在现成的 RAG 实施过程中,经常会出现检索的文档缺少完整的答案或是包含冗余信息和无关的信息,以及文档排序不同,导致生成的答案与用户查询的意图不一致。
现介绍三种能够有效提高检索能力的技术,即查询扩展(Query expansion),跨编码器重排序(Cross-encoder re-ranking),嵌入适配器(Embedding adaptors),可以支持检索到更多与用户查询密切匹配的相关文档,从而提高生成答案的影响力。
1.查询扩展
查询扩展是指对原始查询进行改写的一系列技术。有两种常见的方法:
1) 使用生成的答案进行查询扩展
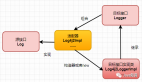
给定输入查询后,这种方法首先会指示 LLM 提供一个假设答案,无论其正确性如何。然后,将查询和生成的答案合并在一个提示中,并发送给检索系统。
 图片
图片
这个方法的效果很好。基本目的是希望检索到更像答案的文档。假设答案的正确性并不重要,因为感兴趣的是它的结构和表述。可以将假设答案视为一个模板,它有助于识别嵌入空间中的相关邻域。具体可参考论文《Precise Zero-Shot Dense Retrieval without Relevance Labels【1】》
下面是用来增强发送给 RAG 的查询的提示示例,该 RAG 负责回答有关财务报告的问题。
2)用多个相关问题扩展查询
利用 LLM 生成 N 个与原始查询相关的问题,然后将所有问题(加上原始查询)发送给检索系统。通过这种方法,可以从向量库中检索到更多文档。不过,其中有些会是重复的,因此需要进行后处理来删除它们。
 图片
图片
这种方法背后的理念是,可以扩展可能不完整或模糊的初始查询,并纳入最终可能相关和互补的相关方面。
下面是用来生成相关问题的提示:
具体可参考论文《Query Expansion by Prompting Large Language Models【2】》。
上述方法有一个缺点就是会得到很多的文档,这些文档可能会分散 LLM 的注意力,使其无法生成有用的答案。这时候需要对文档进行重排序,去除相关性不高的文档。
2.交叉编码器重排序
这种方法会根据输入查询与检索到的文档的相关性的分数对文档进行重排序。为了计算这个分数,将会使用到交叉编码器。

交叉编码器是一种深度神经网络,它将两个输入序列作为一个输入进行处理。这样,模型就能直接比较和对比输入,以更综合、更细致的方式理解它们之间的关系。
 图片
图片
交叉编码器可用于信息检索:给定一个查询,用所有检索到的文档对其进行编码。然后,将它们按递减顺序排列。得分高的文档就是最相关的文档。
详情请参见 SBERT.net Retrieve & Re-rank【3】。
 图片
图片
下面介绍如何使用交叉编码器快速开始重新排序:
交叉编码器重新排序可与查询扩展一起使用:在生成多个相关问题并检索相应的文档(比如最终有 M 个文档)后,对它们重新排序并选出前 K 个(K < M)。这样,就可以减少上下文的大小,同时选出最重要的部分。
3.嵌入适配器
这是一种功能强大但使用简单的技术,可以扩展嵌入式内容,使其更好地与用户的任务保持一致,利用用户对检索文档相关性的反馈来训练适配器。
适配器是全面微调预训练模型的一种轻量级替代方法。目前,适配器是以小型前馈神经网络的形式实现的,插入到预训练模型的层之间。训练适配器的根本目的是改变嵌入查询,从而为特定任务产生更好的检索结果。嵌入适配器是在嵌入阶段之后、检索之前插入的一个阶段。可以把它想象成一个矩阵(带有经过训练的权重),它采用原始嵌入并对其进行缩放。
 图片
图片
以下是训练步骤:
1)准备训练数据
要训练嵌入适配器,需要一些关于文档相关性的训练数据。这些数据可以是人工标注的,也可以由 LLM 生成。这些数据必须包括(查询、文档)的元组及其相应的标签(如果文档与查询相关,则为 1,否则为-1)。为简单起见,将创建一个合成数据集,但在现实世界中,需要设计一种收集用户反馈的方法(比如,让用户对界面上的文档相关性进行评分)。
为了创建一些训练数据,首先可利用LLM生成财务分析师在分析财务报告时可能会提出的问题样本。
然后,为每个生成的问题检索文档。为此,将查询一个 Chroma 集合,在该集合中,以前索引过一份财务报告。
再次使用 LLM 评估每个问题与相应文档的相关性:
然后,将训练数据结构化为问答元组。每个元组将包含查询的嵌入、文档的嵌入和评估标签(1,-1)。
最后,生成完训练元组后,将其放入torch数据集,为训练做准备。
2)定义模型
定义了一个以查询嵌入、文档嵌入和适配器矩阵为输入的函数。该函数首先将查询嵌入与适配器矩阵相乘,然后计算该结果与文档嵌入之间的余弦相似度。
3)定义损失(loss)
目标是最小化前一个函数计算出的余弦相似度。为此,将使用均方误差(MSE)损失来优化适配器矩阵的权重。
4)训练
初始化适配器矩阵,并完成训练 100 次epochs。
训练完成后,适配器可用于扩展原始嵌入,并适配用户任务。
在检索阶段,只需将原始嵌入输出与适配器矩阵相乘,然后输入检索系统即可。
以上三种方法操作性较强,感兴趣的读者可以将其应用到现有的RAG应用中,来评估这些手段对于自己的场景有效性。
相关链接:
【1】https://arxiv.org/pdf/2212.10496.pdf
【2】https://arxiv.org/pdf/2305.03653.pdf
【3】https://www.sbert.net/examples/applications/retrieve_rerank/README.html
原文来自:Ahmed Besbes:3 Advanced Document Retrieval Techniques To Improve RAG Systems