












本文经自动驾驶之心公众号授权转载,转载请联系出处。

自动驾驶的端到端可微学习最近已成为一种突出的范式。一个主要瓶颈在于其对高质量标记数据的巨大需求,例如3D框和语义分割,这些数据的手动注释成本是出了名的昂贵。由于AD中样本内的行为往往存在长尾分布这一突出事实,这一困难更加明显。换言之,收集到的大部分数据可能微不足道(例如,在笔直的道路上向前行驶),只有少数情况是安全关键的。在本文中,我们探讨了一个实际重要但未被充分探索的问题,即如何实现端到端AD的样本和标签效率。
具体而言,论文设计了一种面向规划的主动学习方法,该方法根据所提出的规划路线的多样性和有用性标准,逐步注释部分收集的原始数据。经验上,提出的计划导向方法可以在很大程度上优于一般的主动学习方法。值得注意的是,方法仅使用30%的nuScenes数据,就实现了与最先进的端到端AD方法相当的性能。希望我们的工作能够激励未来的工作,从以数据为中心的角度,除了方法论方面的努力之外。
论文链接:https://arxiv.org/pdf/2403.02877.pdf
本文的主要贡献:
- 第一个深入研究E2E-AD的数据问题的人。还提供了一个简单而有效的解决方案,可以在有限的预算内识别和注释有价值的数据,用于规划。
- 基于端到端方法的面向规划的哲学,为规划路线设计了新的特定任务的多样性和不确定性测量。
- 大量的实验和消融研究证明了方法的有效性。ActiveAD在很大程度上优于一般的对等方法,并且仅使用30%的nuScenes数据,实现了与具有完整标签的SOTA方法相当的性能。
方法介绍
在端到端AD框架内提供了ActiveAD的详细描述。利用AD特有的数据特征,设计了相应的多样性和不确定性指标。
1)标签的初始样本选择
对于计算机视觉中的主动学习,初始样本选择通常仅基于原始图像,而没有额外的信息或学习到的特征,这导致了随机初始化的常见做法。对于AD,还有其他先前的信息可供利用。具体来说,当从传感器收集数据时,可以同时记录传统信息,如自车的速度和轨迹。此外,天气和照明条件通常是连续的,并且易于在片段级别中进行注释。这些信息有利于为初始集合选择做出明智的选择。因此,我们为初始选择设计了自我多样性度量。
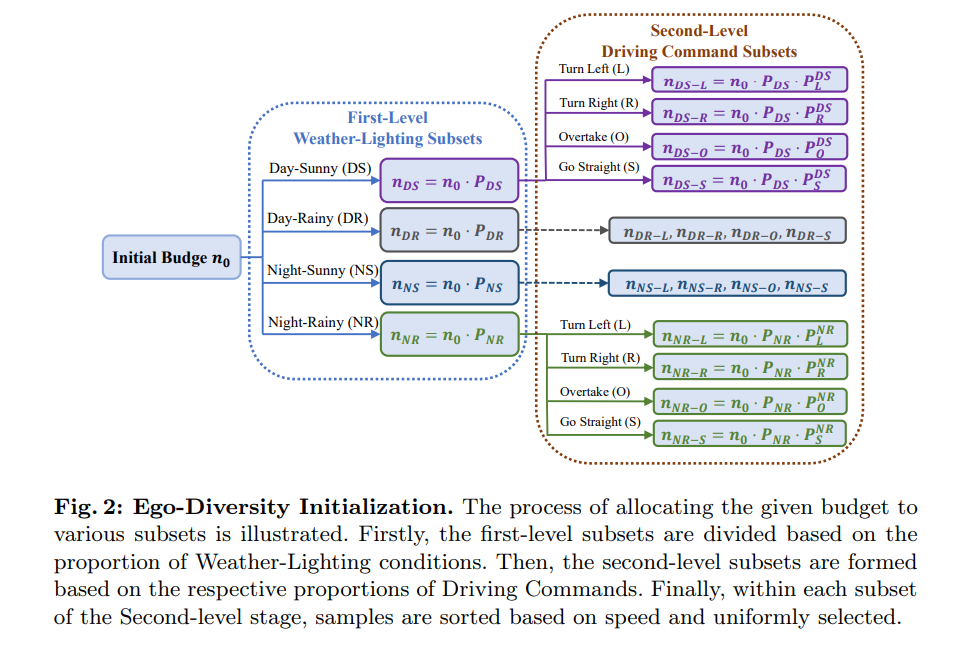
Ego Diversity:由三个部分组成:1)天气照明2)驾驶指令3)平均速度。首先使用nuScenes中的描述,将完整的数据集划分为四个互斥子集:Day Sunny(DS)、Day Rainy(DR)、Night Sunny(NS)、NightRainy(NR)。其次,根据一个完整片段中左、右和直行驾驶命令的数量将每个子集分为四类:左转(L)、右转(R)、超车(O)、直行(S)。论文设计了一个阈值τc,其中如果剪辑中左右命令的数量都大于或等于阈值τc时,我们将其视为该剪辑中的超越行为。如果只有向左命令的数量大于阈值τc,则表示左转。如果只有向右命令的数量大于阈值τc,则表示向右转弯。所有其它情况都被认为是直接的。第三,计算每个场景中的平均速度,并在相关的子集中按升序对它们进行排序。
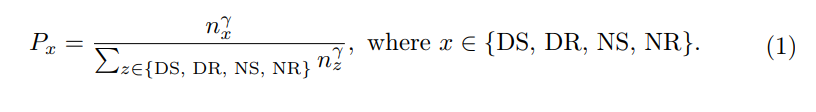
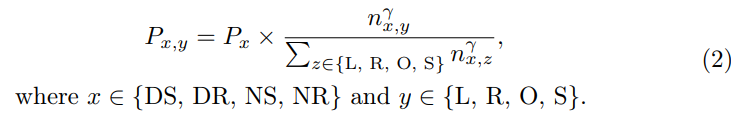
图2给出了基于多路树的初始选择过程的详细直观过程。
2)增量选择的准则设计
在本节将介绍如何基于使用已注释片段训练的模型,对片段的新部分进行增量注释。我们将使用中间模型对未标记的片段进行推理,随后的选择基于这些输出。尽管如此,还是采取了面向规划的观点,并介绍了后续数据选择的三个标准:位移误差、软碰撞和代理不确定性。
标准一:位移误差(DE)。将表示为模型的预测规划路线τ与数据集中记录的人类轨迹τ*之间的距离。

其中T表示场景中的帧。由于位移误差本身是一个性能指标(无需注释),因此它自然成为主动选择中的第一个也是最关键的标准。
标准二:软碰撞(SC)。将LSC定义为预测的自车轨迹和预测的agent轨迹之间的距离。将通过阈值ε过滤掉低置信度agent预测。在每个场景中,选择最短距离作为危险系数的度量。同时,在term和最近距离之间保持正相关:
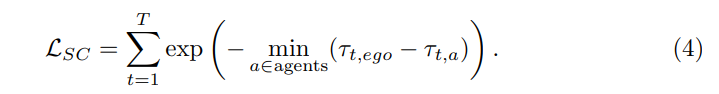
使用“软碰撞”作为一个标准,因为:一方面,与“置换误差”不同,“碰撞比率”的计算取决于目标的3D框的注释,而这些注释在未标记的数据中不可用。因此,应该能够仅根据模型的推理结果来计算标准。另一方面,考虑一个硬碰撞标准:如果预测的自车轨迹会与其他预测的agent的轨迹发生碰撞,将其指定为1,否则指定为0。然而,这可能会导致标签为1的样本太少,因为AD中最先进模型的碰撞率通常很小(低于1%)。因此,选择使用与其他对目标最近的距离来代替“碰撞率”度量。当与其他车辆或行人的距离太近时,风险被认为要高得多。简言之,“软碰撞”是衡量碰撞可能性的有效指标,可以提供密集的监督。
标准III:agent不确定性(AU)。对周围agent的未来轨迹的预测自然具有不确定性,因此运动预测模块通常会生成多个模态和相应的置信度得分。我们的目标是选择那些附近agent具有高度不确定性的数据。具体来说,通过距离阈值δ过滤出遥远的主体,并计算剩余主体的多种模式的预测概率的加权熵。假设模态的数量是,并且agent在不同模态下的置信度得分是Pi(a),其中i∈{1,…,Nm}。然后,Agent不确定性可以定义为:
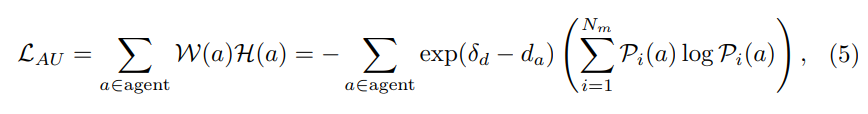
Overall Loss:
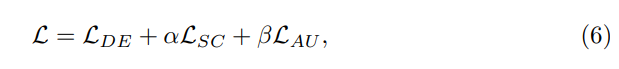
3)整体主动学习范式
Alg1介绍了方法的整个工作流程。给定可用预算B、初始选择大小n0、在每个步骤中进行的活动选择的数量ni以及总共M个选择阶段。首先使用上述描述的随机化或自车多样性方法初始化选择。然后,使用当前注释的数据来训练网络。基于训练的网络,我们对未标记的进行预测,并计算总损失。最后根据总体损失对样本进行排序,并选择当前迭代中要注释的前ni个样本。重复这个过程,直到迭代达到上限M,并且所选择的样本数量达到上限B。

实验结果
在广泛使用的nuScenes数据集上进行了实验。所有实验都使用PyTorch实现,并在RTX 3090和A100 GPU上运行。
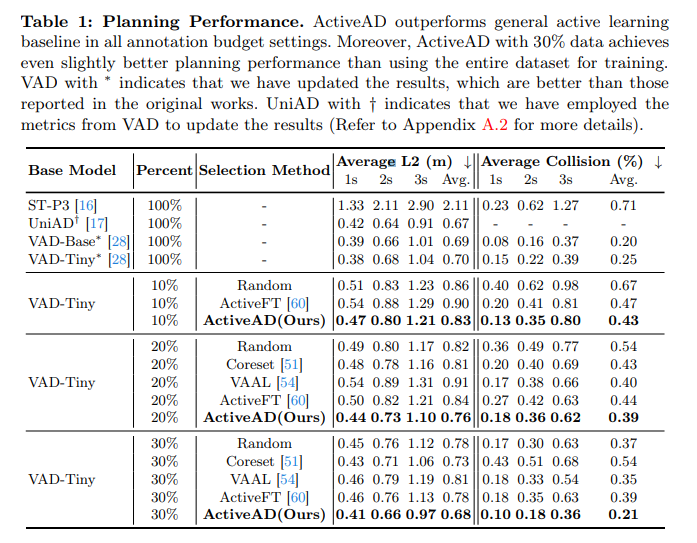
表1:规划表现。ActiveAD在所有注释budget设置中都优于一般的主动学习基线。此外,与使用整个数据集进行训练相比,具有30%数据的ActiveAD实现了略好的规划性能。带有*的VAD表明已经更新了结果,这些结果比原始工作中报告的结果要好。带有†的UniAD表明已使用VAD的指标来更新结果。
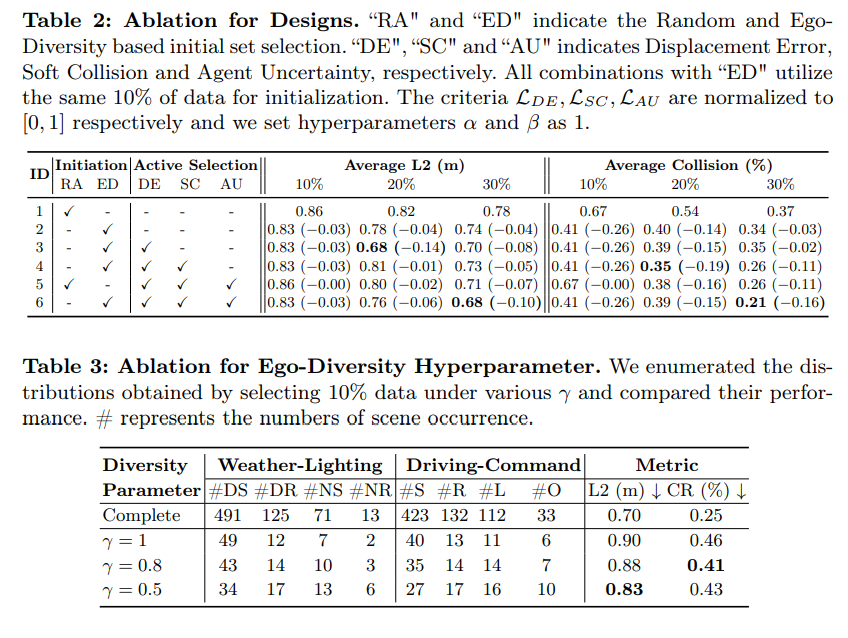
表2:设计消融实验。“RA”和“ED”表示基于随机性和自车多样性的初始集选择。“DE”、“SC”和“AU”表示位移误差, 分别为软碰撞和agent不确定性。所有带“ED”的组合都使用相同的10%数据进行初始化。LDE、LSC和LAU分别归一化为[0,1],将超参数α和β设置为1。
图3:所选场景可视化。根据选择的前置摄像头图像基于在10%数据上训练的模型的位移误差(col 1)、软碰撞(col 2)、agent不确定性(col 3)和混合(col 4)标准。Mixed代表了我们的最终选择策略ActiveAD,并考虑了前三种情况!

表4,各种场景下的性能。在各种天气/照明和驾驶命令条件下,使用30%数据的活动模型的平均L2(m)/平均碰撞率(%)越小,性能越好。
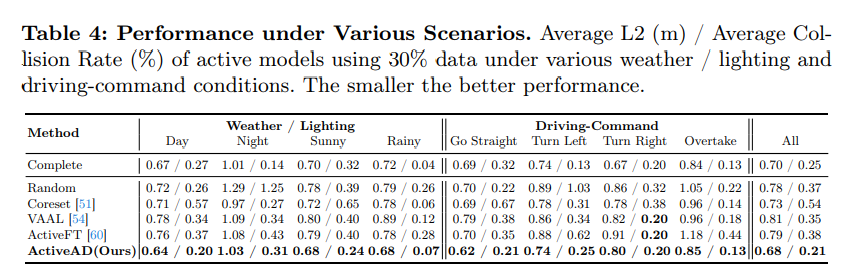

图4:多个标准之间的相似性。它显示了 通过四个标准选择10%(左)和20%(右)的新采样场景:位移误差(DE)、软碰撞(SC)、代理不确定性(AU)和混合(MX)
本工作的一些结论
为了解决端到端自动驾驶数据标注的高成本和长尾问题,率先开发了量身定制的主动学习方案ActiveAD。ActiveAD基于面向规划的哲学,引入了新的任务特定的多样性和不确定性度量。大量实验证明了方法的有效性,仅使用30%的数据,就显著超过了一般的往期方法,并实现了与最先进模型相当的性能。这代表着从以数据为中心的角度对端到端自动驾驶的一次有意义的探索,并希望我们的工作能够启发未来的研究和发现。






























