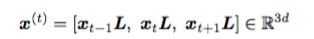传统的时空预测模型通常需要大量数据支持才能取得良好效果。
然而,由于城市发展水平不均衡和数据收集政策的差异,许多城市和地区的时空数据(如交通和人群流动数据)受到了限制。在这种情况下,模型在数据稀缺情况下的可迁移性变得尤为重要。
现有研究主要利用数据丰富的源城市数据训练模型,并将其应用于数据稀缺的目标城市。然而,现有方法往往依赖于复杂的匹配设计,如何实现对源城市和目标城市之间更一般化的知识迁移仍然是一个挑战。
最近,预训练模型在自然语言处理和计算机视觉领域取得了显著进展,它们通过引入prompt(提示)技术来缩小微调和预训练之间的差距。这些先进的预训练模型不再需要繁琐的微调,而是利用有效的prompt技术实现快速适应。
 图片
图片
论文链接:https://openreview.net/forum?id=QyFm3D3Tzi
开源代码及数据:https://github.com/tsinghua-fib-lab/GPD
清华大学电子工程系城市科学与计算研究中心最新成果《Spatio-Temporal Few-Shot Learning via Diffusive Neural Network Generation》被 ICLR2024 接收,该研究提出GPD(Generative Pre-Trained Diffusion)模型,实现数据稀疏场景下的时空学习。
通过直接生成神经网络的参数,该方法将时空少样本学习转变为扩散模型的生成式预训练问题。与传统方法不同,GPD不再依赖于提取可迁移特征或设计复杂的模式匹配策略,且不需要为少样本场景学习一个良好的模型初始化。
相反,它通过预训练一个扩散模型,从源城市的数据中学习到有关优化神经网络参数的知识,然后根据prompt(提示)生成适应目标城市的神经网络。
这一方法的创新之处在于能够根据「prompt(提示)」生成定制的神经网络,有效地适应不同城市之间的数据分布和特征差异,实现巧妙的时空知识迁移。
该研究为解决城市计算中数据稀缺性问题提供了新的思路。该论文的数据和代码均已开源。
从数据分布到神经网络参数分布
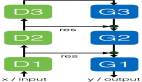
 图 1:数据模式层面知识迁移 vs. 神经网络层面知识迁移
图 1:数据模式层面知识迁移 vs. 神经网络层面知识迁移
如图1(a)所示,传统的知识迁移方法通常是在源城市的数据上训练模型,然后将其应用于目标城市。然而,不同城市之间的数据分布可能存在显著差异,这导致直接迁移源城市模型可能无法很好地适应目标城市的数据分布。
因此,我们需要摆脱对杂乱数据分布的依赖,寻求一种更本质、更可迁移的知识共享方式。与数据分布相比,神经网络参数的分布更具有“高阶”的特性。
图 1 展示了从数据模式层面到神经网络层面知识迁移的转变过程。通过在源城市的数据上训练神经网络,并将其转化为生成适应目标城市的神经网络参数的过程,可以更好地适应目标城市的数据分布和特征。
预训练+提示微调:实现时空少样本学习
 图2 GPD模型概览
图2 GPD模型概览
如图2所示,该研究提出的GPD是一种条件生成框架,旨在直接从源城市的模型参数中学习,并为目标城市生成新的模型参数,该方法包括三个关键阶段:
1. 神经网络准备阶段:首先,针对每个源城市区域,该研究训练单独的时空预测模型,并保存其优化后的网络参数。每个区域的模型参数都经过独立优化,没有参数共享,以确保模型能够最大程度地适应各自区域的特征。
2. 扩散模型预训练:该框架使用收集到的预训练模型参数作为训练数据,训练扩散模型来学习生成模型参数的过程。扩散模型通过逐步去噪来生成参数,这个过程类似于从随机初始化开始的参数优化过程,因此能够更好地适应目标城市的数据分布。
3. 神经网络参数生成:在预训练后,可以通过使用目标城市的区域提示来生成参数。这种方法利用提示促进了知识转移和精确参数匹配,充分利用了城市间区域之间的相似性。
值得注意的是,在预训练-提示微调的框架中,提示的选择具有很高的灵活性,只要能够捕捉特定区域的特征即可。例如可以利用各种静态特征,如人口、区域面积、功能和兴趣点(POI)的分布等来实现这一目的。
这项工作从空间和时间两个方面利用区域提示:空间提示来自于城市知识图谱[1,2]中节点表征,它仅利用区域邻接性和功能相似性等关系,这些关系在所有城市中都很容易获取;时间提示来自于自监督学习模型的编码器。更多关于提示设计的细节请参见原文。
此外,该研究还探索了不同的提示引入方法,实验验证了基于先验知识的提示引入具有最优性能:用空间提示引导建模空间关联的神经网络参数生成,用时间提示引导时序神经网络参数生成。
实验结果
团队在论文中详细描述了实验设置,以帮助其他研究者复现其结果。他们还提供了原论文和开源数据代码,我们在这里关注其实验结果。
为了评估所提框架的有效性,该研究在两类经典的时空预测任务上进行了实验:人群流动预测和交通速度预测,覆盖了多个城市的数据集。
 图片
图片
表1展示了在四个数据集上相对于最先进基线方法的比较结果。根据这些结果,可以得出以下观察:
1)GPD相对于基线模型表现出显著的性能优势,在不同数据场景下一致表现优越,这表明GPD实现了有效的神经网络参数层面的知识迁移。
2)GPD在长期预测场景中表现出色,这一显著趋势可以归因于该框架对于更本质知识的挖掘,有助于将长期时空模式知识迁移到目标城市。
 图3 不同时空预测模型的性能对比
图3 不同时空预测模型的性能对比
此外,该研究还验证了GPD框架对于不同时空预测模型适配的灵活性。除了经典的时空图方法STGCN外,该研究还引入了GWN和STID作为时空预测模型,并使用扩散模型生成其网络参数。
实验结果表明,框架的优越性不会受到模型选择的影响,因此可以适配各种先进的模型。
进一步地,该研究通过在两个合成数据集上操纵模式相似性进行案例分析。
图4展示了区域A和B具有高度相似的时间序列模式,而区域C展示了明显不同的模式。同时,图5显示节点A和B具有对称的空间位置。
因此,我们可以推断区域A和B具有非常相似的时空模式,而与C有着明显的差异。模型生成的神经网络参数分布结果显示,A和B的参数分布相似,而与C的参数分布有显著差异。这进一步验证了GPD框架在有效生成具有多样化时空模式的神经网络参数的能力。

图 4 不同区域的时间序列及神经网络参数分布可视化

图 5 仿真数据集区域空间连接关系
参考资料:
https://github.com/tsinghua-fib-lab/GPD
[1] Liu, Yu, et al. "Urbankg: An urban knowledge graph system." ACM Transactions on Intelligent Systems and Technology 14.4 (2023): 1-25.
[2] Zhou, Zhilun, et al. "Hierarchical knowledge graph learning enabled socioeconomic indicator prediction in location-based social network." Proceedings of the ACM Web Conference 2023. 2023.