












OpenAI 的 Sora 在今年 2 月横空出世,把文生视频带向了新阶段。它能够根据文字提示生成超现实场景。Sora 的可适用人群受限,但是在各媒体平台上,Sora 的身影无处不在,大家都在期待着使用它。
在前几天的访谈中,三位作者透露出 Sora 的更多细节,包括它处理手部时仍然存在困难,但正在优化。他们也对 Sora 更多的优化方向进行了阐述,要让用户能够对视频画面有更加精准的控制。不过,短期内,Sora 并不会对公众公开。毕竟 Sora 能够生成与现实十分接近的视频,这会引发很多问题。而正因如此,它还需要更多的改进,人们也需要更多时间来适应。
不过不用气馁,这个短期可能不会太久。OpenAI 首席技术官 Mira Murati 接受了华尔街日报科技专栏作家 Joanna Stern 的采访。她在谈到 Sora 何时推出时,透露道 Sora 将于今年推出,大家可能要等几个月,一切都取决于红队的进展情况。
OpenAI 还计划在 Sora 中加入音频生成的功能,让视频生成效果更加逼真。接下来,他们也会继续优化 Sora,包括帧与帧之间连贯性、产品的易用性以及成本。OpenAI 也希望添加用户编辑 Sora 生成视频的功能。毕竟 AI 工具的成果并不是百分百准确。如果用户能够在 Sora 的基础上进行再创作,想必会有更好的视频效果和更准确的内容表达。
当然,技术解读上的深入浅出只是采访的一部分,另一部分始终围绕着安全、担忧这样的大众话题。比如,一段 20 秒的 720p 视频,不需要几个小时的生成时间,只要几分钟,Sora 在安全方面又将采取怎样的举措?
采访中,主持人还刻意将话题引到 Sora 训练数据上,Mira Murati 表示,Sora 接受过公开可用和许可数据的训练。当记者追问是否用到了 YouTube 上的视频时,Mira Murati 表示自己不是很确定。记者又追问是否用到了 Facebook 或者 Instagram 上的视频?Mira Murati 回答道如果它们是公开可用的,可能会成为数据地一部分,但我不确定,我不敢打包票。
此外她还承认 Shutterstock(是一家美国图片库、图片素材、图片音乐和编辑工具供应商) 是训练数据的来源之一,也强调了他们的合作关系。
不过看似一场普通的采访,但也引来了众多争议,很多人指责 Mira Murati 不够坦诚:

还有人从微表情推测 Murati 在说谎,表示道「记住不要让自己看起来像是在说谎。」
「我只是好奇,作为 OpenAI 的 CTO 居然不知道使用了什么样的训练数据。这不是在明目张胆的撒谎吗?」
「作为这样一家公司的首席技术官,她怎么能不准备好回答这么基本的问题呢?让人摸不着头脑...」
还有人认为 Murati 并没有说谎,也许 Facebook(FB)真的允许 OpenAI 使用部分数据。
但这种说法立马遭到反驳「Facebook 是疯了吗?这些数据对 Facebook 来说绝对是无价的。为什么他们要把数据卖给或授权给他们最大的竞争对手,这实际上是他们在 GenAI 竞赛中唯一的竞争优势。」
显然,很多人都认为 Murati 没有说实话:「作为 OpenAI 的首席技术官,当被问及 Sora 是否接受过 YouTube 视频的训练时,她却表示自己不确定,并拒绝讨论有关训练数据的进一步问题。要么是她对自己的产品相当无知,要么是在说谎 —— 无论哪种方式都非常可恶。」
这就不得不将话题引入到另一个层面:版权问题。一直以来,OpenAI 深受数据版权的困扰,前段时间,《纽约时报》一纸诉状将 OpenAI 告到法庭,起诉书中《纽约时报》列出了 GPT-4 输出「抄袭」《纽约时报》的「证据」,GPT-4 的许多回答与《纽约时报》的报道段落几乎完全一致。
数据监管问题该如何解决?斯坦福教授曼宁表示「目前最简单但最有用和最合适的 AI 监管之一是要求模型提供者记录他们使用的训练数据。欧洲议会刚刚通过并批准的《人工智能法案》也强调了这一点。」
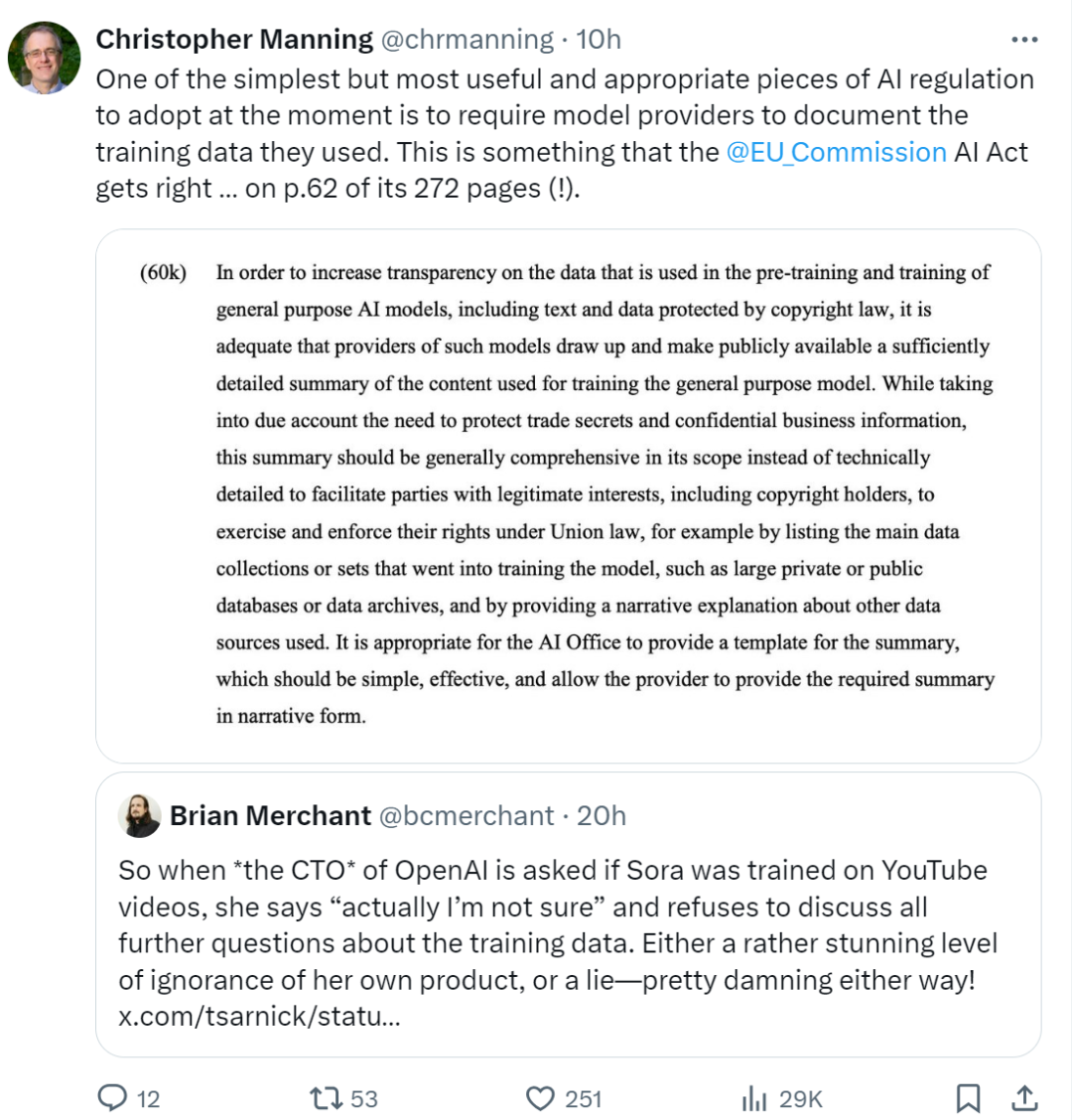
图源:https://twitter.com/chrmanning/status/1768311283445796946
OpenAI 到底使用了什么数据来训练 Sora,现在看来,这座巨大的冰山已经露出了一角。这次采访除了大家关心的数据问题,还有更多信息值得大家一看。
以下是这次采访的主要内容,我们做了不变更原意的编辑:

记者:我被人工智能生成的视频震撼了,但我也担心它们的影响。所以我请 OpenAI 来做一期新的视频,并和 Murati 坐下来解答一些困惑。Sora 是如何工作的?
Mira Murati:它从根本上说是一种扩散模型,这是一种生成模型。它从随机噪声开始创建一个图像。如果是电影制作,人们必须确保上一帧延续到下一帧,物体之间保持一致性。这就给你一种现实感和存在感。如果你在帧之间打破它,你就会断开,现实就不存在了。这就是 Sora 做得很好的地方。
记者:假如我现在给出 prompt:「纽约市人行道上的一名女性视频制作人手里拿着一台电影摄像机。突然,一个机器人从她手中偷走了照相机。」

Mira Murati:你可以看到它并没有非常忠实地遵循提示。机器人并没有把相机从她手中拽出来,反而这个人变成了机器人。这还有很多不完美的地方。
记者:我还注意到了一件事,即当汽车经过时,它们会改变颜色。
Mira Murati:是的,所以虽然这个模型很擅长连续性,但它并不完美。所以你会看到黄色的出租车从框架中消失了一会儿,然后它以不同的形式回来了。
记者:那我们可以在生成后下达「让出租车保持一致,让它回来」这样的指令吗?
Mira Murati:现在是没有办法的,但是我们正在为此而努力:怎么把它变成人们可以编辑的、用来创造的一个工具。
记者:你觉得下面这段视频的 prompt 是什么?

Mira Murati:一头公牛在瓷器商铺中吗?可以看到它在不停地踩,但是没有任何东西破碎。其实这应该是可以预测的,我们未来会提升稳定性和可控性,让它更准确地反映出你的意图。
记者:然后还有一个视频,左边的女人在一个镜头中看起来大概有 15 个手指。

Mira Murati:手实际上有他们自己的运动方式。而且很难模拟手的运动。
记者:视频中的人物嘴巴有动作,但是没有声音。Sora 有在这一方面做功课吗?
Mira Murati:目前确实是没有声音的,但未来一定会有的。
记者:你们用了哪些数据来训练 Sora?
Mira Murati:我们使用了公开可获得的数据和许可数据。
记者:比如 YouTube 上的视频?
Mira Murati:这我不是很确定。
记者:那 Facebook 或者 Instagram 上的视频?
Mira Murati:如果它们是公开可用的,可能会成为数据地一部分,但我不确定,我不敢打包票。
记者:那 Shutterstock 呢?我知道你们和他们有协议。
Mira Murati:我只是不想详细说明所使用的数据,但它是公开可获得的或获得许可的数据。
记者:生成一段 20 秒的 720p 视频需要多长时间?
Mira Murati:根据 prompt 的复杂性,可能需要几分钟。我们的目标是真正专注于开发最好的能力。现在我们将开始研究优化技术,以便人们可以低成本使用它,使它易于使用。
记者:创造这些作品,肯定需要消耗大量的算力。与 ChatGPT 响应或动态图像相比,生成这样的东西需要多少算力?
Mira Murati:ChatGPT 和 DALL・E 是为公众使用它们而优化的,而 Sora 实际上是一个研究输出,要贵得多。我们当时不知道最终向公众提供它时到底会是什么样子,但我们正试图最终用与 DALL・E 相似的成本提供它。
记者:最终是什么时候呢?我真的很期待。
Mira Murati:肯定是今年,但可能是几个月后了。
记者:你觉得是在 11 月选举前还是后呢?
Mira Murati:这是了一个需要慎重考虑处理错误信息和有害偏见的问题。我们也不会公布任何可能会影响选举或其他问题,我们没有把握的东西。
记者:有什么东西是不能生成的。
Mira Murati:我们还没有做出这些决定,但我认为我们的平台将会保持一致。所以应该类似于 DALL・E,你可以生成公众人物的图像。他们会有类似的 Sora 政策。现在我们正处于探索模式,我们还没有弄清楚所有的限制在哪里,以及我们将如何围绕它们。
记者:那裸体呢?
Mira Murati:你知道的,有一些创造性的设置,艺术家可能想要有更多的控制。现在,我们正在与来自不同领域的艺术家和创作者合作,以弄清楚该工具应该提供什么样的灵活性。
记者:你如何确保测试这些产品的人不会被非法或有害的内容吞噬?
Mira Murati:这当然很困难。在早期阶段,这是 Red Teaming(红队测试)的一部分,你必须考虑到它,并确保人们愿意并能够做到这一点。当我们与承包商合作时,我们会更深入地了解这一过程,但这无疑是困难的。
记者:我们现在正在嘲笑这些视频(生成效果不好的视频),但是当这类技术影响到工作时,视频行业的人们可能在几年后就不会笑了。
Mira Murati:我认为这是一种扩展创造力的工具,我们希望电影行业的人们,无论在哪里的创作者,都能参与其中,告知我们如何进一步开发和部署它。此外,当人们贡献数据等时,使用这些模型的经济学是什么。
记者:从所有这些技术中可以清楚地看出,技术将很快变得更快、更好,而且广泛可用。到时,怎么将真实视频和 AI 视频区分开?
Mira Murati:我们也在研究这些问题,包括给视频加水印。不过我们需要先搞清楚内容来源,人们如何区分真实内容、现实中发生的事情和虚假内容,这也是我们还没有部署这些系统的原因,大规模部署之前要先解决这些问题。
记者:有你这些话就能安心点了。不过,人们还是非常担心硅谷筹集资金创造 AI 工具,还有他们对金钱和权利的野心会危及人类的安全。
Mira Murati:平衡利润和安全并不是真正的难题,真正困难的部分是搞清楚安全与社会问题,这是我坚持下去的真正原因。
记者:这个产品确实让人惊艳,但也引发不少担忧,我们也讨论过了,真值得吗?
Mira Murati:绝对值得。AI 工具将扩展我们的知识和创造力、集体想象力、做任何事情的能力。在这个过程中,找到将 AI 融入日常生活的正确道路,也是极其困难的,但我认为这绝对值得一试。
AI 时代,第一是人才,第二是数据,第三是算力。OpenAI 在储备了众多人才的同时,该如何解决数据问题,还需要时间给出答案。






















