HashMap是Java中非常重要且被广泛使用的数据结构,其内部实现充满了有趣而复杂的算法。我们研究下HashMap内部的一些核心算法,包括哈希冲突的解决、扩容策略、树化与树退化等。
1. 容量计算方法
即tableSizeFor方法。其主要目的是确保HashMap的容量始终是2的幂次方,这一特性对HashMap的哈希算法和扩容策略都至关重要。
- Integer.numberOfLeadingZeros(cap - 1): 这个方法返回参数cap - 1的二进制表示中,从最高位开始连续的零的个数。这个值实际上表示了cap的二进制表示中,最高位的位置(不包括符号位)。
- -1 >>> Integer.numberOfLeadingZeros(cap - 1): 这一步通过将-1右移numberOfLeadingZeros位,实际上将最高位至numberOfLeadingZeros位之间的所有位都置为1,其余位为0。这样做的目的是为了确保在后续的计算中,得到的值是一个2的幂次方减1的形式。
- (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1: 这一步对上述得到的值进行判断和修正。如果计算结果小于0,说明cap为0,因此将容量设为1;如果计算结果超过了MAXIMUM_CAPACITY,即HashMap的最大容量限制,将容量设为MAXIMUM_CAPACITY;否则,将容量设为n + 1。这里的n + 1保证了返回的容量是2的幂次方。
总的来说,tableSizeFor方法确保了HashMap的容量始终是2的幂次方。这种容量设置的方式有助于提高哈希算法的性能,同时与HashMap的扩容策略密切相关。这样的设计使得HashMap在进行哈希计算时,可以通过位运算,取代一些昂贵的除法运算,从而提高计算效率。
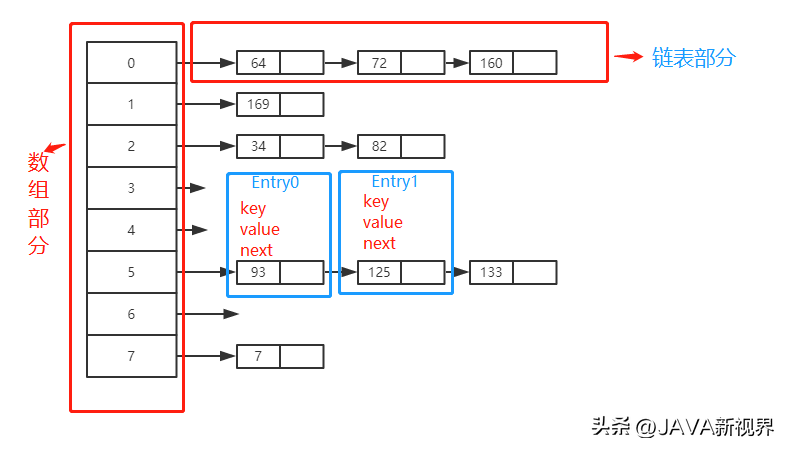
2. 哈希冲突:链表和红黑树
在HashMap中,哈希冲突是指不同的键可能映射到相同的索引位置的情况。为了解决冲突,HashMap采用了拉链法,即将具有相同哈希码的键值对存储在同一个数组位置,以链表的形式。
上述Node类表示HashMap中的一个节点,包含了键、值、哈希码以及指向下一个节点的引用。当冲突的链表长度超过一定阈值(默认为8)时,HashMap会将链表转换为红黑树,以提高查找效率。
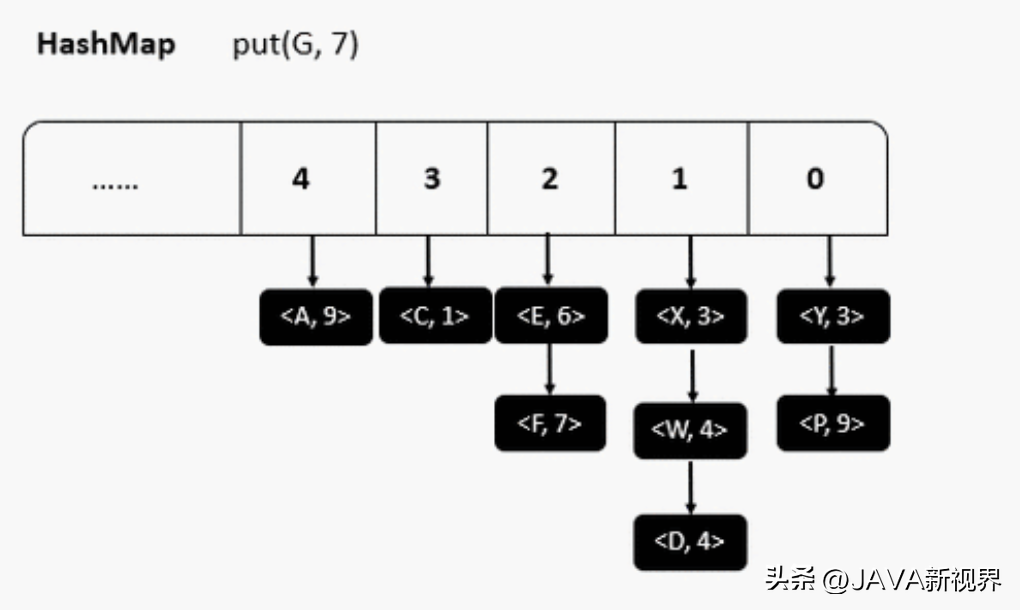
3. 扩容:2 的幂次方扩容
当HashMap的元素数量达到一定负载因子时(默认为0.75),为了避免链表过长,会触发扩容操作。在扩容时,HashMap将数组容量扩大至原来的两倍,并重新计算所有元素的索引位置。
oldCap表示原数组的容量,newCap表示新数组的容量,通过位运算将原容量左移一位实现扩容。
4. 哈希码计算:扰动函数
为了减小哈希冲突的概率,HashMap采用了扰动函数,将键的哈希码进行“扰动”。
这里的hash方法通过异或运算和无符号右移等位运算,将键的哈希码进行扰动,增加哈希码的随机性。
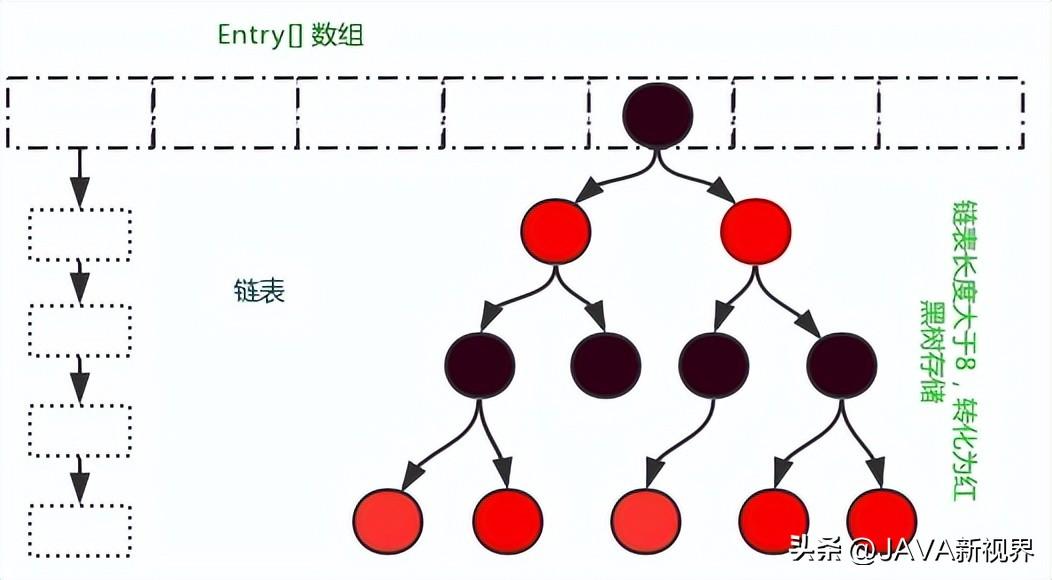
5. 树化与树退化
为了提高查找效率,当链表长度超过一定阈值(默认为8)时,HashMap会将链表转化成红黑树。而在删除或链表长度过短时,红黑树又可能退化成链表。
UNTREEIFY_THRESHOLD是一个阈值,表示当红黑树的节点数小于等于6时,将红黑树退化为链表。
6. 负载因子和重新哈希
负载因子是HashMap决定是否需要进行扩容的一个关键参数。当HashMap中的元素数量达到容量与负载因子的乘积时,就会触发扩容。在扩容时,HashMap会重新计算所有元素的索引位置,这个过程称为重新哈希。
DEFAULT_LOAD_FACTOR是一个默认的负载因子,表示当元素数量达到容量的75%时,触发扩容。
通过这些代码示例,我们可以稍微了解到HashMap内部的一些核心算法。这些算法保证了HashMap在面对不同场景时能够保持高效的性能,同时保证了数据结构的稳定性。深入了解这些算法不仅有助于我们理解HashMap的内部工作原理,还能够在需要的情况下更好地优化我们的代码。希望通过这次的有趣之旅,大家对HashMap内部的奥秘有了更深层次的理解。