据后,会返回一个记录对象 Meta 位置的 extent,并保存到 catalog 也就是 Metadata 当中。当用户使用系统去执行查询数据所需要去读数据的时候,可以通过这个 extent 去查询整个对象的 Meta,从而通过 Meta 一层一层去看到具体的 column data。
通过一个 extent,就可以去读取一个 IO,因为系统中一个对象里面最小的单位是 IO entry,根据不同的 IO 它可分成不同的 IO entry。比如一个 column data,column 是一列,就等于一个 IO,可以一列一列地读,或者一个 Meta,也是一个 IO,或者 bloomfilter,也是一个 IO,可以通过一个 IO 读出所有不同的 feed,方便过滤。
通过 IO entry,查询到这个对象的 Meta,然后查询真正的数据。通过 Meta 读数据,需要先查找数据的 head,然后得到 block index 就可以很方便地去获取到 block 的 Meta,每一列都在 block Meta 里面,包括如何方便地查询一些 column,可以看到 column Meta,column Meta 里面就记录着 data 的 extent,然后可以根据这些 IO 去读数据,能够很方便地获得真正想要的数据。
当遇到有些数据不常用到但也需要去分析时,用户决定读哪些数据,对应对象的Meta 就需要不停地去查,系统会将对象的 Meta 放在常驻缓存中,解决数据读取时效的问题。
二、性能的保证

需要访问的数据多种多样,包括元数据、Table data、索引、checkpoint 以及各种日志。为了保证低成本访问,需要做 metadata cache、index cache 等等。拿到数据后,需要高效地解析。

为了实现对元数据的高效解析,我们也做了很多尝试。比如采用 byte 的方式,放在内存里面也不需要序列化,直接去用就可以了。要去读哪些字段时,靠指针偏移即可完成。
数据写入的时候也很方便,set 一个 block ID,相当于通过 block ID 这个结构先做成 byte,可以直接拷贝,指针操作也很方便。
通过 Benchmark 做反序列化解析,只要拿到相应的 Meta data 的 ID,整个解析过程会比较快,是纳秒级别的速度。
三、数据兼容性和使⽤场景
1. 数据兼容性

兼容性也是个很重要的问题,比如客户已经用了一两年,有些优化需要修改数据格式,那么新的代码肯定要对以前的数据做好兼容。
我们的方案比较简单,每个 IO Entry 会在 Header 中标记 Data Type,type 会决定如何 encode 和 decode。Version 是 type 的版本。版本切换时,注册相应的 encode 和 decode 函数,读到相应的 IO Entry Header,选择对应的函数,解析数据,这样就可以实现兼容。

以上是结构图,IOEntryHeader 中记录着 Type 和 Version。Type 包括对象的 Meta,column data,还有 index 等等。用户写数据时,系统会注册一个 encode 函数,如果要写入对象的 Meta,对象 Meta 是版本 2,就会标记 type 为 type1,版本是 version2,后面就是要写入的 Meta的byte。
读的时候,先读到 header,因为系统去读 IO Entry 是把所有的东西都读上来,之后先拿前面两个字段,通过 header 去做解析。
从开始到现在,MatrixOne 的版本只变过三次,每个版本会有简洁的对应的函数,维护起来非常便捷。
2. 应用场景

系统有单独的 log service,其余所有的数据结构都使用这种结构-落盘读取,包括正常业务的读写 table 数据,查询或者插入等等。
支持 checkpoint、catalog。系统隔一段时间会打一个 checkpoint,记录增加了哪个 DB,DB 里面增加了几个 table,如果是落盘的数据,增加哪个对象,以及具体的对象数据的里面 block。启动的时候,系统会根据 checkpoint,replay 出来 catalog。用户可以根据 Catalog 去查询 DB 数据。
Metadata 扫描的主要功能是查看 scan 用户存了多少数据,存了多少表 DB,这些 DB 具体有多少个对象文件,对象到底都有多大,压缩前、压缩后分别是多大等等。Metadata 扫描会用到对象的 metadata,常驻在缓存里面,效率很高。
查询结果的 cache 的使用,在遇到比较大的查询分析时,比如一个查询分析要几秒,耗费计算资源比较多,系统会将这些结果都存在 cache 里。这样用户下次查询就不需要再重新去 load 那么多数据再重新计算。

四、问答环节
Q1:社区实现动态 catalog 会考虑任务修改?
A1:现在 Catalog 是通过 checkpoint 来做,问题已经得到解决,checkpoint 所有都是增量的,增量的所有的记录都会记录下来,增删改查或 DDL,这些东西都记录在 checkpoint 里面,只要 Replay 即可。Catalog 也是常驻在内存当中的,可以进行原子性的控制。
Q2:比如企业已有一个非常完善的,且有很多存量数据的集群,在这种情况下怎么使用 MatrixOne 呢?
A2:MatrixOne 对外提供了集群对接的小工具,MoDump,可以实现 load 这些数据。首先要做的是把这些数据打包 load 出来,然后再把这些数据 load 到产品里面。后期会开发一些对接各种数据库可以实时拷贝的工具。