













人类花了134年才发现Norn细胞,AI用了6周就做到了!
来自斯坦福大学的研究人员使用数百万个真实细胞的化学和基因组成作为原始数据训练了一个AI大模型,
通过自行学习到的知识,模型可以将之前从未见过的细胞归类为1000多种类别中的某一种,Norn细胞就是其中之一。
而此时,距离科学家发表Norn细胞的发现才过去短短几个月,也许早一点训练模型的话,这个功劳说不定就被AI给抢了!
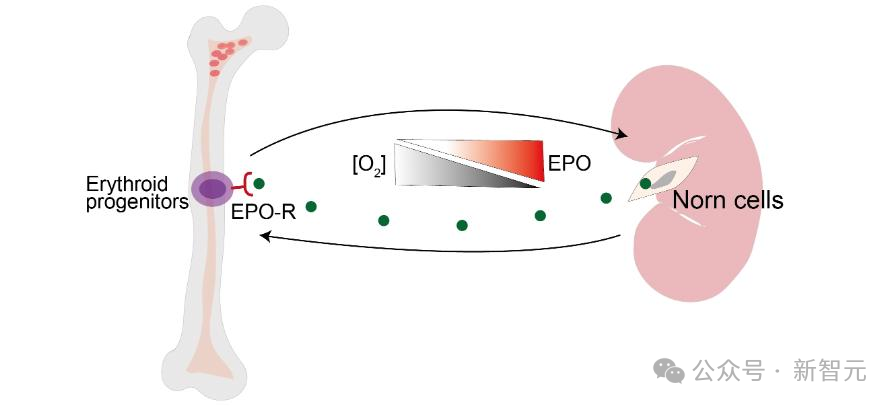
Norn细胞是一种肾细胞,可以感知缺氧状态。当人体氧气含量迅速下降时,Norn细胞就会出来抢救,通过消耗铁来合成促红细胞生成素(Epo)。
这可是能救命的能力,于是最初的发现者以传说中控制人类命运的北欧神灵来命名了这个细胞。
而对于Norn细胞及其相关机制,至今仍是非常重要的研究,比如Nature上动不动就要揭开人家的面纱:


Norn细胞产生的Epo是氧稳态的主要调节因子,在红细胞的生成过程中至关重要。
健康状态下,Epo的调控能够保证红细胞按需生成,比如当人处于高海拔或者高强度运动时,红细胞就会增加,满足人体的供氧。
相应的,如果调控出现问题,就会影响人体健康:过低会导致贫血,过高会引起多发性骨髓瘤等疾病。
历经134年的发现
1889年,一位名叫Francois-Gilbert Viault的法国医生从安第斯山脉的一座山上爬下来,从他的手臂上抽血,并在显微镜下检查。
结果显示,Viault的血液中运送氧气的红细胞激增了42%。——于是他发现了人体的一种神秘力量:可以按需制造红细胞。

最早,科学家们推测是激素,称这种激素为促红细胞生成素。七十年后,研究人员在过滤了670加仑尿液后终于发现了这种促红细胞生成素。
又过了大约50年后,也就是去年,以色列的生物学家宣布,他们发现了一种罕见的肾细胞,当氧气降得太低时,它就会产生激素,——这就是掌管人类命运的Norn细胞。

从1889年到2023年,人类花了整整134年的时间才发现Norn细胞。
但是在去年夏天,斯坦福大学研究者训练的AI模型,在短短六周内就发现了Norn细胞。
生物学基础模型
研究人员训练了一个类似于ChatGPT的模型,所不同的是,ChatGPT吃的是互联网上的数十亿条文本,而他们的模型喂的是数百万个真实细胞的化学和基因组成的原始数据。
研究人员没有告诉模型这些数据的含义,也没有解释不同种类的细胞具有不同的生化特征(哪些细胞在我们的眼睛中发光,或者哪些细胞产生抗体)。
模型自行处理数据,根据它们在广阔的多维空间中彼此的相似性创建所有细胞的模型。
当训练完成时,模型已经学到了惊人的知识,可以将以前从未见过的细胞归类为1000多种不同类型之一,这其中就包括Norn细胞。
斯坦福大学的计算机科学家Jure Leskovec表示,“这很了不起,因为从来没有人告诉模型肾脏中存在Norn细胞”。
斯坦福的这个模型是最近的几个生物学基础模型之一,它们不仅仅是整理生物学家收集的信息,而是正在发现基因如何工作以及细胞如何发育。
随着模型规模的扩大、实验室数据和计算能力的增加,科学家们预测会得到更深刻的发现。
比如揭示有关癌症和其他疾病的秘密,或者找出将一种细胞变成另一种细胞的秘诀。
用AI来理解生物学是一个有争议的问题。不过乐观的科学家认为,基础模型甚至能够解决当前最大的生物学问题:是什么将生命与非生命区分开来?
心脏细胞和鼹鼠

长期以来,生物学家一直试图了解人体内的不同细胞如何利用基因来做维持生命所需的许多事情。
大约十年前,研究人员开始了工业规模的实验,从单个细胞中捞出遗传片段。
波士顿儿童医院(Boston Children's Hospital)的医师Christina Theodoris博士阅读了谷歌工程师在2017年为语言翻译制作的AI模型,——也就是大名鼎鼎的Transformer。

Transformer拥有翻译以前从未见过的句子的能力,Theodoris博士于是设想一个类似的模型是否可以自学,以理解细胞图谱中的数据。
2021 年,她努力寻找一个实验室来支持自己的想法,虽然遭到了很多质疑,但最终波士顿Dana-Farber癌症研究所的计算生物学家Shirley Liu给了她机会。

Christina Theodoris
Theodoris博士从106项已发表的人体研究中提取数据,总共包括3000万个细胞,她将这些数据全部喂给了一个名为GeneFormer的模型。
模型深入学习了人类基因在不同细胞中的行为。例如,它预测关闭一个名为TEAD4的基因会严重破坏心肌细胞,这与Theodoris团队的实际测试相符。
在另一项测试中,Theodoris和同事为模型提供了心跳节律有缺陷的人以及健康人的心脏细胞数据,并询问模型如何修改不健康的细胞。
GeneFormer建议降低某四个基因的活性,而这四个基因以前从未与心脏病相关。
Theodoris团队遵循了模型的建议,在参加实验的病例中,有一半获得了改善。
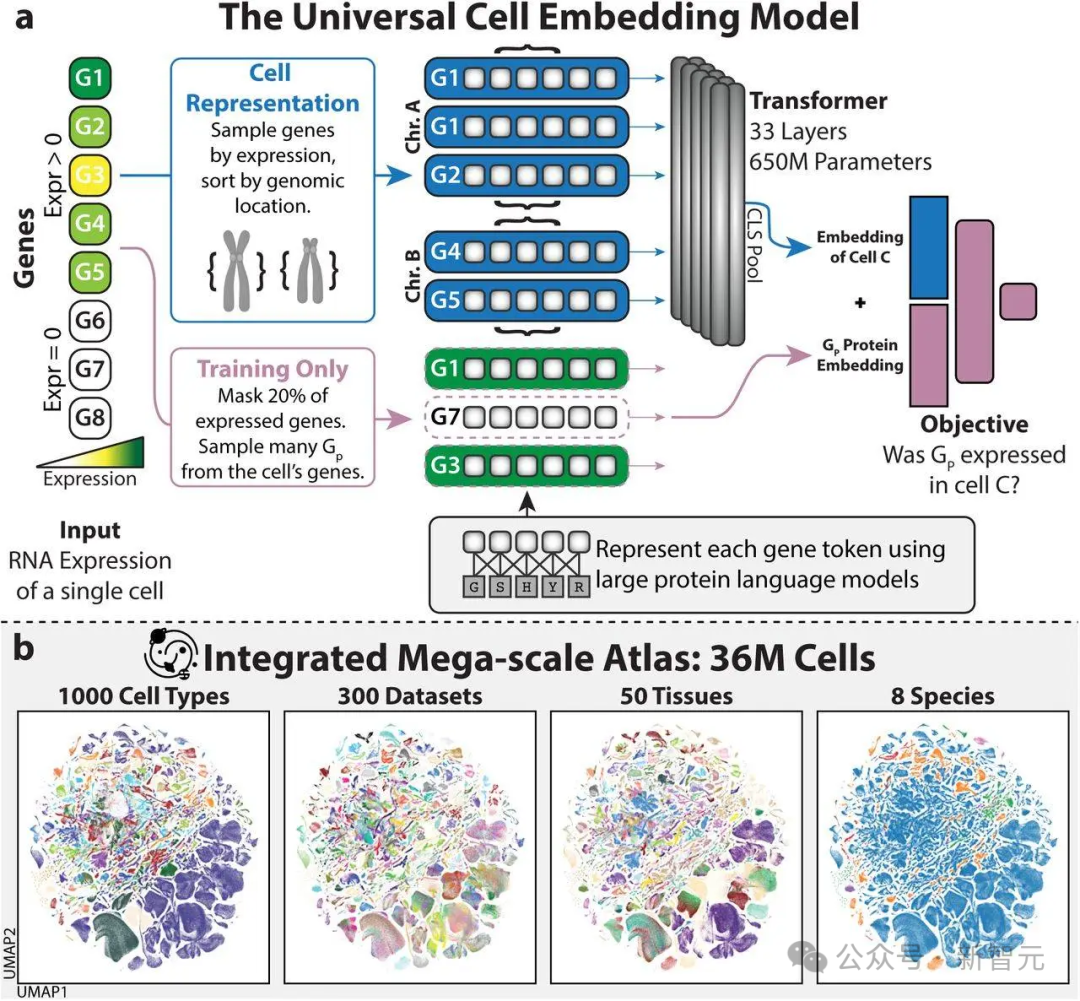
斯坦福大学团队在帮助建立了世界上最大的细胞数据库之一(CellXGene)后,开始研发基础模型。
从去年8月开始,研究人员利用数据库中的3300万个细胞的数据训练模型,并重点关注一种称为信使RNA的遗传信息。他们还向模型提供了蛋白质的三维结构。

据此,模型学会了如何根据基因的开启和关闭方式对一千多种类型的细胞进行分类。
研究人员将这个基础模型命名为通用细胞嵌入(Universal Cell Embedding,UCE),吸收了几代生物学家发现的细胞类型数据。
此外,UCE还自学了一些关于细胞如何从单个受精卵发育的重要知识。UCE认识到,体内的所有细胞都可以根据它们在早期胚胎中三层中的哪一层来进行分组。
帮助开发UCE的斯坦福大学的生物物理学家Stephen Quake表示,“它基本上重新发现了发育生物学”。
UCE还能够将知识转移到新物种上。通过一种从未见过的动物(比如裸鼹鼠)的细胞遗传图谱,UCE可以识别出许多细胞类型。
“你可以带来一个全新的生物体——鸡、青蛙、鱼,随便什么——把它放进去,你会得到一些有用的东西。”
——好家伙,新时代的黑暗料理。
在UCE发现Norn细胞后,Leskovec博士和他的同事们在CellXGene数据库中查看了细胞的来源,因为根据数据,模型有可能在肾脏外发现了Norn细胞。
人们之前并没有在其他地方发现促红细胞生成素激素。但可能存在一种新细胞,像Norn细胞一样感知氧气。
换句话说,UCE可能在生物学家之前发现了一种新型细胞。
细胞互联网

当然了,像所有大模型一样,生物模型有时也会出错。
牛津大学的计算生物学家Kasia Kedzierska和她的同事们最近对GeneFormer和另一个基础模型scGPT进行了一系列测试。
他们向模型展示了以前从未见过的细胞图谱,并让模型执行诸如细胞分类等任务。这些模型在某些任务上表现良好,但在一些情况下表现不如普通的程序。
虽然Kedzierska博士对这些模型寄予厚望,“但就目前而言,在没有正确了解其局限性的情况下,不应该开箱即用。”
相对于大语言模型使用互联网数据不断改进自身,生物模型能得到的新数据量(细胞图谱)是较小的,Kedzierska博士想要一个完整的细胞互联网。
随着更大的细胞图谱上线,更多的细胞正在路上。
科学家们同时也在收集不同类型的数据,比如对粘附在基因上的分子进行分类,或者拍摄细胞照片来表明蛋白质的精确位置。
科学家们还在开发工具,让基础模型将自己学到的东西与生物学家已经发现的东西结合起来。
所有这些信息都将作为基础模型的养料,使它们越来越强大。

有了足够的数据和计算能力,科学家们最终可能会创建出一个完整的细胞数学表示,——虚拟细胞。
这对生物学领域来说将是巨大的革命,从培养皿,转移到了计算机。
也许,AI正在学着理解生命的意义。
























