上月底,创业公司Groq的产品一夜爆火。
凭借自研的硬件加速器LPU,达成了500个token/s的神级推理速度,当场秒杀了ChatGPT。
 图片
图片
 Groq提供的响应速度刷新了人们的认知,而这要归功于背后的语言处理单元硬件LPU(language processing unit hardware)。
Groq提供的响应速度刷新了人们的认知,而这要归功于背后的语言处理单元硬件LPU(language processing unit hardware)。
Groq的研发团队在LPU上应用了创新的硬件架构设计,并配套了强大的编译器。
下面让我们跟随Substack的专栏作家Abhinav Upadhyay一起,一步步揭开Groq LPU底层架构的神秘面纱。
Groq LPU的神秘面纱
到目前为止,Groq并没有给出任何关于LPU本身的论文,但在过去几年中,他们发表了下面两篇论文:
论文地址:https://dl.acm.org/doi/10.1109/ISCA45697.2020.00023
 图片
图片
论文地址:https://dl.acm.org/doi/abs/10.1145/3470496.3527405
两篇工作分别在2020年和2022年发表在计算机体系结构顶会ISCA上,后一篇还是获奖论文。
这两篇文章解释了Groq的张量流处理器(TSP)的设计和实现,以及他们如何使用TSP构建分布式推理引擎。
尽管没有正式声明,但LPU很可能是基于这个分布式系统来进行设计和扩展的。
那么,我们就首先详细分解一下TSP及其编译器的架构,然后以此为基础来分析Groq如何使用这些TSP,构建可靠且高吞吐量的分布式AI推理引擎。

TSP的架构与传统的CPU或GPU芯片有很大不同,主要目的是为了让TSP硬件更具确定性。
这里就先要提一嘴CPU或GPU的不确定性。
CPU和GPU微架构中的非确定性
基于微架构的设计,在CPU和GPU上执行指令是不确定的,——即无法保证特定指令何时执行、完成需要多长时间以及何时提供结果。
举个例子,现代CPU一般具有如下设计:
- 超标量(Super scalar architecture):每个周期能够发出多条指令;
- 乱序执行(Out-of-order execution):以任意顺序执行指令;
- 预测执行(Speculative execution):对于分支,它会猜测分支条件是真是假,并提前预测执行该分支以提高吞吐量(当然如果猜错了,就需要放弃并返回另一条分支);
- 指令流水线(Instruction pipelining):将指令分为多个阶段,以流水线的方式执行,再次提高了指令吞吐量;
- 多级缓存(Multiple levels of caches):CPU有2到3级缓存,可以减少从内存加载数据带来的延迟。
所有这些都使得CPU中指令执行的顺序和时间不确定且难以推理。
而GPU还有其他一些非确定性因素,包括缓存、共享和全局内存、动态资源分区等。
非确定性带来的问题是,我们很难推理程序的性能,也很难保证最坏情况下的性能限制。
因此,Groq为TSP提出了一个全新的设计,高度并行,且没有不确定行为。这消除了硬件的复杂性,使编译器能够获得更大的权力,精确调度和控制指令的执行,保证对程序性能的限制。
下面,让我们从内部了解TSP的架构是什么样子的。
TSP架构
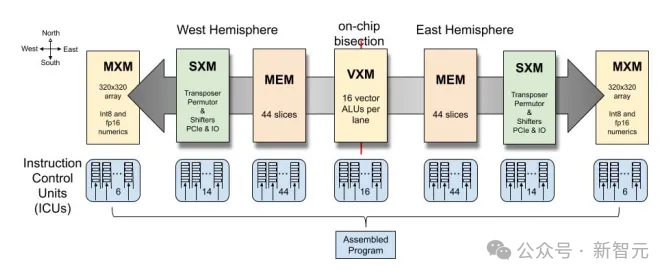
TSP的硬件设计与CPU或GPU的设计形成鲜明对比。传统的多核芯片采用平铺架构,在下图(a)中,每个小方块(tile)代表一个处理核心。
核心由一组功能单元组成,负责执行不同类型的计算(算术运算、内存运算、逻辑运算、指令控制等)。
而TSP的设计师将这种传统设计彻底颠覆了。他们将功能单元移到核心之外,以2d网格方式排列。
网格的每一列只包含特定类型的功能单元,称为切片(slice)。下图显示了传统多核芯片和TSP在设计上的区别。
TSP具有以下功能切片:
MXM:用于执行矩阵运算
SXM:用于对矢量进行移位和旋转操作
MEM:内存读/写运算
VXM:向量上的算术运算
ICU:指令控制单元,这个有点特殊,就是上图(b)底部那一条水平的蓝色条,它负责获取和调度指令并在其他切片上执行。
在了解了TSP的架构之后,让我们将注意力转移到它的核心:指令执行。
TSP中的指令执行
TSP以SIMD(单指令多数据)方式执行指令。每个功能切片由20个tile组成,每个tile能够处理16个数。因此,一个完整的切片可以处理并生成最大320个元素的向量。
这些切片以生产者——消费者的方式进行交互。
当从内存中读取向量时,会为其分配流ID(介于0到31之间)和流向(东或西)。每个切片都可以自由处理流并生成新的结果流,也可以让流按原样流向下一个相邻切片。
为了有效地处理完整的向量,指令以流水线方式执行,如下图所示:
 图片
图片
TSP中指令的流水线执行会导致流在切片之间交错移动。上图的黑色块描绘了流在切片中不同时间戳的移动。
当然了,想要愉快地执行指令,必然少不了编译器和指令集(ISA)设计。
TSP的编译器和ISA
TSP的设计人员简化了硬件,所以压力就给到了编译器这边。编译器需要精确地调度指令和数据流,以正确执行给定的程序,并以最有效的方式执行。
编译器有权访问TSP硬件的以下状态:
- 320个通道的编程抽象:TSP芯片中的每个tile都能够以SIMD方式在矢量的16个单元(16个通道)上运行。垂直切片由20个这样的tile组成,因此总共有320个SIMD通道可供执行;
- 144个独立指令队列:芯片上有144个指令队列,每个周期能够发出一条或多条指令。编译器可以完全控制每个队列中的程序顺序;
- 每个通道64个逻辑流:每个通道可以访问64个逻辑流,可用于移动操作数或结果,其中32个可用于向东移动数据,而另外32个用于向西移动数据;
- 220M全局共享SRAM。
由于TSP硬件中没有非确定性行为,因此编译器可以准确了解每条指令的延迟,以及程序中的数据流(DNN的计算图等)。
编译器识别计算任务之间的依赖关系,并分配到TSP的可用功能单元上并行执行。
TSP编程模型依赖于两个关键要素:
硬件中的确定性数据路径
通过ISA获得的有关指令延迟的信息
编译器的后端可以跟踪片上任何流的位置和使用时间,称为软件定义硬件。
从TSP扩展到LPU
TSP是LPU的基础单元。许多TSP以机架的形式组合在一起,形成一个能够提供大量吞吐量的分布式系统。
设计多TSP系统
与TSP一样,分布式多TSP系统的设计目标也围绕着确定性数据流和指令执行,以及节点之间的低延迟通信。
分布式TSP系统的设计从节点开始。节点由机箱内8个TSP设备组成。这些设备中的每一个都由11个引脚组成,其中7个引脚用于将每个TSP设备连接到节点中的其他7个TSP设备,其余4个引脚用于形成全局链接。
节点中的每个设备都有4个全局链路,总共有32个全局链路,共同构成了一个32个虚拟端口的高基数路由器(high-radix router)。
高基数路由器支持大量连接、高带宽和高性能,这正是高性能分布式系统所需要的。
将9个这样的TSP节点和8个TSP组合成一个机架。机架中的每个节点都有32个端口,因此机架总共有288个全局端口。
其中144个端口在机架内本地使用,以便在机架内快速传输数据,其余144个端口用于连接到其他机架。
最大配置的系统可以支持145个相互互连的机架,包括10440个TSP,系统中任何两个TSP之间最多有5个hops。
在基于TSP的分布式系统中实现确定性
在这种扩展的分布式系统制度中,单个TSP的功能单元充当大规模并行处理器的单个处理核心。TSP的计算模型基于确定性硬件,所以整个分布式系统也应具有同样的确定性。
使用硬件对齐计数器同步TSP的时钟
每个TSP设备都包含一个称为硬件对齐计数器(HAC)的硬件计数器,溢出周期为256。TSP通过以下步骤使用它来相互同步:
- 当两个TSP互连时,其中一个TSP将其HAC值传输给对方。然后,对方将该值返回发送方。发送方观察当前HAC值与返回值之间的差值。
- 这个差值就代表了两个设备之间链路的延迟。此过程重复多次,得到两个TSP之间的平均链路延迟。
- 之后,两个设备以父子关系排列。父级定期将当前HAC值发送给子级。子级将平均链路延迟与自己的HAC值相加,并与自己的HAC值进行比较。
- 两个值之间的差值表示由于连续时钟漂移而导致的初始未对准。然后子级调整其HAC值以减小此差异。在多次重复此过程后,两个TSP的HAC值会收敛在一个小邻域内,表示链路延迟的抖动。
- 协议允许两个TSP相互同步,并且可以通过在网络中建立生成树来扩展TSP多跳网络。
初始计划调整
程序在多TSP系统上执行之前,需要对齐所有TSP,以正确调度整个系统的数据流和指令执行。这涉及到以下机制:
- 在单个TSP级别,有几个独立的功能单元和144个独立的指令队列。为了同步它们,TSP支持SYNC和NOTIFY指令。SYNC指令将所有指令队列置于停放状态,其中一个队列充当通知程序。当通知器发出 NOTIFY指令时,该指令被广播到芯片上的所有队列,此时它们被同步并恢复操作。
- 对于多TSP系统,两个TSP使用HAC相互同步,另外每个TSP都支持DESKEW指令,用于停止处理任何后续指令,直到TSP的HAC溢出。
- 要扩展多跳系统,可以在生成树的每个hop上重复执行以上方案。
运行时重新同步
虽然TSP在程序开始时进行一次性同步,但它们也需要在程序执行期间重新同步,因为每个TSP都有自己独立的时钟源。
为此,TSP使用更轻量级的方案。除了HAC之外,每个TSP都有一个软件对齐计数器(SAC),其溢出周期与HAC相同。
但是,SAC在TSP之间不同步,SAC只是计算TSP的时钟周期。HAC值表示分布式系统的全局时间,而SAC表示本地时间。因此,HAC和SAC值之间的增量决定了累积漂移。
为了重新同步本地和全局时间,TSP执行一条RUNTIME_DESKEW指令。系统中的每个TSP同时执行该指令,根据累积的漂移调整全局时间与本地时间。
编译器在软件计划网络中的作用
到目前为止,编译器能够对TSP内以及整个网络中的数据移动进行周期准确的了解。编译器知道在源TSP上注入向量的确切时间以及它到达目标TSP的确切时间,称为软件计划网络。
编译器不是动态管理数据流,而是在编译时静态解析所有内容。
已知流量模式
对于深度学习模型,编译器可以根据模型的静态计算图推断数据流。编译器还可以在网络中可用的TSP设备之间自动分配计算任务。
因此,编译器会计算每个子任务的精确执行时间以及各层之间的激活交换。这使得并行分解步骤显式,并完全由编译器控制。
计划的数据流
在传统的网络系统中,通过网络的数据包流由硬件管理,硬件在感应到网络中的负载时会优化路由。数据流中的这种被动调整会增加延迟,并在数据流中引入非确定性。
为了避免这种情况,分布式多TSP系统使用编译器显式调度通过网络的数据流。编译器巧妙地路由数据,以便在任何时间点都不会在网络中出现拥塞积聚。
除此之外,编译器计划的数据流还改善了网络中的延迟,因为编译器可以调度数据主动推送,而不是必须通过设备请求。
确定性负载均衡
在编译时调度数据流的另一个优点是,它允许编译器有效地跨可用链接对流进行负载均衡。在传统网络中,硬件根据路由器中可用的拥塞指标,按数据包执行路由决策。
但是,在多TSP系统的情况下,编译器会根据数据量以最佳方式执行调度,并选择要分散流量的链路数量。这样可以有效地利用系统中的可用带宽,并减少整体延迟。