












作者 | 汪昊
审校 | 重楼
推荐系统最早的算法是1992 年发明的协同过滤。自协同过滤算法诞生之日起,人们便与推荐系统中的各种不公平现象作斗争。虽然推荐系统中的不公平现象广泛存在,并且严重影响了推荐系统的生态健康发展,这些现象真正引起人们关注却要等到2017年之后。2017 年,在人类的人工智能发展历程中有个里程碑事件,就是国际学术会议 FacCT 的创建。这个会议专门针对人工智能伦理,可以说把人工智能中的道德问题,包括推荐系统中的不公平性问题,暴露给了全世界的研究者。

那么问题来了,什么是推荐系统的不公平性?推荐系统作为一种算法,主要为用户推荐它可能感兴趣的物品。该算法会出现过度推销热门产品、在推荐列表顶部推荐的物品过热等等一系列不公平问题。其中在推荐列表顶部推荐的物品过热的问题,被称为位置偏差问题(Position Bias Problem),引起了学者的广泛关注。
我们利用正则化的方式来处理位置偏差问题。首先,我们把矩阵分解算法作为原生算法。矩阵分解算法的损失函数定义如下:
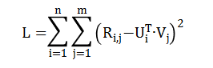
矩阵分解的本质就是利用降维手段修复原始矩阵中的缺失值。在损失函数的定义里,R 就是原始矩阵中已知的评分数据,U 是用户特征向量,而 V 是物品特征向量。在实际的使用过程中,损失函数需要进行处理才能使用。处理之后的损失函数如下:
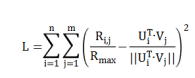
经过处理之后,算法可以避免数据出现异常值。我们可以从另外一个角度去看这个问题,我们可以认为其实矩阵分解是保角降维运算(Angle-preserving Dimensionality Reduction)。而 U 和 V 就是从高维空间降维处理过之后的向量空间。
我们假设在推荐系统中,系统给每个用户都推荐了一个物品列表。这个物品列表中所有的物品都被排列上了。因此,最差的曝光情况就是一个物品被排在了列表最低端。所以,我们可以利用这一点,设计出一个正则化项,用来惩罚损失函数 L :
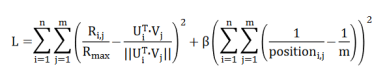
其中position 是物品在推荐列表中的位置,而 m 是所有物品的数量。因为推荐列表中存在幂律效应,也就是越热门的物品越容易出现在列表的上方,而这类物品用户评分往往很高。因此我们把损失函数 L 修正成如下的形式:
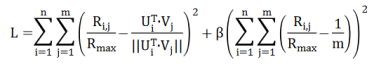
下面我们用随机梯度下降方法来对损失函数 L 进行求解,得到了如下公式:
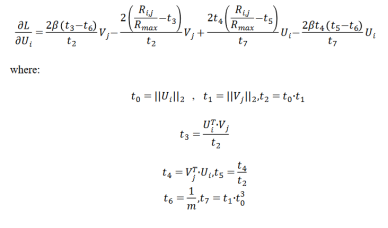
以及:
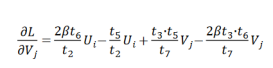
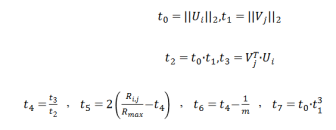
以上就是整个算法的流程。该算法由Ratidar Technologies LLC (北京达评奇智网络科技有限责任公司) 发表于国际学术会议CECNet 2023。论文标题为Mitigating Position Bias with
Regularization for Recommender Systems。论文可以在arXiv.org 上进行下载:https://arxiv.org/ftp/arxiv/papers/2401/2401.16427.pdf 。
下面我们讨论一下该算法在不同的数据集合上的表现:作者采用了两个不同的数据集合进行算法测评:MovieLens 1 Million Dataset (6040 名用户,3706 部电影) 和LDOS-CoMoDa Dataset (121 名用户,1232 部电影)。算法测试结果如下面6张图所示:
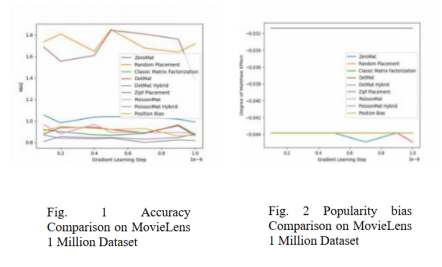
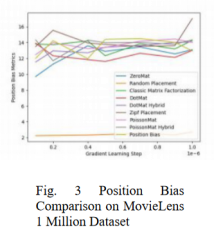
图1 至图 3 分别是该算法和另外几种算法在MovieLens 数据集上的测评效果,可以看到,不管是在准确率(测评指标为 Mean Absolute Error),热度偏差指标还是位置偏差指标的测评上,该算法均表现优异。
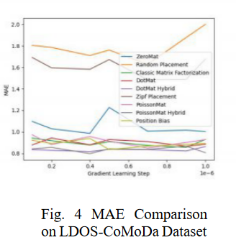
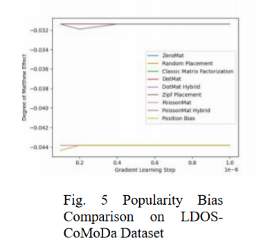
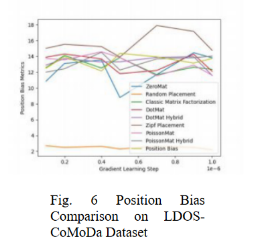
图4 到图6 展示的是算法在 LDOS-CoMoDal 数据集合上的表现。与上一组数据相似,该算法的性能表现出众,能够很好的解决位置偏差问题。
推荐系统中的不公平现象由来已久,随着近些年来人们对于推荐系统的关注度不断地提升。推荐系统公平性问题也引起了越来越多人的关注。推荐系统中关注最多的不公平性问题其实是流行度偏差(Popularity Bias)。早在2017 年,Alex Beutel 等人就提出了 Focused Learning, 用于解决该问题。
后期大多数跟进工作主要采用正则化项的方式进行。2020 年,国际学术会议 ICBDT 2020 的最佳论文报告奖MatRec 另辟蹊径,利用了类似SVDFeature 的方式将用户和物品排名作为变量,嵌入到矩阵分解算法中,取得了不俗的成绩。本文所介绍的算法,沿用了传统的正则化项的思路,利用了推荐系统中的幂律现象,成功对推荐系统中的位置偏差进行建模,较为令人满意的解决了该问题。
随着商品化大潮愈演愈烈,以及最近几年的全球经济不景气。越来越多的企业主开始关注自己的短期利益,而忽略所谓人工智能伦理等短期收益似乎不如传统方法,但是长期收益却能使公司建立起完善的生态体系和卓越的品牌效应的技术方向。如果我们不解决推荐系统的马太效应,我们会发现推荐系统的生态会变差:比如在游戏中,我们给用户推荐玩家联盟。最有效的方式其实可能是推荐人数最多的前3 个联盟,但如果我们为了追求点击率就这么做,毫无疑问会把剩下的联盟全部搞死,整个产品的生态也就完了。所以有的时候,我们就算是牺牲了由点击率提升带来的经济效益,也应该把产品的口碑和生态搞好。而本文介绍的算法,就提供了这样一种思路。
作者简介
汪昊,前 Funplus 人工智能实验室负责人。曾在 ThoughtWorks、豆瓣、百度、新浪等公司担任技术和技术高管职务。担任过创业公司CTO 和技术VP。在互联网公司和金融科技、游戏等公司任职 13 年,对于人工智能、计算机图形学和区块链等领域有着深刻的见解和丰富的经验。在国际学术会议和期刊发表论文 42 篇,获得IEEE SMI 2008 最佳论文奖、ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 2024最佳论文报告奖。

















