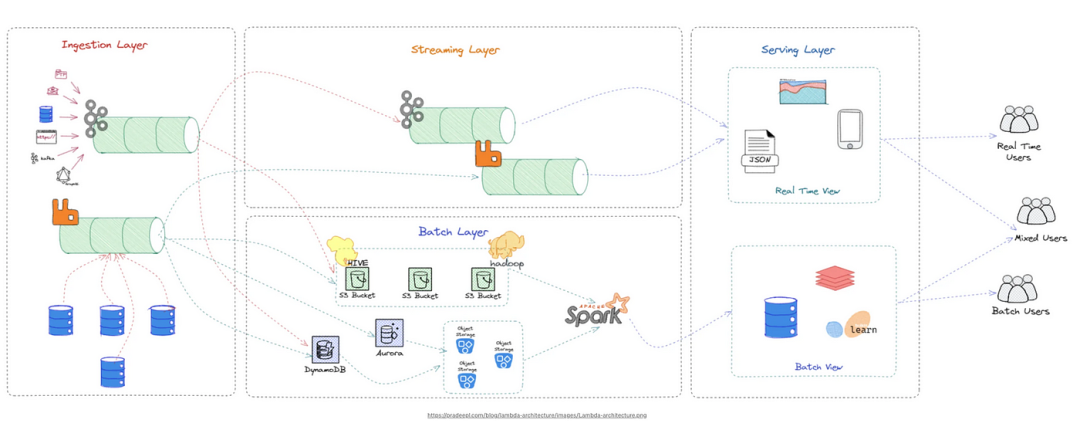
大数据处理涉及处理和分析大型复杂数据集的技术和技术。“大数据”通常指的是传统数据库和处理工具无法处理的数据集。 例如:应用程序日志、用户交互日志:这些大数据用于分析用户互动、偏好和行为,以改进内容推荐算法并提升用户参与度。 各种组件共同工作以处理、存储和分析这些大型数据集。这些组件共同形成一个大数据处理生态系统。

大数据处理的关键组件:
1. 数据摄取和传输(Kafka、Logstash(ELK))
批处理和流处理:数据可以分批摄取,也可以以实时流模式处理。 批处理涉及按预定义的块收集和处理数据,而流摄取处理连续生成并以准实时方式处理的数据。
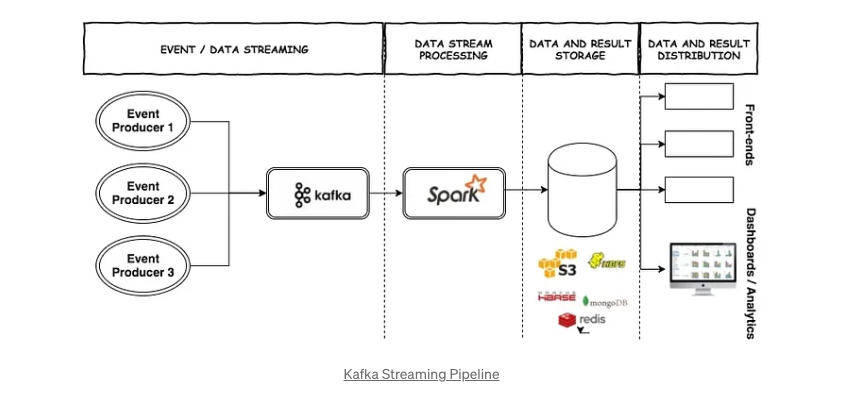
Apache Kafka:
用于构建实时数据管道和流应用的广泛使用平台。 为什么选择Kafka?
- 可以处理每秒数百万个事件。
- 可靠性:即使发生故障,数据也不会丢失:所有消息都写入磁盘并复制到多个代理,以确保它们不会丢失。
- 默认情况下,它保证至少一次传递。
- 回放数据:如果需要,可以重新播放数据。
- 高度可扩展:可以添加更多代理来处理不断增加的负载。分区器确保消息均匀分布在分区上:
- 强大的API和集成:用于与其他系统进行数据摄取的Kafka Connect。用于构建实时流应用程序的Kafka Streams。
- 安全功能,例如身份验证和加密,可用于保护数据在传输和静息时。 🔐
- 可定制和灵活:还允许设置消息的保留期。支持各种数据格式,包括文本、JSON、Avro和Protobuf。
- 支持多种模式和协议。
2. 原始存储(HDFS、S3)
这些系统将大数据分布在多台机器上,以提高可伸缩性和容错性。
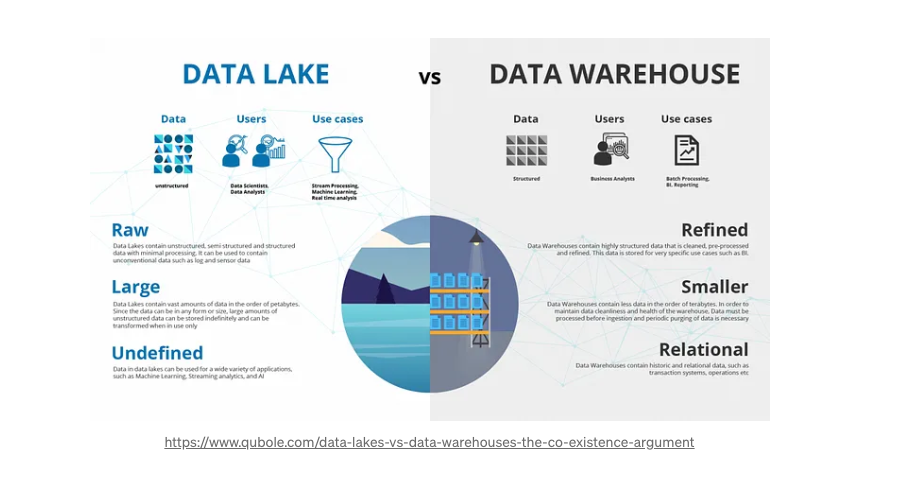
数据湖: 组织用来管理其PB级数据的大数据存储系统。 什么是数据湖?(AWS S3、Azure Data、Apache Hadoop/HDFS)
- 存储原始数据:它是大型、集中的非结构化和结构化数据仓库。
- 允许以其原始格式存储数据,无需先进行转换。
- 存储各种类型的数据:存储来自各种源头的大量数据,包括结构化、半结构化和非结构化数据。
用例:
- 想要支持组织中的多种用例,如分析、数据科学和临时分析。
- 想要以原始和未处理的格式存储大量数据,以便进行未来分析。
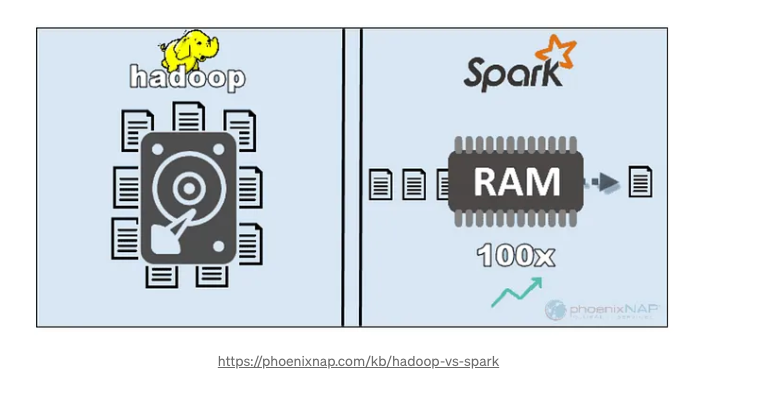
3. 处理(Hadoop、Spark)
(1) Hadoop是什么? Apache Hadoop是一个用于分布式存储和处理大型数据集的开源框架。
Hadoop的核心概念:
- HDFS: Hadoop分布式文件系统(HDFS)是Apache Hadoop框架的存储组件,旨在在分布式集群上存储和管理大量数据。
- 分布式存储:它将数据分割成块并在集群中的多个节点上复制,确保数据的可用性和韧性。
- 成本效益存储:HDFS利用常规硬件进行存储,使其成为存储大量数据的经济有效解决方案。
(2) MapReduce: 用于并行处理大型数据集的编程模型。
并行处理模型:它将任务分解成可以在集群中的节点上并行执行的小子任务。
(3) Hadoop的优势:
- 批处理工作负载
- 可接受较高的延迟
- 想要成本效益
(4) Hadoop的替代方案?
Apache Spark: 它是一个为大数据处理提供快速集群计算框架的开源分布式计算系统。
它是为解决MapReduce编程模型的局限性而开发的。
(5) Spark的亮点:
- 流处理:Spark支持批处理和流处理。
- 速度和性能:Spark执行内存处理,相比于依赖磁盘存储中间数据的Hadoop,性能显著提高。
(6) 转换和索引(Pig、Elasticsearch)
索引是什么?
索引是有关日志的附加元数据,旨在实现对整个日志体积的更快查询。
大数据中的索引是指创建允许从大型数据集中高效快速检索信息的数据结构的过程。在数据量庞大的情况下,索引对于优化查询性能和加速数据访问至关重要 。
倒排索引 工具:
Apache Pig脚本:Pig Latin是一种具有简单可读语法的数据流脚本语言。它由一系列语句组成,定义要应用于数据集的数据转换。
4. 数据库
NoSQL数据库: 专为处理大量非结构化和半结构化数据而设计。示例包括MongoDB、Cassandra和Apache HBase。
数据仓库: 针对大型数据集上的分析查询进行优化的专业数据库。 什么是数据仓库?(例如:Amazon Redshift、Snowflake)
- 为分析进行优化的存储:它是经过优化以进行报告和分析的结构化数据的集中存储库。
- 预定义的关系数据库架构
- 促进复杂查询和分析。
用例:
- 当要存储已经过处理、清理和转换以进行分析和报告的结构化数据时。
- 想要支持业务智能、报告和数据分析。
示例: Hive是构建在Hadoop之上的数据仓库基础设施。
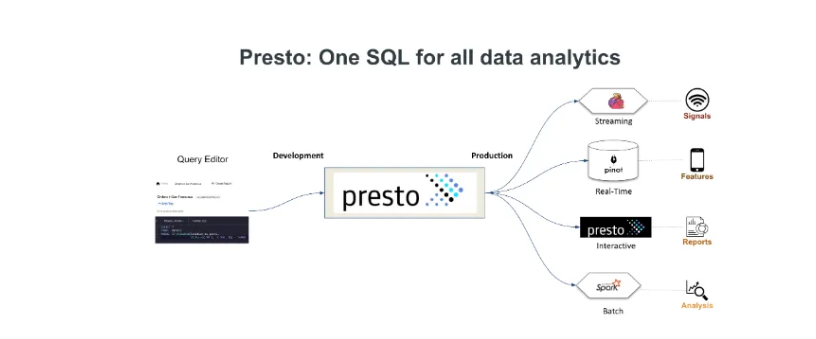
5. 分析(Presto、Spark SQL)
Presto是由Facebook创建的面向大数据的开源分布式SQL查询引擎。它专为在大型数据集上进行快速分析查询而开发。
SQL查询引擎 → 可以使用SQL语法!
主要特点:
- 多功能:它可以查询来自多个来源的数据,包括Hadoop、关系数据库(如MySQL、PostgreSQL)和其他数据存储。它提供了一个统一的界面,用于查询不同的数据集。
- SQL兼容性:它支持SQL语法,使其对习惯于关系数据库的用户来说更加熟悉。
- 高性能:它经过优化,可用于低延迟的交互式查询,适用于临时数据分析和业务智能。
- 复杂查询、连接、子查询:它支持复杂查询、连接、子查询和聚合,适用于各种分析任务。
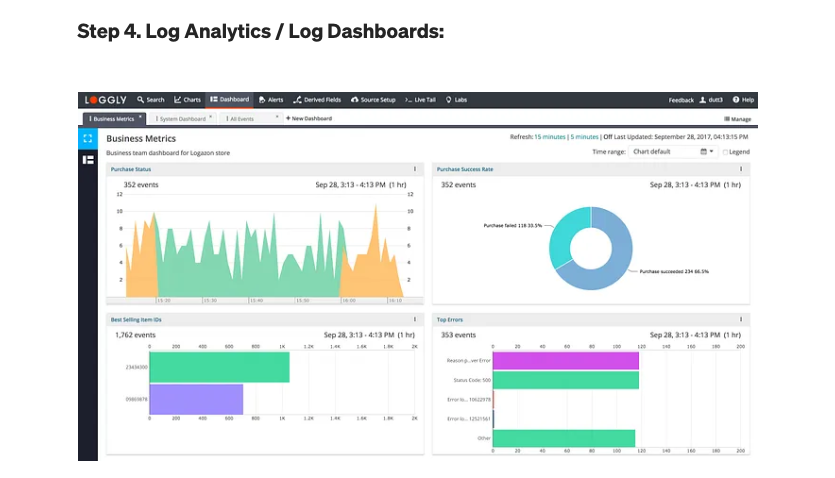
6. 可视化:(Kibana、Tableau)
- Tableau、Power BI、AWS QuickSight:用于创建交互式和可视化仪表板,以探索和传达来自大数据的见解的流行工具。
- Jupyter Notebooks:一种开源的Web应用程序,允许用户创建和共享包含实时代码、可视化和叙述文本的文档。