在第十章的时候,我们讨论了批处理——它总是读取一些文件作为输入,产生一些新文件作为输出。这里的输出就是一种“衍生数据”:即,如果有需要,我们可以通过再跑一遍批处理任务获取相同的结果集。从之前章节的讨论我们可以看出,这种思想简单却强大:像搜索引擎、推荐系统、分析系统等很多现代常见的数据系统都是基于这种思想构建的。
然而,在第十章进行讨论时我们有一个很强的假设:输入数据集是有界的——即事先知道输入尺寸——因此批处理的程序知道输入何时结束。举个例子,MapReduce 中非常重要的排序操作,就必须读入所有待排序的输入数据后才能开始排序并输出。这是因为,最后一条数据,没准可能是被需要排在最前面(具有最小的 key),因此不可能过早对数据排序。
但在现实中,很多数据都是无界的且随着时间持续到来的:我们的(各种服务的)用户昨天会产生数据、今天会产生数据,明天也将以同样的方式继续产生数据。除非你关门大吉,否则这些程序将会永无休止地工作,因此我们的数据库永远也不会到达一个“终态”(complete state)。因此,如果使用批处理的思想来处理这种持续来到的数据流,就会引出一个数据集切分的问题:例如,在一天结束时处理这一整天的数据、在每小时结束时处理这一小时的数据等等。
但上述切分+批处理的方式有个问题:太慢了,用户可能等不及。比如按天处理时,则其处理结果只有当这一天结束后,再花些时间去批处理,才能最终看到结果。为了降低这个延迟,我们确实可以用更小的粒度进行处理——比如,每秒进行一次处理。甚而,干脆抛弃时间分片的概念,任意数据到来的时候就触发数据处理逻辑。这就是流式处理(steam processing)背后的基本思想。
通常来说,一个“流”(steam)指的是随时间推移而增量产生的数据。这个概念其实很多地方都有:Unix 中标准输入输出中(stdin、stdout),编程语言中(迭代器),文件系统相关的 API 中(如 Java 的 FileInputStream),TCP 连接中,网络中传输的音视频等等。
在本章中,我们会将事件流(event stream)当做一种数据管理机制:即将我们上一章讨论的批量数据无界化、增量化。我们首先会讨论如何表示、存储和传输数据流。在“数据库和数据流”一节中,我们会探索数据流和数据库的管理。最后,在“处理数据流”一节中,我们将会讨论对这些不间断的数据流进行处理的方法和工具,以及基于其构建应用的一些方法。
事件流的传输
在批处理系统中,任务的输入和输出都是文件(可能是单机文件系统中的、也可能是分布式文件系统中的),那么在流式系统中,承载输入和输出的是什么呢?
在批处理系统中,虽然输入是文件,但第一步也通常是解析成一系列的数据记录(records)。在流式处理的上下中,对应数据记录的实体通常被称为事件(event)。但他们本质上都是一个东西:一段小的、自包含的(self-contained、不引用其他数据)、不可变的某个时间点发生的信息数据。流式系统中的一个事件通常会包含一个时间戳,来标志该事件在某个时钟系统(time-of-day clock)中发生的时间点。
下面举几个事件的例子。事件可以是由用户活动产生的,如浏览网页、网上购物;也可以由机器产生,如周期性的温度传感器、CPU 利用率指标;在使用Unix工具进行批处理一节的例子中,我们提到的 web 服务器中的每一行日志,也是一个事件。
我们在第四章中讨论过数据编码的事情。事件本质上也是数据,因此可以被编码为字符串、JSON 或者二进制形式。只有编码之后,事件才能被存储,如:
- 追加到文件末尾
- 插入到关系表中
- 写到文档数据库里
也只有在编码之后,事件才能够在网络中进行传输,以发送到其他工作节点进行处理。
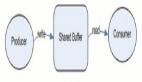
在批处理系统中,一个文件通常是一次写多次读的。类似的,在流式处理系统中,一个事件在被生产者(producer,在不同系统中,也可以称为 publisher 或者 sender)生成之后,可能会被多个感兴趣的消费者(consumer,对应的,也可以称为 subscribers 和 recipients)处理。在文件系统中,文件名可以标识一组数据记录;在流式系统中,相关的事件通常会聚拢到主题(topic)下或者流(stream)中。换句话说,命名后的流类似于文件,但不同的是,流中的是无界数据。
原则上,使用文件或者数据库也足够用以沟通生产者和消费者:
- 生产者将每个产生的事件写入数据存储(date store)中(文件系统或者数据库)
- 消费者定期的去从数据系统中拉取,并和上次拉取比对,看是否有新事件到来
批处理系统在以天为粒度处理数据时,正是用的这种办法。
但是,在放到低延迟的持续数据流的上下文中时,如果存储系统不是专门为此定制的,定时去拉取(polling)数据的代价会变得很高。且,在数据量一定的情况下,你拉取的频次越高,单次拉到新数据的概率就越低,则无效负载也会随之升高。因此,在流式系统中,当有新事件产生时,按需通知消费者会比频发拉取更高效(即推比拉高效)。
传统上,数据库对于这种通知机制支持的并不是很好:虽然关系型数据中的确有触发器(triggers),且可以对数据表中的一些事件(如,新插入一行)做出响应,但响应逻辑中能做的很有限(比如做一致性检查),且通常局限在数据库内部(而不能通知到客户端)。为此,一些专用的工具被开发出来以进行专门的事件通知。
消息系统
通知消费者有新事件产生的一个常见方法是消息系统(messaging system):生产者将事件以消息的形式发送到消息系统,消息系统将其推送给消费者。我们在经由消息传递的数据流一节简单提过消息系统,本节我们将会讨论更多细节。
实现消息系统最简单的方式,就是使用 Unix 管道或者 TCP连接来沟通生产者和消费者。但大部分消息系统不会如此简单。比如,Unix 管道和 TCP 连接都是一对一的发送者和接受者,但成熟的消息系统通常要支持多对多的生产消费——即多个生产者可以将数据发送到一个主题( topic )下,多个消费者可以共通消费这个 topic。
但在这种发布/订阅(publish/subscribe)模式之下,不同具体的系统实现方式千差万别。没有一种方案能满足所有需求。为了理解不同系统的实现,我们可以带着两个问题去考察各个系统:
- 如果生产者的生产速度快于消费者的消费速度会发生什么?通常来说,有三种选择:丢掉部分消息、缓存多余消息、背压阻止新消息(backpressure,也被称为流控,即在消费者处理完之前,阻止生产者产生更多数据)。具体来说,Unix 管道和 TCP 都使用背压的方式:他们都有一个很小的缓冲区(Buffer),如果缓冲区被填满,则发送方阻塞直到接收方消费掉缓冲区中一些消息,以空出新的位置。如果使用队列缓冲消息,则需要了解当数据量增大到一定地步之后该怎么办?当内存装不下数据之后是宕机还是刷到硬盘上?如果刷到硬盘上,硬盘的访问将如何影响消息系统的性能?
- 当系统中一些节点短时间下线会发生什么?会有消息因此而丢失吗?和数据库一样,要想保证持久性,是需要付出一些代价的:如将数据写到硬盘中、将数据冗余到其他节点上等等。如果你能够接受偶尔丢一些数据,那在同样的硬件配置下,你或许能获得更高的吞吐和更低的延迟。
是否能够接受消息丢失取决于应用层。例如,对于一些周期性上报的传感器读数来说,偶尔的一两个采点的丢失影响不大, 因为后面的数据会很快的报上来。然而需要注意,如果消息大面积的丢失,可能也很难立即看出来。另外,如果你的目标是对所有到来的事件进行计数,则每条信息都要可靠的传输,因为任何一条信息的丢失都会导致计数错误。
我们在上一章中讨论过批处理的一个非常友好的性质——提供很好的容错保证。即,所有失败的子任务会自动的进行重试、所有失败任务的部分输出会被丢弃。这种做法会让系统看起来像没有发生过任何故障一样,从而可以让应用层大大简化编程模型(这些分布式故障如果系统不处理,就要应用层自己来处理)。在本章稍后的部分,我们会探讨如何在流式处理的上下文中提供类似的保证。
生产者到消费者的直接消息
很多消息系统并不借助中间系统节点,而直接使用网络来沟通生产者和消费者双方:
- UDP 多播。UDP 多播广泛用在金融系统的数据流中,如对时延要求很高的股票市场中的大盘动态。尽管 UDP 本身是不可靠的,但是可以在应用层增加可靠性算法(类似在应用层实现 TCP 的一些算法),对丢失的信息进行恢复(生产者需要记住所有已发送的消息,才可以按需进行重传)。
- 无 broker 的消息队列。像 ZeroMQ 和 nanomsg 等不使用消息 broker 的以库形式提供的消息队列,依赖 TCP 或者 IP 多播等方式实现了支持发布订阅的消息队列。
- StatsD 和 Brubeck。这两个系统底层依赖 UDP 协议进行传递消息,以监控所有机器、并收集相关数据指标。(在 StatsD 协议中,只有事件都收到,counter 相关指标才会正确;使用 UDP 就意味着使用一种尽可能正确的保证)。
- Webhooks。如果消费者在网络上暴露出了一个服务,则生产者可以通过 HTTP 或者 RPC 请求(参见经由服务的数据流:REST 和 RPC)来将数据打到消费者中。这就是 webhooks 背后的思想:一个服务会向另一个服务进行注册,并在有事件产生时向该服务发送一个请求。
这种直接消息系统在其目标场景中通常能够工作的很好,但需要应用层代码自己承担、处理消息丢失的可能性。此外,这些系统能够进行的容错很有限:虽然这些系统在检测到丢包后会进行重传,但它们通常会假设生产者和消费者都一直在线(这是一个很强的假设)。
如果消费者由于某种原因下线了,它可能会错过一些消息。有些协议会允许生产者重发失败的消息,但如果生产者也挂了,这种方法也无济于事——生产者会丢掉保存有需要进行重试的消息缓存。
这本质上是因为,这些没有 broker 的消息系统多表现为库的形式,本身是没有状态的。如果没有状态,就没有办法应对消息传输过程中生产者、消费者宕机重启的故障。这也是引入 broker 的初衷,但因此消息系统也会变的更加重。
消息代理
一种广泛使用的替代方案就是使用消息代理(message broker,也称为消息队列)来发送消息。消息代理本质上是一种专门为消息数据优化过的数据库。它通常以进程的形式跑在服务器上,生产者和消费者作为客户端与之通信。生产者将消息写入消息代理,消费者从其中读取以进行消费。
通过引入一个消息数据存储代理,消息系统可以更加容易的对客户端(包括生产者和消费者)的来来去去(连接、失联和宕机)进行容错。这样,数据的持久化职责被转移到了消息代理上。有些系统中的消息代理将数据保存在内存中,那么宕机重启就仍然有问题;但另一些系统中的消息代理就会把消息持久化到硬盘(通常可配置)中,则就可以容忍宕机问题。如果遇到慢的消费者,就可以使用无限队列的方式(而不是丢消息或者背压)对没来得及消费的数据进行缓存,当然通常来说,能够存多少数据通常也会以配置的方式交给用户去选择。
使用消息代理的另外一个原因是消费者通常是异步消费的:即当发送一条消息后,生产者等待消息代理确认收到(缓存或者持久化)就会结束,而不会去等待这条消息最终被消费者所消费。而消息最终被消费者所消费,会发生在将来的某个时间点——大多数很快,比如几秒内,但如果出现大量消息积压时,这个时间也可能会很久。
对比消息代理和数据库
有一些消息代理甚至能够参与两阶段提交(使用 XA 或者 JTA,参见 实践中的分布式事务 )。这种功能让消息代理看起来非常像数据库,尽管在实践中他们有一些非常重要的区别:
- 删除过程:数据库会一直保存数据,直到其被显式地删除。然而,大部分的消息代理会在消息被消费后,隐式的对其自动删除。这种类型的消息代理并不适合对数据的长时间存储。
- 尺寸假设:由于消息代理会在消息被消费后将其删除,因此大部分消息代理都会假设其所存数据并不是很多——所有队列都很短。在这样的假设下,如果由于消费者过慢而造成消息在消息代理中堆积(当内存中存不下后可能需要放到硬盘中),则可能造成消息代理的性能降级,所有消息都需要更长时间才能被处理。
- 数据过滤:数据库通常支持二级索引其他一些对数据进行查找的方法,而消息代理也通常会支持对某个 topic 下符合某种条件的数据进行订阅。虽然机制不同,但在本质上,两者都支持客户端读取其所关心数据的方法。
- 数据隔离:当对数据库进行查询时,其结果通常是基于某个时间点的快照;换句话说,如果另外一个客户端在其发起查询之后插入了一些数据,第一个客户端通常是看不到这些更新的(这要“归功于”数据库事务的隔离级别),除非其进行再次查询。与之相对,消息代理虽然不支持任意条件的查询,但当数据发生变化时(新的事件到来),系统会将其立即告知消费者。
以上都是传统视角下的消息代理,这些语义被抽象成了像 JMS 和 AMQP 之类的协议,并且为 RabbitMQ、ActiveMQ、HornetQ、Qpid、TIBCO 企业消息服务、IBM MQ、Azure Service Bus 和 Google Cloud Pub/Sub 等系统实现。
多消费者
当多个消费者同时消费一个 topic 下的数据时,有两种主要的消费方式,
- 负载均衡(Load Balancing,互斥)
每个消息被投递给其中一个消费者进行消费。即所有的消费者会共同处理一个 topic 下的所有消息。消息代理可能以任意策略将消息分发给不同消费者。当每条消息消费代价很高,用户想通过增加消费者的数量来并行消费某个 topic 时,这种方式很有用。(在 AMQP 中,可以通过多个客户端消费同一个队列来实现负载均衡;在 JMS 中,这种方式被称为共享订阅) - 扇出(Fan-out,独立)
每个消息都被发送到所有消费者。扇出的方式会让每个消费者独立的对同样的数据进行消费,而不会互相影响。这种方式有点类似于批处理中对于同一份数据进行多次处理。(JMS 中称为 topic subcription;AMQP 中称为 exchange bindings)
 负载均衡和扇出模式对比
负载均衡和扇出模式对比
两种消费模式也可以组合起来:如有两组用户都订阅了某个 topic,组间进行独立消费(fan-out)、组内进行互斥消费(load balancing)。
确认和重传
消费者可能会在任意时刻宕机,因此可能会出现:消息代理将消息发送给了消费者,但是消费者却没有对其进行消费或者仅进行了部分消费,就宕机了。为了保证该消息不丢,消息代理使用了一种确认机制(类似 TCP 中的 ack):每个消费者必须显式地告诉消息代理它消费完了消息,这样消息代理才能安全的将消息从队列中删除。
如果消息代理和消费者之间的链接关闭或者超时了,消息代理仍然没有收到确认,则会假设消息没有被处理,并且重新给另一个消费者发送消息。但此时有可能出现,在重发之前消息实际已经被处理过了,只是确认消息由于网络的原因丢失了。在这种情况下,需要消费者进行幂等消费。
在负载均衡模式下,重传可能会造成消费者处理消息的乱序。在下图中,在没有任何故障时,消费者大体是按照消息的生产顺序来消费的。然而,某一时刻,消费者 2 号在处理消息 m3 时宕机了,此时消费者 1 号正在处理消息 m4。由于迟迟没有等到 m3 的消费确认,消息代理将其重新发送给了消费者 1 号,从而导致消费者 1 号以 m4,m3,m5 的顺序来处理的消息。即,发生了乱序处理。
 负载均衡导致的消息乱序
负载均衡导致的消息乱序
即使消息代理试图以顺序的方式给消费者发送消息(JMS 和 AMQP 都有此类规定),但由于负载均衡和重传机制的组合,乱序消费难以避免。为了避免这个问题,你可以让每个消费者使用单独的队列(即,不用负载均衡功能,也可以理解,毕竟并行总是有代价的)。在每条消息都是互相独立时,乱序消费不是问题;但如果消息间有前后因果依赖,则消息的保序消费非常重要。
参考资料
[1]DDIA 读书分享会: https://ddia.qtmuniao.com/