














Arxiv论文链接:https://arxiv.org/abs/2312.03543
项目主页:https://github.com/Petrichor625/Talk2car_CAVG
近年来,工业界和学术界都争先恐后地研发全自动驾驶汽车(AVs)。尽管自动驾驶行业已经取得了显著进展,但公众仍然难以完全接受且信任自动驾驶汽车。公众对完全将控制权交给人工智能的接受度仍然相对谨慎,这主要受到了对人机交互可靠性的担忧以及对失去控制的恐惧的阻碍。这些挑战在复杂的驾驶情境中尤为凸显,车辆必须做出分秒必争的决定,这强调了加强人与机器之间沟通的紧迫需求。因此,开发一个能让乘客通过语言指令控制车辆的系统显得尤为重要。这要求系统允许乘客基于当前的交通环境给出相应指令,自动驾驶汽车需准确理解这些口头指令并做出符合发令者真实意图的操作。
得益于大型语言模型(LLMs)的快速发展,与自动驾驶汽车进行语言交流已经变得可行。澳门大学智慧城市物联网国家重点实验室须成忠教授、李振宁助理教授团队联合重庆大学,吉林大学科研团队提出了首个基于大语言模型的自动驾驶自然语言控制模型(CAVG)。该研究使用了大语言模型(GPT-4)作为乘客的语意情感分析,捕捉自然语言命令中的细腻情感内容,同时结合跨模态注意力机制,让自动驾驶车辆识别乘客的语意目的,进而定位到对应的交通道路区域,改变了传统乘客和自动驾驶汽车交互的方式。该研究还利用区域特定动态层注意力机制(RSD Layer Attention)作为解码器,帮助汽车精确识别和理解乘客的语言指令,定位到符合意图的关键区域,从而实现了一种高效的“与车对话”(Talk to Car)的交互方式。

自动驾驶汽车理解乘客语意,涉及到两个关键领域——计算机视觉和自然语言处理。如何利用跨模态的算法,在复杂的语言描述和实际场景之间建立有效的桥梁,使得驾驶系统能够全面理解乘客的意图,并在多样的目标中进行智能选择,是当前研究的一个关键问题。
鉴于乘客的语言表达与实际场景之间存在较大的差异,传统方法通常难以准确地将乘客的语言描述转化为实际驾驶目标。现有的挑战在于:传统模型很难实现乘客的意图分析,模型往往无法在全局场景下进行综合信息分析,由于陷入局部分析而给出错误的定位结果。同时在面对多个符合语义的潜在目标时,模型如何判断筛选,从中选择最符合乘客期待的结果也是研究的一个关键难题。

现有的视觉定位的算法主要分为两大类,One-Stage Methods和Two-Stage Methods:
- One-Stage Methods: One-Stage Methods本质上是一种端到端的算法,它只需要一个单一的网络就能够同时完成定位和分类两件事。在这种方法中的核心思想是将文本特征和图片特征进行编码,然后映射到特定的语意空间中,接着直接在整张图像上预测对象的类别和位置,没有单独的区域提取步骤。
- Two-Stage Methods:在Two-Stage Methods中,视觉定位任务拆成先定位、后识别的两个阶段。其核心思想是利用一个视觉网络(如CenterNet),在图像中识别出潜在的感兴趣区域(Regions of Interest, ROI),将潜在的符合语意的位置和对应的特征向量保存下来。ROI区域将有用的前景信息尽可能多地保留下来,同时滤除掉对后续任务无用的背景信息,随后在第二个识别阶段,结合对应的语意信息在多个ROI区域中挑选出最符合语意的结果。
但不管是哪个任务,如何更好地理解不同模态信息之间的交互关系是图文视觉定位必须解决的核心问题。
算法和模型介绍
作者将视觉定位问题归纳为:“通过给出乘客的目标指令与自动驾驶汽车的前视图,模型能够处理一幅车辆的正面视图图像,以遵循给定的命令,在图像中准确指出车辆应导航至的目的地区域。”
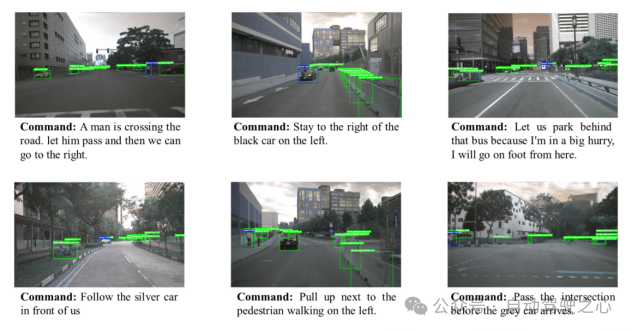
图1.1 Region Proposal示意图
为了使这一目标具体化,模型将考虑为一个映射问题:将文本向量映射到候选子区域中最合适的子区域。具体而言,CAVG基于Two-Stage Methods的架构思想,利用CenterNet模型在图像I提取分割出多个候选区域(Region Proposal),提取出对应区域的区域特征向量和候选区域框(bounding boxes)。如下图所示, CAVG使用Encoder-Decoder架构:包含文本、情感、视觉、上下文编码器和跨模态编码器以及多模态解码器。该模型利用最先进的大语言模型(GPT-4V)来捕捉上下文语义和学习人类情感特征,并引入全新的多头跨模态注意力机制和用于注意力调制的特定区域动态(RSD)层进一步处理和解释一系列跨模态输入,在所有Region Proposals中选择最契合指令的区域。
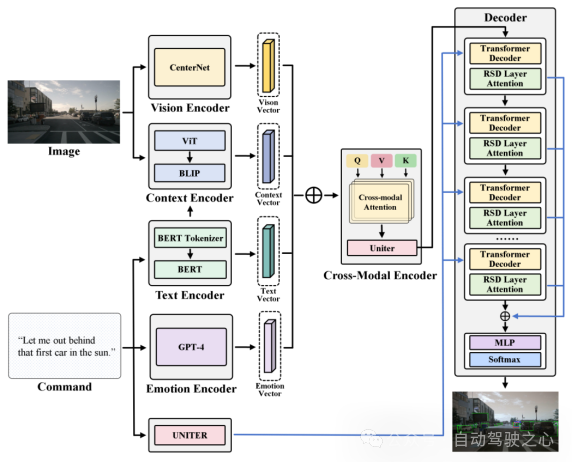
图1.2 CAVG模型架构图
- Text Encoder: 文本编码器使用BERT的文本编码表示生成对映Command的文本向量,表示为c。输入命令c通过BERT的Tokenizer分词器分词成序列,然后输入到BERT模型中,生成对应的文本向量,包含了输入命令的文本特征。

- Emotion Encoder: 情感编码器调用 GPT-4 进行情感分析。利用GPT4将每条输入命令都经过预处理,然后它分析文本,识别乘客对应的情感状态,划分归类为预定义的类别之一。如Urgent,Comamanding,Informative等。假如对乘客的指令的情感分析归类为Urgent,意味着乘客的命令由于其时间敏感性或关键性质需要立即采取行动。例如,乘客使用的指令为:“Wow hold on! That looks like my stolen bike over there! Drop me off next to it.”,指令中传达了一种需要立即关注的紧急情绪。情感编码器识别出这种情感状态,作为文本情感向量输入到模型中,帮助模型推断的目的地应该在最近的靠边区域搜索。

- Vison Encoder: 视觉编码器专门用于从输入的视觉图像中提取丰富的视觉信息。视觉编码器的架构基于先进的图像处理技术,编码器利用CenterNet提取出候选区域(如树木、车辆、自行车和行人等),利用ResNet-101网络架构将这候选区域的局部特征向量提取出来。

- Context Encoder: 上下文编码器利用预训练模型BLIP作为骨架,输入对应的提取文本向量和全局图片,将这部分向量进行文本-图片跨模态对齐。上下文编码器采取了一种更全面的方法。该部分编码器不仅旨在识别输入图像中的关键焦点,而且还超越了Region Proposal局部区域边界框的限制,辨别整个视觉场景中更广泛的上下文关系。这部分全局特征向量捕捉了一些例如车道标记、行人路径、交通标志的关键的上下文细节。通过引入全局向量扩展的视野使我们的模型能够吸收更广泛的视觉信息和上下文线索,确保全面的语义解释。


图1.3 Context Encoder中不同层输出示意图
- Cross-Modal Encoder: 文章通过提出一种新的跨模态注意力机制方法,将跨模态编码器通过多头注意力机制融合前面的多种模态向量,将视觉和文本数据对齐和整合。将文本编码器和情感编码器得到的文本向量和拼接后,通过线性层映射到和和图片向量同一个维度,作为多头注意力机制中的查询向量Q 。同理将视觉编码器和上下文编码器得到的向量和分别映射到多头注意力机制中的和和特征向量。
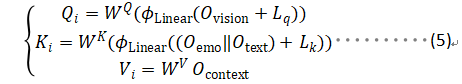


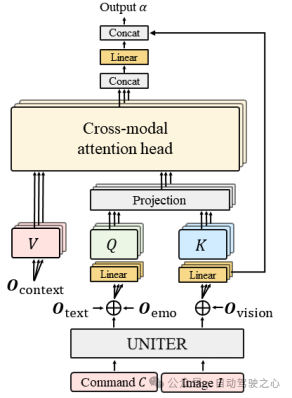
图1.4 跨模态注意力机制示意图
数据集介绍
本工作采用了Talk2Car数据集。下图详细比较了Talk2Car和其他Visual Grounding相关数据集(如ReferIt、RefCOCO、RefCOCO+、RefCOCOg、Cityscape Ref和CLEVR-Ref)的异同。Talk2Car数据集包含11959个自然语言命令和对应场景环境视图的数据集,用于自动驾驶汽车的研究。这些命令来自nuScenes训练集中的850个视频,其中55.94%的视频拍摄于波士顿,44.06%的视频拍摄于新加坡。数据集对每个视频平均给出了14.07个命令。每个命令平均由11.01个单词、2.32个名词、2.29个动词和0.62个形容词组成。在每幅图像中,平均有4.27个目标与描述目标属于相同类别,平均每幅图片有10.70个目标。下图解释了文章所统计数据集中的指令长度和场景中交通车辆种类的布局。
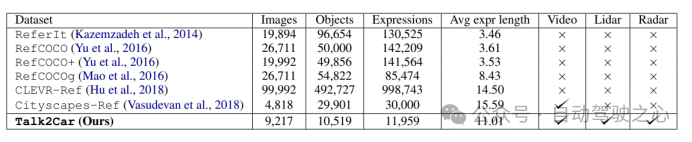
图1.5 不同Visual Grounding任务数据集之间的场景比较
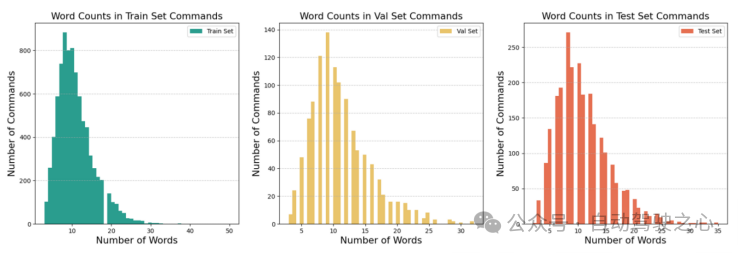
图1.6 对Talk2Car挑战任务的统计分析结果
符合C4AV挑战赛的要求,我们将预测区域利用bounding boxes在图中标出表示,同时采用左上坐标和右下坐标(x1,y1,x2,y2)的格式来提交对应的数据结果。t同时我们使用scores作为评估指标,定义为预测的bounding boxes中交并区域与实际边界框相交的比中超过0.5阈值的占比(IoU0.5)。这一评估指标在PASCAL(Everingham和Winn,2012年)、VOC(Everingham等人,2010年)和COCO(Lin等人,2014年)数据集等挑战和基准测试中广泛使用,为我们的预测准确性提供了严格的量化,并与计算机视觉和对象识别任务中的既定实践相一致。以下方程详细说明了预测边界框和实际边界框之间的IoU的计算方法:
实验结果
本文使用度量在Talk2Car数据集上的模型与各种SOTA方法的性能比较。模型分为三种类型:One-stage、Two-stage和Others,并基于架构骨干进行评估:视觉特征提取视觉、语义信息提取语言和整体数据同化全局。其他被评估的成分包括是否使用情绪分类(EmoClf.),全局图像特征提取(全局Img特征表示),语言增强(NLP Augm.),和视觉增强(Vis Augm.)。“Yes”表示使用了相关的技术或者功能组件,“No”表示模型未使用对应的功能和组件,“-”表示
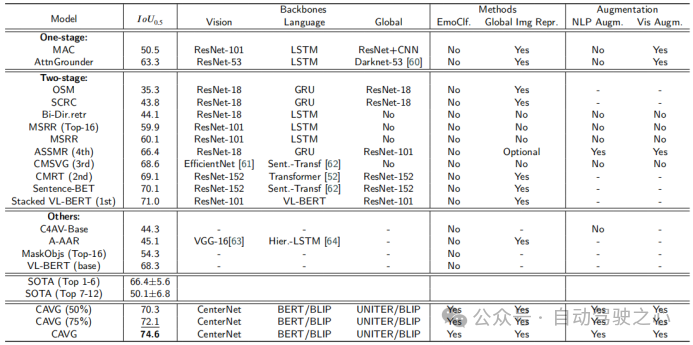
在对应文章中未公开相关的星系。这种分类阐明了影响每个模型性能的基本组件和策略。下图中的粗体值和下划线值分别代表最佳的模型和第二好的模型。
为了严格评估CAVG的模型在现实场景中的有效性,文章根据语言命令的复杂性和视觉环境的挑战,文章精心地划分了测试集。一方面,由于较长的命令可能会引入不相关的细节,或者对自动驾驶汽车来说更难理解。对于长文本测试集,我们采用了一种数据增强策略,在不偏离原始语义意图的情况下,增加了数据集的丰富性。我们使用GPT扩展了命令长度,得到的命令范围从23到50个单词。进一步评估模型处理扩展的语言输入的能力,对模型的适应性和鲁棒性进行全面的评估。
另一方面,为了进一步衡量模型的泛用性,本文还额外选取构造了特定的测试场景场景:如低光的夜晚场景、复杂物体交互的拥挤城市环境、模糊的命令提示以及能见度下降的场景,使预测更具困难。将而外构造的两个测试集合分别称为为Long-text Test和Corner-case Test。
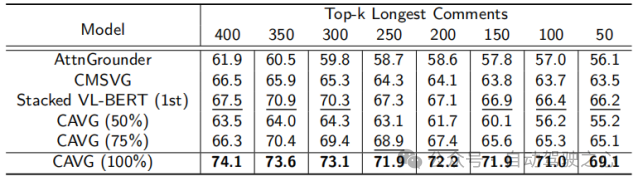
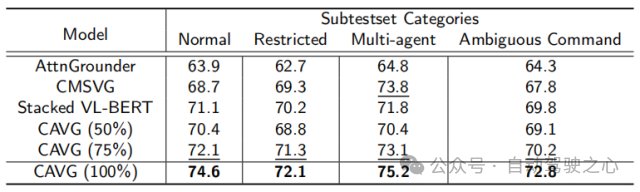
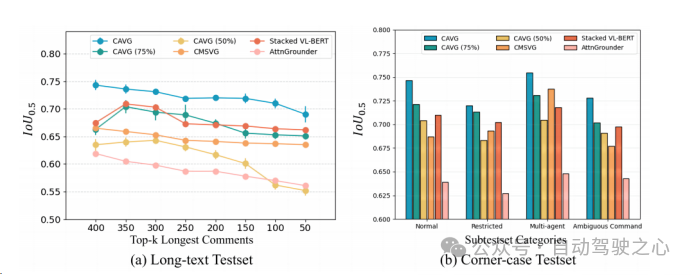

除此之外,仅使用一半的数据集CAVG(50%)和CAVG(75%)迭代显示出令人印象深刻的性能。提供足够的训练数据时,我们的模型CAVG和CAVG(75%)在部分特殊场景中表现出色。


本文在RSD Layer Attention机制的多模态解码器中可视化了13层的层注意权值的分布,以进一步展示文章所使用的RSD层注意机制的有效性。根据其与地面真实区域对齐,将输入区域划分为两个不同的组:> 0:包含所有超过0的区域,表明与地面真实区域有重叠。= 0:构成没有重叠的区域,其精确地为0。如下图所示,较高的解码器层(特别是第7至第10层)被赋予了较大比例的注意权重。这一观察结果表明,向量对这些更高的层有更大的影响,可能是由于增加的跨模态相互作用。与直观预期相反,最顶层并不主导注意力的权重。这与传统的主要依赖于最顶层表示来预测最佳对齐区域的技术明显不同,RSD Layer Attention机制会避开其他层中固有的微妙的跨模态特征。
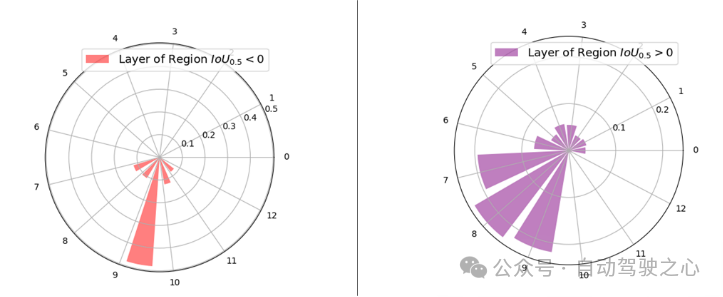

图1.7 VIT中不同层的注意力分布示意图

图1.8 调研用户岁数和驾驶经验分布

图1.9 用户调研结果































