马斯克确实以其高效率和大胆的行动著称,最近他旗下的AI初创企业xAI宣布了一项引人注目的举措:开源了一个名为Grok-1[1]的混合专家模型。

这个模型拥有3140亿个参数,是目前参数量最大的开源大型语言模型之一,而允许商用、可修改和分发,对各种自研大模型是一个很大的利好!这一行为不仅展示了马斯克对开放源代码和共享技术的一贯支持,也表明了他希望推动AI领域快速发展的决心截至目前,Grok-1已经在 GitHub 上斩获获 28k 颗 Star。
项目介绍
让我们先看下在Github的下载地址上,它的开源声明都说了什么:

1.模型介绍
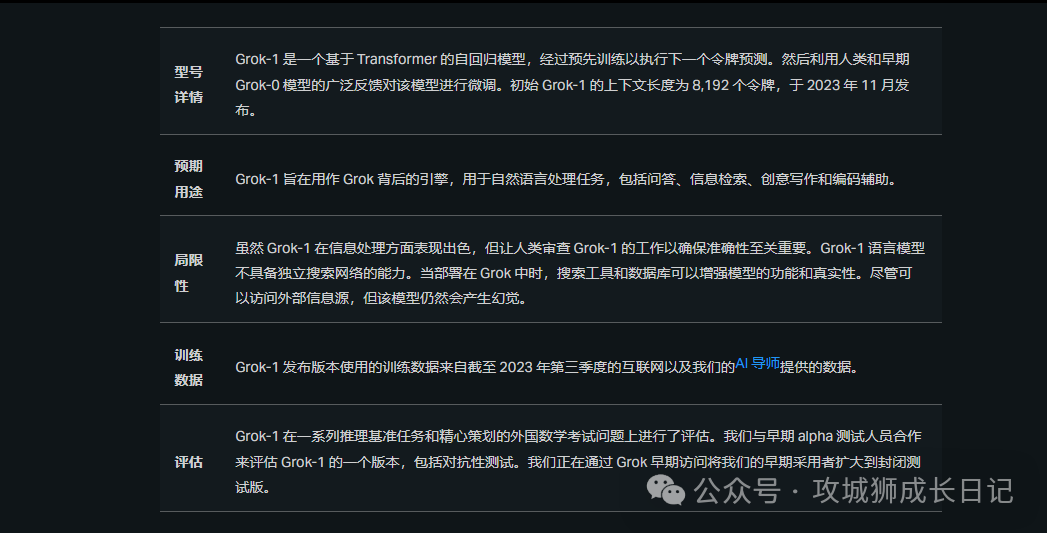
Grok-1模型拥有高达314亿个参数,采用了混合专家(MoE)层结构。MoE层的实现,在效率上存在局限,但这种结构设计选择是刻意为之,主要目的是为了简化模型验证流程,避免自定义内核的需求。Grok-1 的模型细节包括如下:
- 基础模型基于大量文本数据进行训练,没有针对任何具体任务进行微调;
- 3140 亿参数的 MoE 模型,在给定 token 上的激活权重为 25%;
- 2023 年 10 月,xAI 使用 JAX 库和 Rust 语言组成的自定义训练堆栈从头开始训练。
2.许可协议
Grok-1遵循Apache 2.0许可证,赋予用户以下权利:
- 「商业使用自由:」用户有权将Grok-1用于商业用途,无需支付任何许可费用。
- 「源代码修改及再分发:」用户可以对源代码进行修改,并且可以在相同的许可证下对修改后的版本进行分发
- 「专利权授予:」该许可证自动授予用户对软件的所有专利权利,确保贡献者无法基于专利对用户提起诉讼。
- 「版权和许可声明保留:」在分发软件或其衍生版本时,必须包含原始的版权和许可声明。
- 「责任限制:」虽然提供一定程度的保障,但软件的作者或贡献者不对因使用软件可能产生的任何损害承担责任。
看到这,有网友开始好奇 314B 参数的 Grok-1 到底需要怎样的配置才能运行。对此有人给出答案:可能需要一台拥有 628 GB GPU 内存的机器(每个参数 2 字节)。这么算下来,8xH100(每个 80GB)就可以了。

因此基本上个人是没办法用的,这个模型开源就是为了便于各种企业使用的,同时模型还提供了权重下载。
相关领域影响
Grok-1的开源对中小型企业在特定领域微调模型是一大利好。通过下载Grok进行微调,可以为基于该模型的各种有趣应用铺平道路。
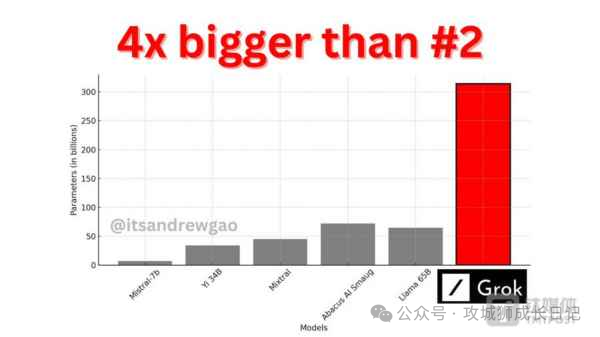
与之前开源的大型模型相比,Grok-1的参数规模更大。根据理论,模型的参数量越大,其潜在智能水平也应该更高。正如OpenAI已经验证的那样,巨大的参数量可能带来意想不到的结果。
就像Stable Diffusion的开源对国内各种AI绘画工具软件产生了影响一样,Grok-1的开源可能会在各种垂直领域应用中产生启发作用,特别是在国内应用方面可能会迎来一波爆发。
网友分析
知名机器学习研究者、《Python 机器学习》畅销书作者 Sebastian Raschka 评价道:「Grok-1 比其他通常带有使用限制的开放权重模型更加开源,但是它的开源程度不如 Pythia、Bloom 和 OLMo,后者附带训练代码和可复现的数据集。」
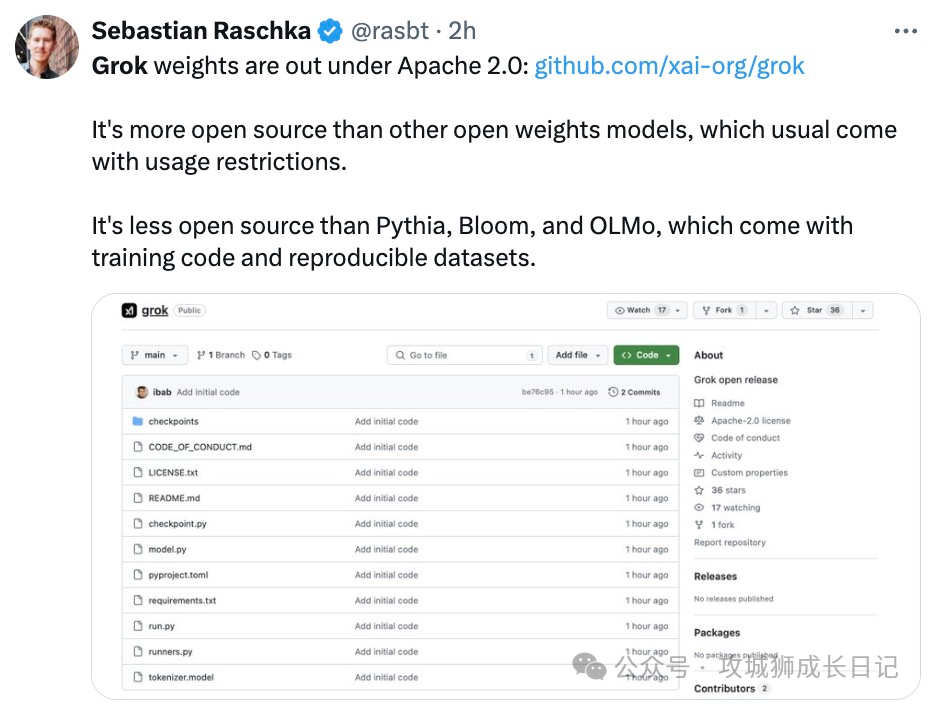
DeepMind 研究工程师 Aleksa Gordié 则预测,Grok-1 的能力应该比 LLaMA-2 要强,但目前尚不清楚有多少数据受到了污染。另外,二者的参数量也不是一个量级。

Grok-1的信息
Grok-1是由xAI公司开发的人工智能模型,拥有高达314亿个参数。该模型采用了一种称为混合专家(MoE)的技术。用人类团队的比喻来说,这就像是一个团队中有多位专家共同合作,每位专家都在自己擅长的领域发挥作用。
Grok-1的训练是从头开始的,没有专门针对任何特定任务进行优化或调整。整个研发过程历时四个月,期间经历了多次迭代。使用了JAX和Rust两种编程语言,这两者共同构建了一个强大的训练基础设施。为了训练Grok-1,xAI公司投入了大量资源,动用了上千块GPU,并花费了数月时间。在训练过程中,还特别关注提高模型的容错能力。
各界反应
先看看ChatGPT如何回复马斯克的嘲讽吧:
随后山姆奥特曼也回复了这件事情:
Reference:[1]Grok-1:https://github.com/xai-org/grok-1.git