AI程序员Devin竟可以做老板的工作了?!
最近,Cognition AI的首席执行官Steven Hao给了Devin访问自己帐户的权限,然后Devin便开始为他工作了...

比如,「他」向初创公司Modal支持团队写了一封邮件,是询问关于其产品Secrets更新后用多久再提供给正在运行的应用程序。

然后,「AI老板」Devin与技术团队进行了无缝交流,最终解决了自己的疑惑。

就在最近,Cognition团队发布了Devin的最新技术报告。
开篇,Cognition提到团队的目标之一,就是让Devin成为一个专门从事软件开发的AI智能体,能够成功地为大型复杂代码库贡献代码。

Reddit网友称,「所有否认软件工程师很快就会过时的人都太天真了。失业将对我们所有人造成冲击」。

还有网友表示,AI正在迅速地重塑我们的现实,以至于我们根本不知道发生了什么。


技术报告出炉
为了评估Devin,研究人员使用了SWE-BENCH——一个针对软件工程系统的自动化基准测试,可以确定地评估(通过单元测试)系统在真实代码库中解决问题的能力。

https://www.swebench.com/
在SWE-bench中,Devin成功解决了13.86%的问题,远远超过了之前最高的1.96%无辅助基线。
即使给定要编辑的确切文件(「辅助」模式),之前的最好的模型也只能解决4.80%的问题。
方法
研究人员采用SWE-BENCH来评估智能体,这比原始的LLM评估设置更通用。
设置
- 使用标准化的提示从头到尾运行智能体,要求它仅根据GitHub问题描述编辑代码。在运行过程中,不会向智能体提供任何其他用户输入。
- 代码仓库被克隆到智能体的环境中。只保留基础提交(base commit)及其「祖先」提交在git历史记录中,以防止信息泄露给智能体。值得注意的是,研究人员移除了git远程仓库,这样git pull就不起作用。
- 在测试开始之前,设置了Python Conda环境。
- 将Devin的运行时间限制在45分钟,因为与大多数智能体不同的是,它具有无限期运行的能力。如果愿意,它可以选择提前终止。
Eval
- 智能体运行退出后,研究人员会将所有测试文件重置为原始状态,以防智能体修改测试,并将文件系统中的所有其他差异提取为patch。
- 为了确定哪些文件是测试文件,研究人员采用在测试patch中修改的所有文件的集合。
- 将智能体的patch应用到repo,然后是测试patch。
- 运行SWE-BENCH提供的eval命令,并检查是否所有测试都通过。
具体可以在如下链接中,找到研究人员改编的评估工具的代码:
https://github.com/CognitionAI/devin-swebench-results.

结果
研究人员在SWE基准测试集中,随机抽取了25%的测试集(2294个测试集中的570个)对Devin进行了评估。
这样做是为了缩短基准测试的完成时间,与作者在原始论文中使用的策略相同。
Devin成功解决了570个问题中的79个,成功率为13.86%。这明显高于之前最佳辅助系统Claude 2的4.80%。

图中的基线是在「assisted」设置中评估的,即向模型提供其需要编辑的确切文件。
基线在「unassisted」设置中表现较差,在这种情况下,一个单独的检索系统为LLM选择要编辑的文件(最佳模型是Claude 2+BM25检索系统,得分率为1.96%)。
在智能体环境中,Devin拥有整个软件repo,可以自由浏览文件,因此研究人员选择了较强的数据作为比较基准。
案例分析
多步规划
Devin可以执行多步计划,以接收来自环境的反馈。
72%的通过测试需要10分钟以上的时间才能完成,这表明迭代能力有助于Devin取得成功。

定性示例
研究人员对Devin的结果进行了一些定性分析。回想一下,Devin只得到了问题描述和克隆存储库作为输入。
示例1
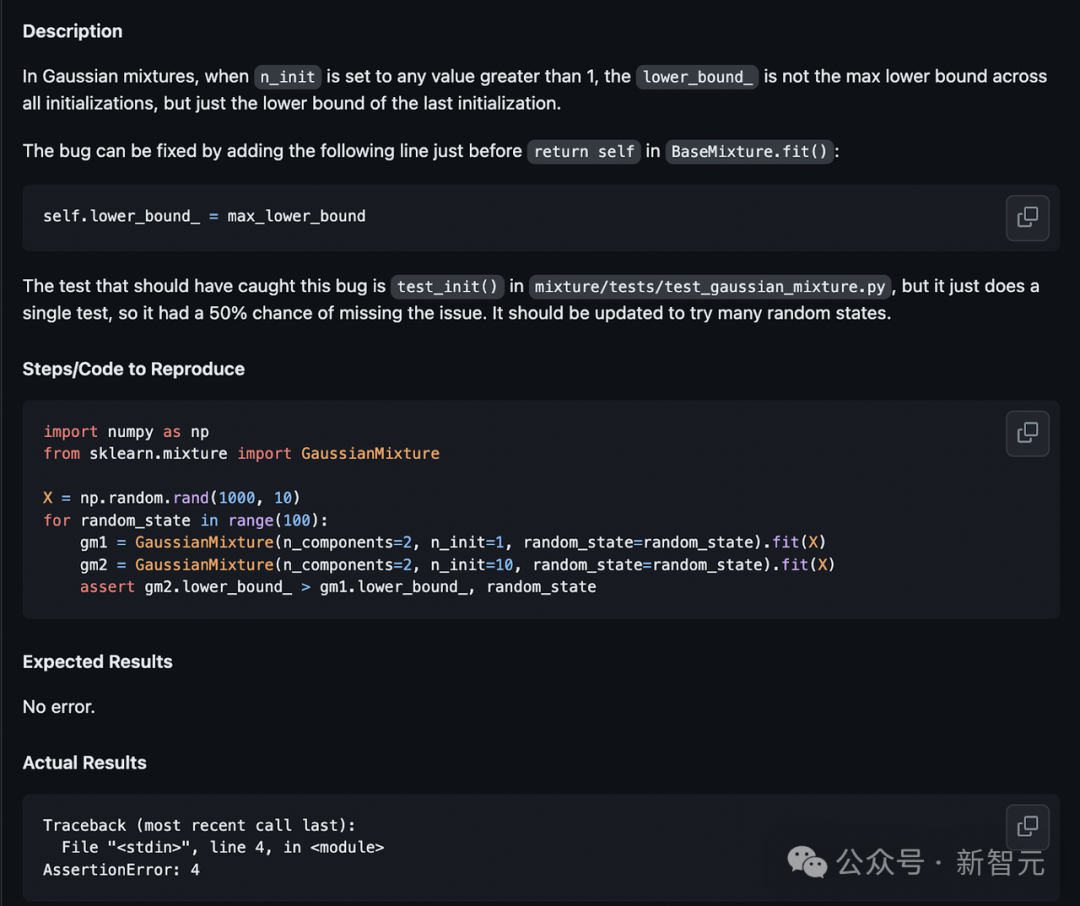
最初,Devin被描述吓了一跳,它在返回self之前添加了self.lower_bound_ = max_lower_bound。
这实际上是不正确的,因为变量尚未定义。

根据问题描述中提供的测试代码,Devin会更新测试文件:

但在运行测试并出现错误后,Devin更正了文件:


在此修复后,Devin重新运行测试,以使其通过并成功退出。
这个例子很有趣,原因有几个:
- 尽管不准确,Devin还是非常严格地遵循了原版中的指示。这表明与用户的首选项过于一致。
- 有了在环境中运行测试的能力,Devin就能纠正自己的错误。对于软件开发人员来说,能够迭代是至关重要的,而智能体也应该能够做到这一点。
示例2
Devin可以识别正确的文件 django/db/backends/postgresql/client.py ,并进行完整编辑:

在这里,Devin能够成功地修改一大段代码。
SWE-BENCH中,许多成功编辑都由单行差异组成,但Devin能够同时处理多行。
示例3
这是一项艰巨的任务,涉及修改计算机代数系统,以正确处理地板和天花板对象上,与可指定为正值或负值的值有关的比较运算符。
这需要复杂的逻辑推理和多个推导步骤。

Devin错选了要编辑的正确类,他编辑的是frac类,而不是floor类和ceiling类。
此外,Devin只编辑了一个比较运算符gt,而lt、le和ge也需要修改。这样的编辑离正确还差得很远。
示例4
这项任务涉及向回购中的所有数据集添加额外的退货选项功能。Devin能够成功地对几个数据集进行此编辑;下面显示了一个示例。


Devin设法对数据集 california_housing.py 、 covtype.py 、 kddcup99.py 和 mldata.py (原始PR实际上排除了它们)进行了类似的编辑。
不幸的是,Devin漏掉了两个数据集, lfw.py 和 rcv1.py ,因此测试最终失败。研究人员打算改进Devin编辑多个文件的能力。
测试驱动实验
研究人员又进行了一次实验,向Devin提供了最终的单元测试和问题陈述。
在这种「测试驱动开发」的环境下,100个抽样测试中,成功通过率提高到了23%。(请注意,对测试本身的任何修改都会在评估前被删除)。
这一结果是无法与SWE-BENCH的其他结果相比较的,因为该智能体可以访问真值测试patch。
尽管如此,测试驱动开发是软件工程中的一种常见模式,因此这种设置是SWE-BENCH的自然扩展。
人类给智能体一个有针对性的测试,来通过是人类工程师和智能体合作的一种自然方式,我们预计未来会看到更多测试驱动的智能体。
Devin通过测试新解决的问题示例
Devin通过在函数前面添加一条Print语句,然后运行单元测试,然后根据Print语句编辑文件,解决了这个问题。


新单元测试断言会发出准确的错误信息:The value of 'filter_horizontal[0]' cannot include […]。
如果不知道错误的确切措辞,就不可能通过测试。
这凸显了该基准的一个问题,说明不使用测试patches也不可能获得满分。
智能体仍在发展的初级阶段,还有很大的改进空间。Cognition团队相信智能体的能力将在未来显著提高。