人工智能技术的广泛应用正在深刻改变我们的生活。在网络安全领域,基于机器学习的检测技术也应用在许多场景中。随着信息技术的迅猛发展和数字化转型的深入推进,加密技术逐渐成为保障网络安全和数据隐私的核心手段,而基于机器学习的检测技术已成为应对加密威胁的重要方式。
由于网络流量巨大,如果检测模型频繁产生大量警报,将严重干扰安全人员的分析和研判工作。为了解决这个问题,我们可以采用自适应学习技术。这种技术通过从现网中收集实时网络流量,并将其作为训练集的一部分,动态更新模型,从而有效降低模型的误报率,并提高模型的准确率。
1、对比分析
1) 固化模型
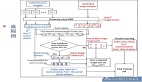
在流量检测领域,由于加密技术的应用越来越广泛,基于传统的明文检测方法失效,但是机器学习算法可以通过对非加密内容数据作为训练数据,从中发现其中规律,进而有效的鉴别恶意流量。而基于机器学习技术的检测方法通常会使用预先收集的正常业务流量(白流量)与恶意加密流量(黑流量)构建训练集,然后通过训练模型进行检测,这样的模型称之为固化模型。然而,经过实际验证发现,由于预先收集的白流量与客户特定场景网络环境的白流量存在差异,固化模型的灵活性与适应性不够,会使模型出现一些误报,从而增加了安全研究人员分析与研判的难度。下图展示了其处理流程:
 图片
图片
2) 自适应模型
为了进一步提高固化模型的实际效果,可以采用自适应模型。这种方法通过在部署位置本地收集客户特定网络环境流量并将其作为训练集的一部分来扩充白流量的数据集,然后训练出的模型可以适应不同现网环境,更好地区分可能出现的恶意加密流量。下图展示了该处理流程:

在自适应模型中,使用历史数据构建的数据集训练模型后,在现网环境中会周期性收集客户现网的白流量(因为客户侧绝大多数的流量都是白流量),而后采用增量学习的方式将其加入到原有模型中,以完成模型的动态更新。自适应模型能够很好地适应客户侧现网流量的变化情况,相比于固化模型,它显著减少了许多误报的问题,检测效果得到了大幅提升。
2、原理解释
在构建自适应模型时,引入了增量学习的概念,这也是构建自适应模型的核心技术。增量学习的目的是学习系统能够不断从新样本中学习新知识,并且能够保留大部分先前学习到的知识。在构建自适应模型的过程中,引入增量学习技术能够在充分学习新环境中的知识的同时,不会遗忘模型学到的历史知识,从而丰富了模型的检测能力。这样的方法使得模型能够不断地适应变化的环境,并持续提升其检测能力。
3、自适应学习面临的技术问题
应用自适应学习技术时,需要解决以下技术问题:
1) 数据分布未知
现网数据可能存在短时间内数据量大且相对单一的情况,因此需要应对未知的数据分布,以保证模型的鲁棒性。
2) 恶意加密流量难获取
在现网流量中获取具有恶意加密流量的数据可能是一项挑战,需要寻找解决方案以获取足够的恶意加密流量进行学习,例如利用模拟攻击、合成数据或其他数据增强技术。
3) 流量不平衡
正常业务流量(白流量)与恶意加密流量(黑流量)在现网流量数据中可能存在极大的不平衡,这需要采用有效的处理方法,如过采样、欠采样、类别权重调整等,以确保模型对各种情况都具有良好的适应性。
4) 设备计算资源限制
现网设备的计算资源有限,因此在实施增量学习时需要考虑性能和效率,以确保在有限的资源下取得最佳效果,可以采用轻量化模型、优化算法或分布式计算等方法来解决该问题。
解决这些技术问题,可以有效应用自适应学习技术,并提高模型的适应性、鲁棒性和性能效果。
4、处理流程
在考虑到上述这些问题后,可以采用以下步骤进行处理:
1) 数据预处理
提取流量中的行为特征,并进行去重、处理缺失值等初步预处理操作,以准备数据用于后续处理。
2) 白流量获取
在现网数据获取阶段,针对复杂的正常业务流量(白流量),通过多时段的随机采样方法,获取新的代表性数据,以确保覆盖流量的多样性和变化性。
3) 黑流量获取
针对难以获取的恶意加密流量(黑流量),利用历史的黑流量数据,采用基于数值扰动的数据增广方法,模拟生成新的黑流量数据,以扩充恶意加密流量的多样性。
4) 参数调整
由于现网数据中的正常业务流量和恶意加密流量可能存在不平衡,根据上一步获取的实时流量数目,基于代价敏感学习,进行类别权重的调整,以消除偏置,使得模型能够平衡地对待不同类别的流量。
5、现网实验结果
在某现网环境下,针对TLS协议的Cobalt Strike检测和Webshell检测,我们进行了固化模型和自适应模型的检测对比,结果如下:
 图片
图片
对于Webshell检测,我们收集了现网中共5万条白流量,并使用固化模型和自适应模型进行检测对比。实验结果显示,固化模型检测结果分数高于50的为1300条,而自适应模型结果仅有140条。(分数高于50分意味着模型预测该条流量是黑流量的可能性大于预测为白流量的可能性)
 图片
图片
对于Cobalt Strike检测,我们同样收集了现网中共5万条白流量,并使用固化模型和自适应模型进行检测对比。实验结果显示,固化模型检测结果分数高于50分的为53条,而自适应模型结果仅有1条。
从测试结果可以看出,采用自适应模型后误报明显减少。这显示自适应模型在现网环境下具有更好的准确性和鲁棒性,能够更有效地识别出真正的威胁,减少了误报的问题。
6、结语
观成科技研究团队一直致力于不断改进和优化人工智能检测模型,以适应不断变化的威胁环境,并提供更准确、可靠的检测方案。针对目前基于预先训练模型的机器学习技术检测恶意流量在现网特定网络环境中存在误报率偏高的现象,引入基于增量学习的自适应学习技术,通过在一定时间周期内提取客户现场的白流量,我们使得原有的固化模型能够学习到最新的流量知识,从而大大减少了误报率,提升了检测能力。