随着人工智能技术(AI)的日益普及,各种算法在推动这一领域的发展中发挥着关键作用。从预测房价的线性回归到自动驾驶汽车的神经网络,这些算法在背后默默支撑着无数应用的运行。

今天,我们将带您一览这些热门的人工智能算法(线性回归、逻辑回归、决策树、朴素贝叶斯、支持向量机(SVM)、集成学习、K近邻算法、K-means算法、神经网络、强化学习Deep Q-Networks ),探索它们的工作原理、应用场景以及在现实世界中的影响力。
1、线性回归:
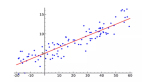
模型原理:线性回归试图找到一条最佳直线,使得这条直线能够尽可能地拟合散点图中的数据点。
模型训练:使用已知的输入和输出数据来训练模型,通过最小化预测值与实际值之间的平方误差来优化模型。
优点:简单易懂,计算效率高。
缺点:对非线性关系处理能力有限。
使用场景:适用于预测连续值的问题,如预测房价、股票价格等。

示例代码(使用Python的Scikit-learn库构建一个简单的线性回归模型):
from sklearn.linear_model import LinearRegression
from sklearn.datasets import make_regression
# 生成模拟数据集
X, y = make_regression(n_samples=100, n_features=1, noise=0.1)
# 创建线性回归模型对象
lr = LinearRegression()
# 训练模型
lr.fit(X, y)
# 进行预测
predictions = lr.predict(X)2、逻辑回归:
模型原理:逻辑回归是一种用于解决二分类问题的机器学习算法,它将连续的输入映射到离散的输出(通常是二进制的)。它使用逻辑函数将线性回归的结果映射到(0,1)范围内,从而得到分类的概率。
模型训练:使用已知分类的样本数据来训练逻辑回归模型,通过优化模型的参数以最小化预测概率与实际分类之间的交叉熵损失。
优点:简单易懂,对二分类问题效果较好。
缺点:对非线性关系处理能力有限。
使用场景:适用于二分类问题,如垃圾邮件过滤、疾病预测等。

示例代码(使用Python的Scikit-learn库构建一个简单的逻辑回归模型):
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# 生成模拟数据集
X, y = make_classification(n_samples=100, n_features=2, n_informative=2, n_redundant=0, random_state=42)
# 创建逻辑回归模型对象
lr = LogisticRegression()
# 训练模型
lr.fit(X, y)
# 进行预测
predictions = lr.predict(X)3、决策树:
模型原理:决策树是一种监督学习算法,通过递归地将数据集划分成更小的子集来构建决策边界。每个内部节点表示一个特征属性上的判断条件,每个分支代表一个可能的属性值,每个叶子节点表示一个类别。
模型训练:通过选择最佳划分属性来构建决策树,并使用剪枝技术来防止过拟合。
优点:易于理解和解释,能够处理分类和回归问题。
缺点:容易过拟合,对噪声和异常值敏感。
使用场景:适用于分类和回归问题,如信用卡欺诈检测、天气预报等。

示例代码(使用Python的Scikit-learn库构建一个简单的决策树模型):
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型对象
dt = DecisionTreeClassifier()
# 训练模型
dt.fit(X_train, y_train)
# 进行预测
predictions = dt.predict(X_test)4、朴素贝叶斯:
模型原理:朴素贝叶斯是一种基于贝叶斯定理和特征条件独立假设的分类方法。它将每个类别中样本的属性值进行概率建模,然后基于这些概率来预测新的样本所属的类别。
模型训练:通过使用已知类别和属性的样本数据来估计每个类别的先验概率和每个属性的条件概率,从而构建朴素贝叶斯分类器。
优点:简单、高效,对于大类别和小数据集特别有效。
缺点:对特征之间的依赖关系建模不佳。
使用场景:适用于文本分类、垃圾邮件过滤等场景。

示例代码(使用Python的Scikit-learn库构建一个简单的朴素贝叶斯分类器):
from sklearn.naive_bayes import GaussianNB
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 创建朴素贝叶斯分类器对象
gnb = GaussianNB()
# 训练模型
gnb.fit(X, y)
# 进行预测
predictions = gnb.predict(X)5、支持向量机(SVM):
模型原理:支持向量机是一种监督学习算法,用于分类和回归问题。它试图找到一个超平面,使得该超平面能够将不同类别的样本分隔开。SVM使用核函数来处理非线性问题。
模型训练:通过优化一个约束条件下的二次损失函数来训练SVM,以找到最佳的超平面。
优点:对高维数据和非线性问题表现良好,能够处理多分类问题。
缺点:对于大规模数据集计算复杂度高,对参数和核函数的选择敏感。
使用场景:适用于分类和回归问题,如图像识别、文本分类等。

示例代码(使用Python的Scikit-learn库构建一个简单的SVM分类器):
from sklearn import svm
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建SVM分类器对象,使用径向基核函数(RBF)
clf = svm.SVC(kernel='rbf')
# 训练模型
clf.fit(X_train, y_train)
# 进行预测
predictions = clf.predict(X_test)6、集成学习:
模型原理:集成学习是一种通过构建多个基本模型并将它们的预测结果组合起来以提高预测性能的方法。集成学习策略有投票法、平均法、堆叠法和梯度提升等。常见集成学习模型有XGBoost、随机森林、Adaboost等
模型训练:首先使用训练数据集训练多个基本模型,然后通过某种方式将它们的预测结果组合起来,形成最终的预测结果。
优点:可以提高模型的泛化能力,降低过拟合的风险。
缺点:计算复杂度高,需要更多的存储空间和计算资源。
使用场景:适用于解决分类和回归问题,尤其适用于大数据集和复杂的任务。

示例代码(使用Python的Scikit-learn库构建一个简单的投票集成分类器):
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建基本模型对象和集成分类器对象
lr = LogisticRegression()
dt = DecisionTreeClassifier()
vc = VotingClassifier(estimators=[('lr', lr), ('dt', dt)], voting='hard')
# 训练集成分类器
vc.fit(X_train, y_train)
# 进行预测
predictions = vc.predict(X_test)7、K近邻算法:
模型原理:K近邻算法是一种基于实例的学习,通过将新的样本与已知样本进行比较,找到与新样本最接近的K个样本,并根据这些样本的类别进行投票来预测新样本的类别。
模型训练:不需要训练阶段,通过计算新样本与已知样本之间的距离或相似度来找到最近的邻居。
优点:简单、易于理解,不需要训练阶段。
缺点:对于大规模数据集计算复杂度高,对参数K的选择敏感。
使用场景:适用于解决分类和回归问题,适用于相似度度量和分类任务。

示例代码(使用Python的Scikit-learn库构建一个简单的K近邻分类器):
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建K近邻分类器对象,K=3
knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train, y_train)
# 进行预测
predictions = knn.predict(X_test)8、K-means算法:
模型原理:K-means算法是一种无监督学习算法,用于聚类问题。它将n个点(可以是样本数据点)划分为k个聚类,使得每个点属于最近的均值(聚类中心)对应的聚类。
模型训练:通过迭代更新聚类中心和分配每个点到最近的聚类中心来实现聚类。
优点:简单、快速,对于大规模数据集也能较好地运行。
缺点:对初始聚类中心敏感,可能会陷入局部最优解。
使用场景:适用于聚类问题,如市场细分、异常值检测等。

示例代码(使用Python的Scikit-learn库构建一个简单的K-means聚类器):
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# 生成模拟数据集
X, y = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0)
# 创建K-means聚类器对象,K=4
kmeans = KMeans(n_clusters=4)
# 训练模型
kmeans.fit(X)
# 进行预测并获取聚类标签
labels = kmeans.predict(X)
# 可视化结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.show()9、神经网络:
模型原理:神经网络是一种模拟人脑神经元结构的计算模型,通过模拟神经元的输入、输出和权重调整机制来实现复杂的模式识别和分类等功能。神经网络由多层神经元组成,输入层接收外界信号,经过各层神经元的处理后,最终输出层输出结果。
模型训练:神经网络的训练是通过反向传播算法实现的。在训练过程中,根据输出结果与实际结果的误差,逐层反向传播误差,并更新神经元的权重和偏置项,以减小误差。
优点:能够处理非线性问题,具有强大的模式识别能力,能够从大量数据中学习复杂的模式。
缺点:容易陷入局部最优解,过拟合问题严重,训练时间长,需要大量的数据和计算资源。
使用场景:适用于图像识别、语音识别、自然语言处理、推荐系统等场景。
示例代码(使用Python的TensorFlow库构建一个简单的神经网络分类器):

import tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import mnist
# 加载MNIST数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 归一化处理输入数据
x_train = x_train / 255.0
x_test = x_test / 255.0
# 构建神经网络模型
model = models.Sequential()
model.add(layers.Flatten(input_shape=(28, 28)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
# 编译模型并设置损失函数和优化器等参数
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 进行预测
predictions = model.predict(x_test)10.深度强化学习(DQN):
模型原理:Deep Q-Networks (DQN) 是一种结合了深度学习与Q-learning的强化学习算法。它的核心思想是使用神经网络来逼近Q函数,即状态-动作值函数,从而为智能体在给定状态下选择最优的动作提供依据。
模型训练:DQN的训练过程包括两个阶段:离线阶段和在线阶段。在离线阶段,智能体通过与环境的交互收集数据并训练神经网络。在线阶段,智能体使用神经网络进行动作选择和更新。为了解决过度估计问题,DQN引入了目标网络的概念,通过使目标网络在一段时间内保持稳定来提高稳定性。
优点:能够处理高维度的状态和动作空间,适用于连续动作空间的问题,具有较好的稳定性和泛化能力。
缺点:容易陷入局部最优解,需要大量的数据和计算资源,对参数的选择敏感。
使用场景:适用于游戏、机器人控制等场景。

示例代码(使用Python的TensorFlow库构建一个简单的DQN强化学习模型):
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import backend as K
class DQN:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.85
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.005
self.model = self.create_model()
self.target_model = self.create_model()
self.target_model.set_weights(self.model.get_weights())
def create_model(self):
model = Sequential()
model.add(Flatten(input_shape=(self.state_size,)))
model.add(Dense(24, activation='relu'))
model.add(Dense(24, activation='relu'))
model.add(Dense(self.action_size, activation='linear'))
return model
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if len(self.memory) > 1000:
self.epsilon *= self.epsilon_decay
if self.epsilon < self.epsilon_min:
self.epsilon = self.epsilon_min
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
return np.argmax(self.model.predict(state)[0])