前言
大家好,我是田螺。
相信很多后端开发的伙伴们,都做过刷数任务了吧。今天跟大家聊聊,做好一个刷数任务,需要具备哪些后端思维。
1. 数据的备份和还原
我们做刷数任务的时候,首先要考虑的是,这些被刷的数据是否还要还原的。或者刷出问题时,需要回滚的。如果是的话,我们就要做好备份。
如果你是把数据迁移到新的表,则有可能不需要备份,这个具体问题具体分析的哈。
通常,我们在一个事务内,先备份数据,再操作刷数逻辑。
 图片
图片
当然,备份数据的方式有多种方式,可以数据库备份,比如搞一个备份表。或者文件系统快照等,在需要的时候,就还原数据。
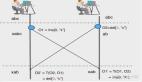
2.刷数维度是什么?是否支持灰度?
我们刷数的时候,先确认下具体的业务需求和数据模型。然后需要确定刷数的维度是什么。
 图片
图片
- 客户维度:比如刷数的维度可以是一个客户。刷数的时候,把这个客户的所有数据捞取出来,在一个事务内,把客户的所有数据,按照业务的规则,刷到一个表。
- 账号维度:刷数的维度是账号,在执行刷数的时候,就是把这个账号的所有数据捞取出来,在一个事务内,把账号的所有数据,刷到另外一个表。
当然,还有其他维度,比如产品维度等等都可以,就看业务需求和你们的数据模型。
确认了刷数维度后,需要思考你的刷数是否支持灰度。比如确认客户维度刷数后,你实现的代码,是否支持灰度刷数,也就是说,是否支持先刷一部分客户,确认没问题后,再根据配置刷全量客户。
3. 并发考虑,刷数过程是否需要加锁。
比如,你要给一个客户相关的业务表刷数,需要考虑并发场景,简单点说,就是你在刷数的过程中,客户是否可能在做交易请求,这时候,是否可能产生脏数据。
一般情况下,可以考虑给客户维度加分布式锁,比如加锁的key是customerId。但是我们加锁的时候,肯定是不希望影响客户太久的,因为加锁后,整个刷数的过程中,系统是处理不了这个用户的交易请求的,也就是说影响交易了。
 图片
图片
所以也一般刷数任务,我们会选择在夜深人静的时候执行,这时候用户发生交易的概率很低,影响相对较小。
4. 刷数失败怎么办?是否支持重试?
我们在刷数的时候,有可能会刷失败。比如因为网络问题、或者目标表结构等等。失败后,我们有哪些措施保证呢:
 图片
图片
如果刷数失败的话,我们要确保数据的完整性和一致性,一般一个刷数维度,需要加事务,确保失败可以回滚,保证数据一致性。刷失败之后,首先确认分布式锁要被移除(如果有加锁的话),因为要确认即使失败后,交易也是能正常进行的。
还要考虑失败支持重试。可以自动重试或者手动重试,比如通过xxl-job定时任务捞取,继续重试。有时候,可以设置重试次数和重试间隔,确保任务在一段时间内尝试恢复。
5. 恰到好处的事务处理
我们第4小节提到,如果失败了,需要保证数据的完整性和一致性。其实,一般我们刷数,就是通过加事务处理去保证的。
事务需要加到恰到好处,比如我们不能所有的刷数业务都放到一个事务内。如果我们是按照客户维度来刷数的,我们就一个事务把一个客户所有的数据刷的逻辑放到一块,当然,有些查询是可以放到事务外处理的,一些更新或者修改、删除操作则放到事务内。
 图片
图片
如果你的数据是分库处理的,则有可能刷数的时候要考虑分布式事务了。
6. 性能优化,考虑多线并行执行。
如果我们的刷数任务数据量很大,执行耗时比较久的话。就建议可以多线程并行执行。
比如你是分库分表的,是有30个表,你可以A线程执行1-10的表,B线程执行11-20的表,C线程执行21-30的表。
 图片
图片
7. 日志记录
我们执行一个刷数任务,一定要做好日志记录。
我记得我们技术领导说过一句话,很有道理:评价你的日志是否打印得是否够好。就是你根据控制台打印出的日志,能知道你的复杂业务执行到什么流程。如果异常中断,你能根据日志快速知道什么异常,哪个业务数据有问题,那就够了。
刷数日志打印,一般包括:
- 记录详细的刷数任务日志
- 包括执行的步骤
- 刷数成功与否
- 刷数耗时等信息
8.监控告警
我们开发刷数逻辑的时候,如果某种返回不符合预期的时候,就需要告警上报监控(比如插入数据库返回跟预期插入条数不一致)。
又或者是你刷数失败,需要包这个异常日志打印出来,并且上报监控(比如普罗米修斯,和企业微信通知)。比如这块代码:
try{
flushService.flushDataCustomerLevel(customerNo);
}catch(Exception e){
Logger.error("flush customer data fail: {}", customerNo, e);
prometheusMonitor.report("刷数失败",customerNo);
notify();
weChatWorkSend();
}9. 数据量大的时候,最好压测
如果你刷的数据量很大的时候,最好做压测。压测通常包括模拟多种负载情况,以确保系统在不同条件下都能正常运行。
做刷数任务压测,主要考虑这几方面:
- 数据量:使用大量数据进行测试,以确保系统在处理大规模数据时的性能。这可以包括数据量的增长、查询和写入的吞吐量等。
- 网络延迟和吞吐量:在模拟网络延迟和限制吞吐量的情况下进行测试,以了解系统在这些条件下的表现。
- 错误处理:引入模拟的错误场景,例如数据库连接中断、请求超时等,以验证系统对错误的处理能力。
刷数压测的好处:
 图片
图片
- 性能评估:压测可以帮助评估系统在处理大量数据时的性能。通过模拟真实负载,可以更好地了解系统的响应时间、吞吐量和资源利用情况。
- 容量规划:通过压测,可以更好地了解系统在不同负载条件下的容量需求。这有助于进行容量规划,确保系统能够应对未来的增长。
- 发现潜在问题:压测可以帮助发现系统中可能存在的潜在问题,如内存泄漏、并发问题、资源瓶颈等。通过在模拟环境中发现并解决这些问题,可以避免它们在生产环境中引起严重后果。
- 验证容错能力:压测可以测试系统在出现错误、超时、网络故障等异常条件下的容错能力。这有助于确保系统能够适应不可预测的情况。
- 性能优化:压测结果提供了性能瓶颈的线索,帮助团队进行性能优化。通过分析性能数据,可以识别需要改进的部分并优化系统。
- 规遇风险:通过压测,可以更早地发现潜在的性能问题和瓶颈,有助于规遇系统上线后可能面临的风险。
10. 实战压轴汇总:做一个刷数任务,如何更好保护你的系统
10.1 设置个配置时间,可以控制任务跑多长时间后终止。
有些时候,我们如果担心刷数任务跑太久,可能会影响交易,这时候我们可以搞个配置变量,比如apollo配置变量,控制刷数多长时间后,可以停止。
10.2 循环分页查询,设置最大次数告警监控
我们做刷数任务的时候,经常是分页循环扫描某个客户/用户表,然后一批一批出来执行刷数逻辑。比如伪代码像这样:
long minId
while(true){
List<CustomerDo> customerList = customer.pageQueryAscID(pageSize,minId);
flushCustomerData(customerList);
if(customerList.size()< pageSize){
break;
}
minId = customerList.get(customerList.size()-1).getId();
}这块代码,其实没啥问题。有些时候,我们可能手抖写错了,可能导致死循环。
其实为了保护我们的系统,我们可以先确认下客户有多少,然后设置个循环次数,当超过最大循环次数之后,就告警排查确认。
long minId;
Integer maxCycleNum =1000;
Integer cycleNum = 0;
while(true ){
List<CustomerDo> customerList = customer.pageQueryAscID(pageSize,minId);
flushCustomerData(customerList);
if(customerList.size()< pageSize){
break;
}
minId = customerList.get(customerList.size()-1).getId();
if(cycleNum>= maxCycleNum){
//告警
}
cycleNum ++;
}当然这只是个一种后端思路哈。
10.3 如果定时任务是xxl-job ,路由规则是什么,并发问题考虑
大家如果使用过xxl-job作为定时任务,应该抖配置过它的路由规则吧。比如是分片的,还是第一个/最后一个等等。
如果是分片的,就是多个pod都可能执行到你的业务逻辑。这时候你要考虑并发执行,你的业务是否收影响。
10.4 SQL是否命中索引,是否存在慢SQL
我们做刷数任务的时候,很多时候,都要跟SQL打交道。
我们要确保查询、更新、或者删除的数据量大的表,都要有索引了。要确保没有慢SQL。
常规的我们可以用explain分析SQL,我们还可以通过压测分析出来。
10.5 如果加了分布式锁,锁时间考虑
如果你是按照客户维度刷数,加了客户维度的分布式锁,你要考虑锁时间是多久,锁时间是否可以配置(一般这种最好配置一下。)
如果你时间设置小,那这时候刷数还没完成,锁就超时释放了,那不就有问题啦。
如果你时间设置过长也不太好,当然,你在刷完数,finally执行释放锁也可以。
finally {
redisService.deleteKey(customerNoKey);
}10.6 大事务考虑,事务是否太多?是否可以拆分为小事务
我们在刷数的时候,为了保证数据的完整性和一致性,一般要求加事务的。
但是,切忌事务不要太大,我们可以把一些查询放到事务外,把计算逻辑也放事务外,把数据库的更新、新增、删除操作放到事务内就好。
就是把大事务拆分为小事务。
10.7 打印耗时时间,如果时间够长
一般来说,做刷数,尽量打印一下耗时,这样我们可以根据日志,观察是否有哪些问题需要及时处理的。
比如打印刷一个客户要多久。或者打印一批客户要多久,等等。
10.8 是否可以加个配置,减少扫描
有些时候,我们需要配置一定的灰度规则来支持灰度刷数。如果刷数流程是先扫描所有客户,然后接着判断客户是否命中灰度。这样每次任务执行,都会扫描客户表。
我么可以考虑加个配置,传特定的客户号,根据客户号列表,去查客户列表,然后开始刷数逻辑,不用再全表扫描客户表了。
10.9 是否考虑校验逻辑
有些时候,我们没法确认我们刷的逻辑是否正确,这时候,可以考虑是否加校验逻辑。
你可以异步进行校验,也可以同步校验(当然,如果耗时不大的时候)
10.10 try...catch 包住可能的异常
如果我们是按照一个客户维度去刷数的,你要确认A客户刷失败,是不是不能影响B客户。这时候建议try...catch 包住可能的异常,这样即有利于分析错误原因,又可以不不因为未知异常导致刷数中断。