












本文经自动驾驶之心公众号授权转载,转载请联系出处。
从多视角视频构建动态场景的照片逼真的自由视角视频(FVV)仍然是一项具有挑战性的工作。尽管当前的神经渲染技术取得了显著的进步,但这些方法通常需要完整的视频序列来进行离线训练,并且无法实时渲染。为了解决这些限制,本文引入了3DGStream,这是一种专为真实世界动态场景的高效FVV流式传输而设计的方法。提出的方法在12秒内实现了快速的动态全帧重建,并以200 FPS的速度实现了实时渲染。具体来说,我们使用3D高斯(3DG)来表示场景。与直接优化每帧3DG的简单方法不同,我们使用了一个紧凑的神经变换缓存(NTC)来对3DG的平移和旋转进行建模,显著减少了每个FVV帧所需的训练时间和存储。此外,还提出了一种自适应的3DG添加策略来处理动态场景中的新兴目标。实验表明,与现有技术相比,3DGStream在渲染速度、图像质量、训练时间和模型存储方面具有竞争力。
论文链接:https://arxiv.org/pdf/2403.01444.pdf
论文名称:3DGStream: On-the-fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos
代码链接:https://sjojok.github.io/3dgstream/
3DGStream能够以百万像素的分辨率实时渲染照片逼真的FVV,具有异常快速的每帧训练速度和有限的模型存储要求。如图1和图2所示,与每帧从头开始训练的静态重建方法和需要在完整视频序列上进行离线训练的动态重建方法相比,我们的方法在训练速度和渲染速度方面都很出色,在图像质量和模型存储方面保持了竞争优势。此外,我们的方法在所有相关方面都优于StreamRF,这是一种处理完全相同任务的最先进技术。


3DGStream方法一览
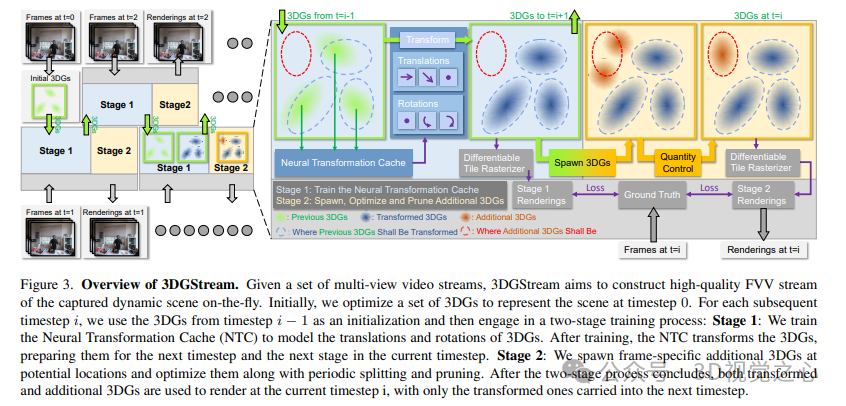
如下所示,给定一组多视角视频流,3DGStream旨在构建动态场景的高质量FVV流。最初,优化一组3DG来表示时间步长为0的场景。对于随后的每个时间步长i,使用时间步长i−1中的3DG作为初始化,然后进行两阶段的训练过程:第1阶段:训练神经变换缓存(NTC)来对3DG的平移和旋转进行建模。训练结束后,NTC转换3DG,为下一个时间步长和当前时间步长的下一阶段做好准备。第二阶段:在潜在位置生成特定于帧的附加3DG,并通过周期性拆分和修剪对其进行优化。在两阶段过程结束后,变换后的3DG和附加的3DG都被用于在当前时间步长i进行渲染,只有变换后的3D被带入下一个时间步长。
实验结果对比
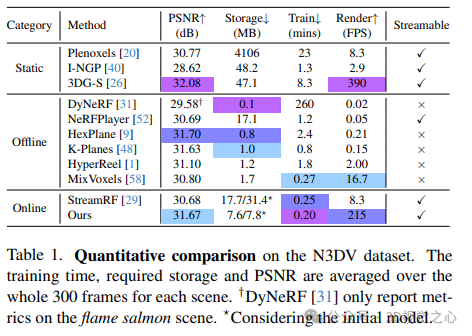
论文在两个真实世界的动态场景数据集上进行了实验:N3DV数据集和Meet Room数据集。N3DV数据集上的定量比较。训练时间、所需存储和PSNR在每个场景的整个300帧上取平均值。
Meet Room dataset性能对比:


3DG-S在初始帧上的质量对于3DGStream至关重要。因此,我们继承了3DGS的局限性,例如对初始点云的高度依赖性。如图7所示,由于COLMAP无法重建远处的景观,在窗口之外存在明显的伪影。因此,我们的方法将直接受益于未来对3DG-S的增强。此外,为了高效的训练,我们限制了训练迭代次数。

主要结论
3DGStream是一种高效的自由视点视频流的新方法。基于3DG-S,利用有效的神经变换缓存来捕捉目标的运动。此外,还提出了一种自适应3DG添加策略,以准确地对动态场景中的新兴目标进行建模。3DGStream的两级pipeline实现了视频流中动态场景的实时重建。在确保照片逼真的图像质量的同时,3DGStream以百万像素的分辨率和适度的存储空间实现了实时训练(每帧约10秒)和实时渲染(约200FPS)。大量实验证明了3DGStream的效率和有效性!

























