













译者 | 朱先忠
审校 | 重楼

简介
模型合并是一种将两个或多个LLM合并为单个模型的技术。这是一种相对较新的实验性方法,可以以低廉的资金投入来创建新模型(不需要GPU)。模型合并工作出奇地好,而且在Open LLM排行榜上先后出现了许多基于模型合并技术的最先进的模型。
在本教程中,我们将使用开源的MergeKit库来实现模型合并。更具体地说,我们将回顾四种合并方法,并提供相应的配置示例。然后,我们将使用MergeKit创建我们自己的模型——Marcoro14-7B-slerp,它也成为了Open LLM排行榜上表现最好的模型之一(02/01/2023)。
本文相应的示例项目源码可在GitHub和Google Colab上获得。当然,我也推荐您使用我本人修改的自动笔记本程序LazyMergekit来更轻松地运行MergeKit。
合并算法
在本节中,我们将重点介绍目前在MergeKit中实现的四种方法。请注意,还有其他一些算法,如线性算法和任务算术算法。如果您对模型合并的论文感兴趣,我推荐您阅读一下Hugging Face上的一组与此相关的优秀论文集。
1.SLERP算法
球面线性插值(SLERP:Spherical Linear Interpolation)是一种用于在两个矢量之间进行平滑插值的方法。这种算法保持一个恒定的变化率,并保留向量所在的球形空间的几何特性。
与传统的线性插值相比,有几个原因让我们更喜欢SLERP。例如,在高维空间中,线性插值可能导致插值向量的大小减小(即,它减小了权重的比例)。此外,权重方向的变化通常代表比变化幅度更有意义的信息(如特征学习和表示)。
SLERP算法的实现基于以下步骤:
- 将输入矢量规范化为单位长度,确保它们表示方向而非幅度。
- 使用它们的点积计算这些矢量之间的角度。
- 如果矢量几乎共线,则默认为进行线性插值以提高效率。否则,SLERP基于插值因子t(第一个矢量中t=0的情况占100%,对于模型2则t=1的情况占100%)和矢量之间的角度来计算比例因子。
- 这些因子用于对原始向量进行加权,然后对原始向量求和以获得插值向量。
- SLERP是目前最流行的合并方法,但它一次只能合并两个模型。不过,仍然有可能分层组合多个模型,如Mistral-7B-Merge-14-v0.1(https://huggingface.co/EmbeddedLLM/Mistral-7B-Merge-14-v0.1)模型中所使用的情形。
一种SLERP的配置示例如下所示:
这是一个经典的SLERP配置,应用于两个模型的每一层。请注意,我们为插值因子t输入值的梯度。自关注层和MLP层的参数将分别使用OpenPipe/mistral-ft-optimized-1218和mlabonne/NeuralHermes-2.5-mistral-7B的不同组合。其他层则是使用了两个模型的50/50的混合比例。
您可以在Hugging Face Hub上找到此最终模型mlabonne/NeuralPipe-7B-Serrp。
2.TIES算法
Yadav等人在他们的论文中介绍了TIES-Merging算法,它旨在将多个特定于任务的模型有效地合并为一个多任务模型。这种方法解决了模型合并中面临的两个主要挑战:
- 模型参数中的冗余:它识别并消除特定任务模型中的冗余参数。这是通过关注微调过程中所做的更改来实现的,识别前k%最显著的更改,并丢弃其余的更改。
- 参数符号之间的分歧:当不同的模型建议对同一参数进行相反的调整时,就会出现冲突。TIES合并通过创建一个统一的符号向量来解决这些冲突,该向量表示所有模型中最主要的变化方向。TIES合并共分为以下三个步骤:
- 修剪(Trim):通过只保留一小部分最重要的参数(密度参数)并将其余参数重置为零,减少特定任务模型中的冗余。
- 选择符号(Elect Sign):通过根据累积幅度的最主要方向(正或负)创建统一的符号向量,解决不同模型之间的符号冲突。
- 不联合合并(Disjoint Merge):对与统一符号向量对齐的参数值求平均值,不包括零值。
与SLERP算法不同,TIES算法可以一次合并多个模型。
一种TIES的配置示例如下所示:
使用此配置,我们使用Mistral-7B模型作为基础模型来计算增量权重。我们合并了同样的两个模型:mistral-ft-optimized-1218(占50%)和NeuralHermes-2.5-mistral-7B(占30%),并进行了规范化。这里,密度(density)参数意味着我们只保留了每个模型50%的参数(另一半来自基本模型)。
请注意,在上面配置中,权重之和并不等于1,但normalize:true参数将在内部自动对它们进行规范化。此配置的灵感来自OpenHermes-2.5-neural-chat-7b-v--7b的作者提供的参数。
您可以在Hugging Face Hub上找到此最终模型mlabonne/NeuralPipe-7B-ties。
3.DARE算法
由Yu等人于2023年引入的DARE算法使用了一种类似于TIES的方法,主要存在两个方面的区别:
- 修剪(Pruning):DARE随机将微调后的权重重置为其原始值(基础模型的值)。
- 重新缩放(Rescaling):DARE重新缩放权重,以保持模型输出的期望值大致不变。它使用比例因子将两个(或多个)模型的重新缩放权重添加到基础模型的权重中。
MergeKit对该方法的实现使用了两种风格:使用符号选择步骤的TIES(dare_ties)或不使用符号选择步骤的TIES(dare_linear)。
一种DARE的配置示例如下所示:
在这种配置中,我们使用dare_ties合并了基于Mistral-7B的三种不同模型。这一次,我选择了总和为1的权重(总和应该在0.9和1.1之间)。密度参数density比论文中建议的略高(<0.5),但看起来它总是能给出更好的结果(请参考链接https://github.com/cg123/mergekit/issues/26处的有关讨论)。
你可以在Hugging Face Hub上找到mlabonne/Daredevil-7B。这也是本文中最好的合并模型,甚至超过了Marcoro14-7B slerp。
4.Passthrough算法
Passthrough方法与以前的方法有很大不同。通过连接来自不同LLM的层,它可以产生具有极大数量的参数的模型(例如,具有两个7B参数模型的9B)。这些模型通常被社区称为“弗兰肯合并”或“弗兰肯斯坦模型”。
这项技术是极具实验性的,但它成功地创建了令人印象深刻的模型,比如使用两个Llama 2 70B模型的goliath-120b模型。最近发布的SOLAR-10.7B-v1.0模型也使用了同样的想法,在他们的论文中称为深度放大。
一种Passthrough方法的配置示例如下所示:
所得到的弗兰肯合并将具有来自第一个模型的所有32层和来自第二个模型的8个附加层。这就创建了一个总共有40层和8.99B个参数的弗兰肯合并。此配置的灵感来自GML-Mistral-merged-v1。
你可以在Hugging Face Hub上找到mlabonne/NeuralPipe-9B-merged。
合并自己的模型
在本节中,我们将使用MergeKit加载合并配置,运行它,并将生成的模型上传到Hugging Face Hub。
首先,我们直接从源代码安装MergeKit,如下所示:
在下面的代码块中,我们以YAML格式加载合并配置。我们还指定合并模型的名称以供将来使用。您可以复制/粘贴上一节中的任何配置到这里。
这一次,我们将使用两种不同的模型:Marcroni-7B-v3和Mistral-7B-Merge-14-v0.1,并使用SLRP方法将它们合并。我们将配置保存为yaml文件,用作merge命令中的输入。
我们使用以下参数运行merge命令:
- --copy-tokenizer:从基本模型中复制分词器
- --allow-crimes和--out-shard-size:将模型分割成更小的代码片断,这些代码片断可以在低RAM的CPU上计算
- --lazy-unpickle:启用实验性的惰性拆卸器以降低内存使用率此外,一些模型可能需要使用--trust_remote_code标志(Mistral-7B的情况并非如此)。
此命令将下载合并配置中列出的所有模型的权重,并运行所选的合并方法(大约需要10分钟)。
现在,模型已合并并保存在“merge”目录中。在上传之前,我们可以创建一个自述文件,其中包含再现性所需的所有信息。下面的代码块定义了一个Jinja模板,并自动使用合并配置中的数据填充它。
现在,该模型可从Hugging Face Hub上下载到:mlabonne/Marcoro14-7B-slerp。在另一个笔记本电脑中,我们可以使用以下代码在免费的T4 GPU上测试该模型:
我们提出了一个问题“What is a Large Language Model?(什么是大型语言模型?)”,收到了以下输出:
相应的中文意思是:“大型语言模型是一种基于大量文本数据进行训练的人工智能系统。它旨在理解和生成类似人类的语言,预测句子或文档中接下来可能出现的单词或短语。这些模型使用复杂的算法和神经网络架构从数据中学习,并随着时间的推移提高其性能。一些著名的大型语言模型包括有OpenAI的GPT-3和谷歌的BERT”。
看起来效果不错,但我们需要进行一个更全面的评估。目前,对于这种通用模型,已经出现了几个非常有趣的评估工具:
- Chatbot Arena,它能够根据人类投票编制出一个基于Elo的LLM排行榜。
- MT-bench(与上面相同的链接地址),它使用GPT-4作为判断,对一组多回合问题的模型回答进行评分。
- NousSearch基准套件,它聚合了四种评估基准:AGIEval、GPT4ALL、TruthfulQA和Bigbench。其中,GPT4ALL本身包括HellaSwag、OpenBookQA、Winogrande、ARC Easy、ARC Challenge、BoolQ和PIQA等工具。
- Open LLM排行榜,共提供了六种评估基准:ARC、HellaSwag、MMLU、Winogrande、GSM8K和TruthfulQA。
不幸的是,我们无法将我们的模型提交给Chatbot Arena基准测试平台。相反,我选择使用Open LLM排行榜和NousSearch基准进行评估。
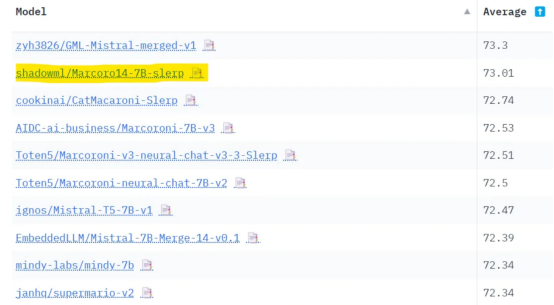
我将我们的模型提交给了Open LLM排行榜(“Submit here!”选项卡)。正如在本文开始所介绍的,它在排行榜上排名为最佳7B参数模型。以下是完整的结果:
 图片由作者本人提供
图片由作者本人提供
Open LLM排行榜的问题在于这些基准是公开的。这意味着,人们可以根据测试数据训练LLM以获得更好的结果。通过合并最好的模型,我们也“污染”了我们自己的结果。可以肯定地假设Marcoro14-7B-slerp模型也受到了“污染”,并且该合并中使用的一些模型已经在测试集上进行了训练。如果你想创建最好的模型——而不是破解排行榜的话,我建议你只使用非合并模型来创建自己的合并。
这就是为什么我们不想只依赖OpenLLM排行榜的原因。对于NousSearch基准套件,借助于LLM AutoEval工具,我可以用一个简单的Colab笔记本来完成自动计算分值。以下是与优秀的OpenHermes-2.5-Mistral-7B模型进行比较的结果:
 图片由作者本人提供
图片由作者本人提供
在每个基准测试中,我们都比这个模型有了显著的改进。请注意,NousSearch基准套件与Open LLM排行榜共享一些任务:ARC Challenge、TruthfulQA、HellaSwag和Winogrande。据我所知,Bigbench是唯一一个100%不同的基准(如果不是这样,请随时联系我)。然而,我们在这次合并中使用的一个模型仍然可以在Bigbench上进行训练。
结论
在本文中,我们介绍了用四种不同算法合并LLM的概念。其中,我们详细介绍了SLERP、TIES、DARE和Passthrough是如何工作的,并提供了相应的配置示例。最后,我们在MergeKit中运用SLERP算法,创建了Marcoro14-7B-SLERP模型,并将其上传到Hugging Face Hub。最终,我们在两个基准套件上都获得了出色的性能:Open LLM Leaderboard(性能最佳的7B模型)和NousSearch。如果你也想创建自己的合并,我推荐你使用我的自动笔记本程序LazyMergekit。
组合多个模型的另一种方法是将它们合并到一个混合专家系统(MoE)架构中。在下一篇文章中,我们将详细讨论如何做到这一点,并创建我们自己的类似Mixtral的模型。最后,如果你喜欢这篇文章,请在Medium和Twitter@mlabonne上关注我吧。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Merge Large Language Models with mergekit,作者:Maxime Labonne






















