













在视觉生成领域迅速发展的过程中,扩散模型已经彻底改变了这一领域的格局,通过其令人印象深刻的文本引导生成功能标志着能力方面的重大转变。
然而,仅依赖文本来调节这些模型并不能完全满足不同应用和场景的多样化和复杂需求。
鉴于这种不足,许多研究旨在控制预训练文本到图像(T2I)模型以支持新条件。
在此综述中,来自北京邮电大学的研究人员对关于具有 T2I 扩散模型可控性生成的文献进行了彻底审查,涵盖了该领域内理论基础和实际进展。

论文:https://arxiv.org/abs/2403.04279代码:https://github.com/PRIV-Creation/Awesome-Controllable-T2I-Diffusion-Models
我们的审查从简要介绍去噪扩散概率模型(DDPMs)和广泛使用的 T2I 扩散模型基础开始。
然后我们揭示了扩散模型的控制机制,并从理论上分析如何将新条件引入去噪过程以进行有条件生成。
此外,我们提供了对该领域研究情况详尽概述,并根据条件角度将其组织为不同类别:具有特定条件生成、具有多个条件生成以及通用可控性生成。
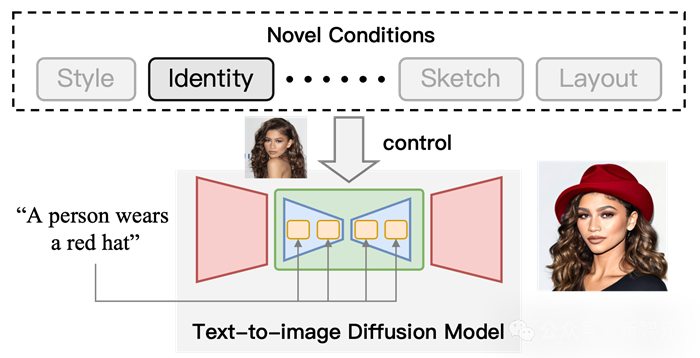
图 1 利用T2I扩散模型可控生成示意图。在文本条件的基础上,加入「身份」条件来控制输出的结果。
分类体系
利用文本扩散模型进行条件生成的任务代表了一个多方面和复杂的领域。从条件角度来看,我们将这个任务分为三个子任务(参见图2)。
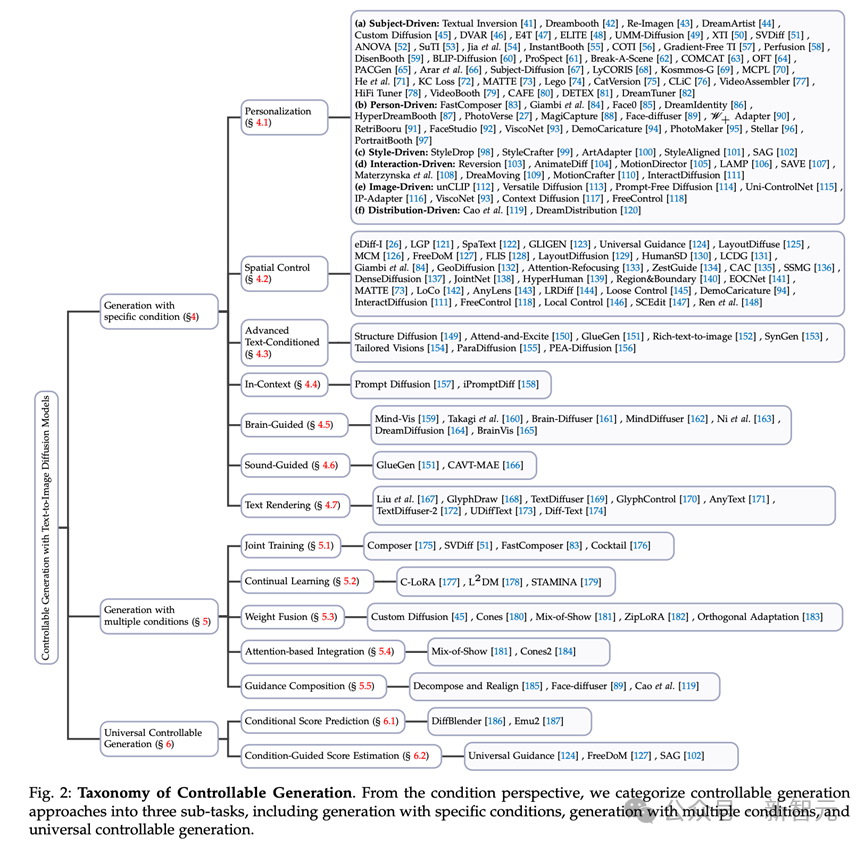
图 2 可控生成的分类。从条件角度来看,我们将可控生成方法分为三个子任务,包括具有特定条件的生成、具有多个条件的生成和通用可控生成。
大多数研究致力于如何在特定条件下生成图像,例如基于图像引导的生成和草图到图像的生成。
为了揭示这些方法的理论和特征,我们根据它们的条件类型进一步对其进行分类。
1. 利用特定条件生成:指引入了特定类型条件的方法,既包括定制的条件(Personalization, e.g., DreamBooth, Textual Inversion),也包含比较直接的条件,例如ControlNet系列、生理信号-to-Image
2. 多条件生成:利用多个条件进行生成,对这一任务我们在技术的角度对其进行细分。
3. 统一可控生成:这个任务旨在能够利用任意条件(甚至任意数量)进行生成。
如何在T2I扩散模型中引入新的条件
细节请参考论文原文,下面对这些方法机理进行简要介绍。
条件得分预测(Conditional Score Prediction)
在T2I扩散模型中,利用可训练模型(例如UNet)来预测去噪过程中的概率得分(即噪声)是一种基本且有效的方法。
在基于条件得分预测方法中,新颖条件会作为预测模型的输入,来直接预测新的得分。

其可划分三种引入新条件的方法:
1. 基于模型的条件得分预测:这类方法会引入一个用来编码新颖条件的模型,并将编码特征作为UNet的输入(如作用在cross-attention层),来预测新颖条件下的得分结果;
2. 基于微调的条件得分预测:这类方法不使用一个显式的条件,而是微调文本嵌入和去噪网络的参数,来使其学习新颖条件的信息,从而利用微调后的权重来实现可控生成。例如DreamBooth和Textual Inversion就是这类做法。
3. 无需训练的条件得分预测:这类方法无需对模型进行训练,可以直接将条件作用于模型的预测环节,例如在Layout-to-Image(布局图像生成)任务中,可以直接修改cross-attention层的attention map来实现设定物体的布局。
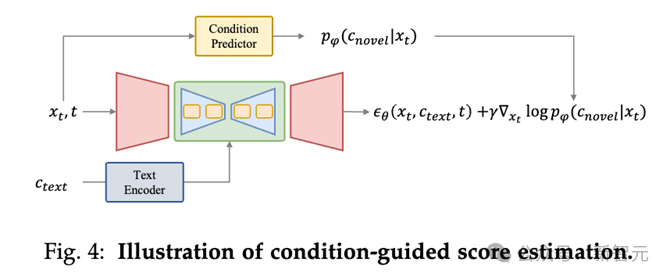
条件引导的得分评估
条件引导估的得分估计方法是通过条件预测模型(如上图Condition Predictor)反传梯度来在去噪过程中增加条件指导。
利用特定条件生成

1. Personalization(定制化):定制化任务旨在捕捉和利用概念作为生成条件行可控生成,这些条件不容易通过文本描述,需要从示例图像中进行提取。如DreamBooth,Texutal Inversion和LoRA。
2. Spatial Control(空间控制):由于文本很难表示结构信息,即位置和密集标签,因此使用空间信号控制文本到图像扩散方法是一个重要的研究领域,例如布局、人体姿势、人体解析。方法例如ControlNet。
3. Advanced Text-Conditioned Generation(增强的文本条件生成):尽管文本在文本到图像扩散模型中起着基础条件的作用,但该领域仍存在一些挑战。
首先,在涉及多个主题或丰富描述的复杂文本中进行文本引导合成时,通常会遇到文本不对齐的问题。此外,这些模型主要在英语数据集上训练,导致了多语言生成能力明显不足。为解决这一限制,许多工作提出了旨在拓展这些模型语言范围的创新方法。
4. In-Context Generation(上下文生成):在上下文生成任务中,根据一对特定任务示例图像和文本指导,在新的查询图像上理解并执行特定任务。
5. Brain-Guided Generation(脑信号引导生成):脑信号引导生成任务专注于直接从大脑活动控制图像创建,例如脑电图(EEG)记录和功能性磁共振成像(fMRI)。
6. Sound-Guided Generation(声音引导生成):以声音为条件生成相符合的图像。
7. Text Rendering(文本渲染):在图像中生成文本,可以被广泛应用到海报、数据封面、表情包等应用场景。
多条件生成

多条件生成任务旨在根据多种条件生成图像,例如在用户定义的姿势下生成特定人物或以三种个性化身份生成人物。
在本节中,我们从技术角度对这些方法进行了全面概述,并将它们分类以下类别:
1. Joint Training(联合训练):在训练阶段就引入多个条件进行联合训练。
2. Continual Learning(持续学习):有顺序的学习多个条件,在学习新条件的同时不遗忘旧的条件,以实现多条件生成。
3. Weight Fusion(权重融合):用不同条件微调得到的参数进行权重融合,以使模型同时具备多个条件下的生成。
4. Attention-based Integration(基于注意力的集成):通过attention map来设定多个条件(通常为物体)在图像中的位置,以实现多条件生成。
通用条件生成
除了针对特定类型条件量身定制的方法之外,还存在旨在适应图像生成中任意条件的通用方法。
这些方法根据它们的理论基础被广泛分类为两组:通用条件分数预测框架和通用条件引导分数估计。
1. 通用条件分数预测框架:通用条件分数预测框架通过创建一个能够编码任何给定条件并利用它们来预测图像合成过程中每个时间步的噪声的框架。
这种方法提供了一种通用解决方案,可以灵活地适应各种条件。通过直接将条件信息整合到生成模型中,该方法允许根据各种条件动态调整图像生成过程,使其多才多艺且适用于各种图像合成场景。
2. 通用条件引导分数估计:其他方法利用条件引导的分数估计将各种条件纳入文本到图像扩散模型中。主要挑战在于在去噪过程中从潜变量获得特定条件的指导。
应用
引入新颖条件可以在多个任务中发挥用处,其中包括图像编辑、图像补全、图像组合、文/图生成3D。
例如,在图像编辑中,可以利用定制化方法,将图中出现猫编辑为特具有定身份的猫。其他内容请参考论文。
总结
这份综述深入探讨了文本到图像扩散模型的条件生成领域,揭示了融入文本引导生成过程中的新颖条件。
首先,作者为读者提供基础知识,介绍去噪扩散概率模型、著名的文本到图像扩散模型以及一个结构良好的分类法。随后,作者揭示了将新颖条件引入T2I扩散模型的机制。
然后,作者总结了先前的条件生成方法,并从理论基础、技术进展和解决方案策略等方面对它们进行分析。
此外,作者探索可控生成的实际应用,在AI内容生成时代强调其在其中发挥重要作用和巨大潜力。
这项调查旨在全面了解当前可控T2I生成领域的现状,从而促进这一充满活力研究领域持续演变和拓展。



























