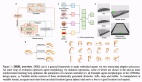
视频游戏是 AI 系统的重要试验场。与现实世界一样,游戏也是丰富的学习环境,具有反应灵敏的实时设置和不断变化的目标。
从早期与雅达利游戏的合作,到人类大师级水平的《星际争霸 II》系统 AlphaStar,谷歌 DeepMind 在人工智能和游戏领域陆续推出过不少影响力研究。
刚刚,谷歌宣布了又一项里程碑式研究:SIMA(Scalable Instructable Multiworld Agent),一种适用于 3D 虚拟环境的通用 AI 智能体。
加州大学欧文分校助理教授 Roy Fox 表示,SIMA 让我们离自主智能体的「ChatGPT 时刻」又近了一步。
谷歌 DeepMind 研究工程师 Tim Harley 表示:「想象有一天,我们可以让像 SIMA 这样的智能体与你和你的朋友一起玩游戏,而不是让你与超人智能体对抗。」
但目前的 AI 系统仍然没有接近人类水平。例如,在《无人深空》游戏中,AI 智能体只能完成人类能完成的 60% 的任务。当研究人员取消人类发出 SIMA 指令的能力时,他们发现该智能体的表现比以前差了很多。
AI 已经不甘心只作 NPC 了
谷歌与八家游戏工作室合作,在九款不同的视频游戏中对 SIMA 进行了训练和测试,包括《无人天空》、《拆迁(Teardown)》、《英灵神殿》和《模拟山羊 3》。

SIMA 产品组合中的每款游戏都是全新的互动世界,包括一系列需要学习的技能,从简单的导航和菜单使用,到开采资源、驾驶飞船或制作头盔。

同时,谷歌还使用了四个研究环境 — 包括使用 Unity 构建的一个名为「建筑实验室」的新环境。在这个实验室中,智能体需要用积木搭建雕塑,以测试对物体的操作能力以及对物理世界的直观理解。
然后,谷歌在游戏组合中记录成对的人类玩家,其中一名玩家观察并指导另一名玩家,以捕获语言指令。随后让玩家自由玩游戏,重新观察他们的行为,并记录下可能导致其游戏行为的指令。
所有这些都被提供给 SIMA ,以学习预测屏幕上接下来会发生什么。通过在不同的游戏世界学习,SIMA 捕捉到了语言与游戏行为之间的联系。
「这项研究标志着首次有 AI 智能体证明自己能够理解各种游戏世界,并能像人类一样按照自然语言指令在游戏世界中执行任务。」谷歌表示。
SIMA 并不只是一个由 AI 驱动的 NPC ,而是游戏中影响结果的另一个「玩家」。
谷歌还指出,SIMA 的研究并不是为了获得高分。对于 AI 系统来说,学会玩一款视频游戏固然是技术层面的重大突破,但学会在各种游戏环境中遵从指令,可以让 AI 智能体在任何环境中发挥更大的作用。
在技术报告中,谷歌也展示了如何通过语言界面将高级 AI 模型的能力转化为现实世界中有用的行动。

技术报告:
https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/sima-generalist-ai-agent-for-3d-virtual-environments/Scaling%20Instructable%20Agents%20Across%20Many%20Simulated%20Worlds.pdf
SIMA:通用 AI 智能体来了
SIMA 的组件包括预训练好的视觉模型,以及一个包含内存并输出键盘和鼠标操作的主模型,如下图所示。
具体来讲,SIMA 包含了一个专为精确图像语言映射而设计的模型和一个预测屏幕上接下来会发生什么的视频模型。谷歌根据 SIMA 产品组合中特定于 3D 设置的训练数据对这两个模型进行了微调。
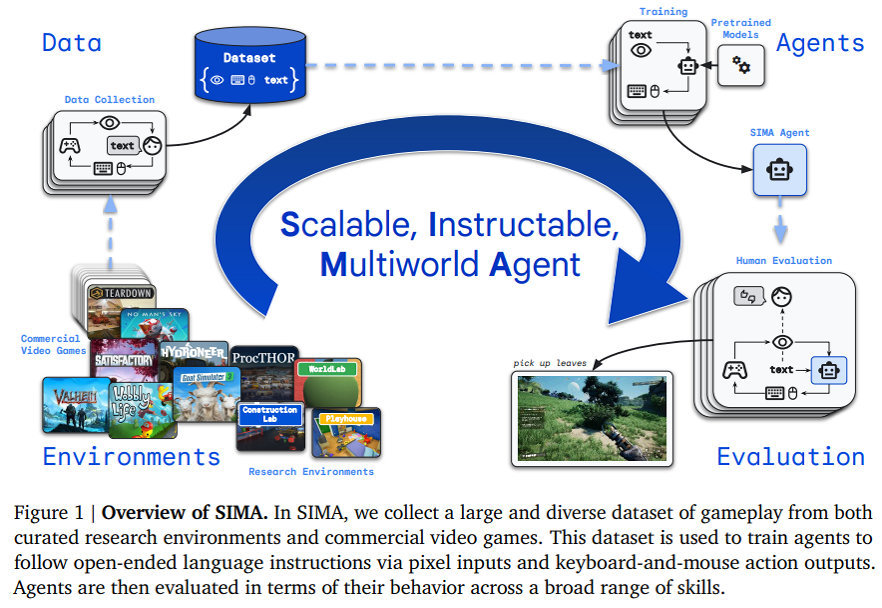
下图为 SIMA 智能体架构细节。
作为一种 AI 智能体,谷歌的 SIMA 可以感知和理解各种环境,然后采取行动来实现指定的目标。
重要的是,SIMA 既不需要访问游戏的源代码,也不需要定制的 API。它只需要两个输入:屏幕上的图像以及用户提供的简单自然语言指令。SIMA 使用键盘和鼠标输出来控制游戏中的核心角色来执行这些指令。人类可以使用这个简单的界面,这意味着 SIMA 可以与任何虚拟环境进行交互。
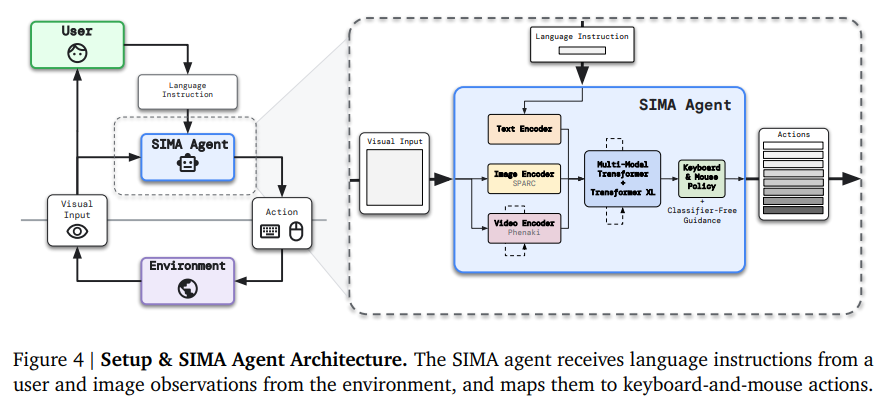
下图为 SIMA 数据中的指令。
当前版本的 SIMA 通过 600 项基础技能进行评估,涵盖导航(例如「左转」)、对象交互(「爬梯子」)和菜单使用(「打开地图」)。
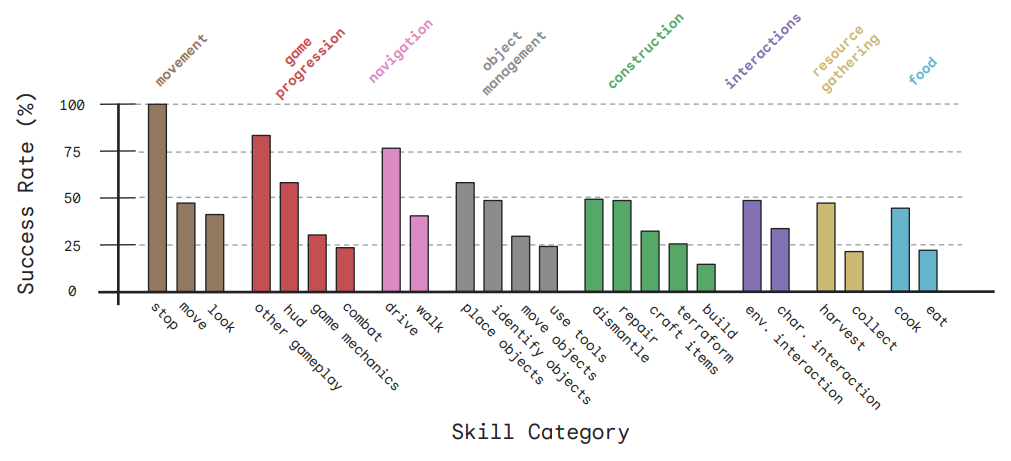
谷歌训练 SIMA 执行简单任务,大约 10 秒内就能完成。

SIMA 智能体的轨迹如下图所示。

谷歌希望未来的智能体能够处理需要高级战略规划和多个子任务才能完成的任务,例如「寻找资源和建立营地」。这是人工智能的一个重要目标,虽然大型语言模型已经演化出了能够捕获世界知识并生成规划的强大系统,但它们目前缺乏代表人类采取行动的能力。
跨游戏的强泛化能力
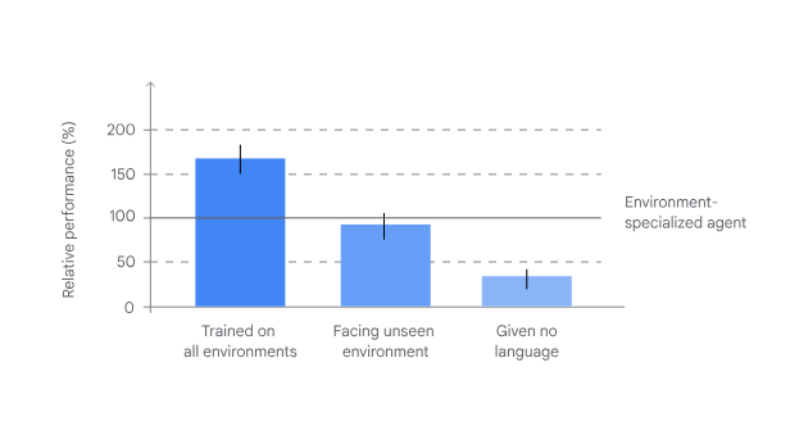
谷歌证明,受过多种游戏训练的智能体比仅学习如何玩一种游戏的智能体表现更好。
在谷歌的评估中,SIMA 智能体在一组九个 3D 游戏上进行了训练,其表现显著优于仅在每个单独的游戏上进行训练的所有专业智能体。
更重要的是,平均而言,接受过除一款游戏之外的所有游戏训练的智能体在这个未见过游戏上的表现几乎与专门训练过的智能体一样好。因此,这种在全新环境中发挥作用的能力凸显了 SIMA 超越其训练的泛化能力。
谷歌表示,这是一个很有潜力的初步结果,不过 SIMA 需要进行更多的研究才能在见过和未见过游戏中达到人类水平。
此外,SIMA 的性能依赖于语言。在控制测试中,智能体没有接受任何语言训练或指令,它的行为方式虽适当但漫无目的。例如,智能体可能会收集资源(这是一种常见行为),而不是按照指令去走。
谷歌评估了 SIMA 按照指令完成近 1500 个具体游戏内(in-game)任务的能力,其中部分使用了人类裁判。作为基线比较,谷歌使用环境专用 SIMA 智能体的性能(经过训练和评估以遵循单个环境中的指令)作为评估指标。
如下图所示,谷歌与三种类型的通用 SIMA 智能体进行了比较,每种智能体都经过多个环境的训练。
未来,谷歌期待在更多训练环境中进一步构建 SIMA,并纳入更强大的模型,从而提高 SIMA 对高级语言指令的理解能力以实现更复杂的目标。当然,随着 SIMA「暴露」在更多的训练世界中,谷歌希望它变得更加通用。