













Sora 的发布让整个 AI 领域为之狂欢,但 LeCun 是个例外。
面对 OpenAI 源源不断放出的 Sora 生成视频,LeCun 热衷于寻找其中的失误:

归根结底,LeCun 针对的不是 Sora,而是 OpenAI 从 ChatGPT 到 Sora 一致采用的自回归生成式路线。
LeCun 一直认为, GPT 系列 LLM 模型所依赖的自回归学习范式对世界的理解非常肤浅,远远比不上真正的「世界模型」。
所以,一遇到「Sora 是世界模型」的说法,LeCun 就有些坐不住:「仅仅根据 prompt 生成逼真视频并不能代表一个模型理解了物理世界,生成视频的过程与基于世界模型的因果预测完全不同。」

那么,面对视觉任务,世界模型如何获得自回归模型一般的性能?
最近,Lecun 发布了自己关于「世界模型」的新论文《在视觉表征学习中学习和利用世界模型》,刚好解释了这个问题。

- 论文标题:Learning and Leveraging World Models in Visual Representation Learning
- 论文链接:https://arxiv.org/pdf/2403.00504.pdf
通过以往 LeCun 对世界模型的介绍,我们知道,JEPA(Joint Embedding Predictive Architecture,联合嵌入预测架构)相比于重建像素的生成式架构(如变分自编码器)、掩码自编码器、去噪自编码器,更能产生优秀的视觉输入表达。
2023 年 6 月,Meta 推出了首个基于 LeCun 世界模型概念的 AI 模型,名为图像联合嵌入预测架构(I-JEPA),能够通过创建外部世界的内部模型来学习, 比较图像的抽象表征(而不是比较像素本身)。今年,在 Sora 发布的第二天,Meta 又推出了 AI 视频模型 V-JEPA,可根据信号的损坏或转换版本来预测信号的表征,让机器通过观察了解世界的运作方式。
而最新这项研究揭示了利用世界模型进行表征学习的另一个关键方面:赋予世界模型的容量直接影响所学表征的抽象程度。
直观地说,如果预测器是身份,网络将捕捉到高级语义信息,因为它只会学习编码输入 y 及其变换 x 之间的共同点。另一方面,由于预测器的容量更大,可以有效反转变换的效果,编码器的输出可以保留更多关于输入的信息。
这两个理念是等变表征学习的核心,能有效应用变换的预测器是等变的,而不能有效应用变换的预测器是不变的。研究者发现,对变换不变的世界模型在线性评估中表现更好,而等变的世界模型与更好的世界模型微调相关。这就在易适应性和原始性能之间做出了权衡。因此,通过学习世界模型来学习表征,能灵活掌握表征的属性,从而使其成为一个极具吸引力的表征学习框架。
接下来,我们来看一些具体的研究细节。
方法
图像世界模型(Image World Models,IWM)采用 JEPA 的框架,类似于 I-JEPA。该框架中的预测器是世界模型的实例化。研究者认为,如果一个世界模型能够在潜在空间中应用变换,从而学习等变表征,那么它就是有能力的。研究者将有能力的世界模型为等变( equivariant ),称能力较差的世界模型为不变( invariant )。
使用 JEPA 的一个吸引人之处在于,使用对比方法学习等变表征的方法通常需要依赖于不变性损失来提高表征质量,无论是显式的还是隐式的。而 JEPA 的方法则不存在这一缺点,因为表征的语义方面是通过潜在空间的修补学习的。在潜空间中工作还能让网络去除不必要的信息或难以预测的信息。这就使得 JEPA 方案很有吸引力,因为对于重建方法来说,重建的质量不一定与表征质量相关。
要训练 IWM,第一步是从图像 I 生成源视图和目标视图(图 2 中分别为 x 和 y)。

研究者将 a_x→y 表示为从 x 到 y 的变换参数,即初始变换过程的逆转。它包含了 x 与 y 之间颜色抖动差异的信息,以及是否应用了每种破坏性增强的信息。
通过 p_ϕ 进行世界建模。然后分别通过编码器 f_θ 和它的指数移动平均
得到源和目标。这样就有了  和
和  。使用 EMA 网络对避免解决方案崩溃至关重要。为了给作为世界模型的预测器设置条件,它被输入了关于目标的几何信息,以掩码 token 的形式以及 a_x→y。研究者将这些掩码 token 称为 m_a,它们对应于
。使用 EMA 网络对避免解决方案崩溃至关重要。为了给作为世界模型的预测器设置条件,它被输入了关于目标的几何信息,以掩码 token 的形式以及 a_x→y。研究者将这些掩码 token 称为 m_a,它们对应于  中的位置。
中的位置。
然后,预测器 p_ϕ 将嵌入的源补丁 x_c、变换参数 a_x→y 和遮罩令牌 m_a 作为输入。其目标是匹配 p_ϕ(z_x, a_x→y, m_a) =  到 z_y。损失。使用的损失函数是预测
到 z_y。损失。使用的损失函数是预测  及其目标 z_y 之间的平方 L2 距离:
及其目标 z_y 之间的平方 L2 距离:

学习用于表征学习的图像世界模型
如前所述,学习等差数列表征和学习世界模型是密切相关的问题。因此,可以借用等差数学文献中的指标来评估训练好的世界模型的质量。研究者使用的主要指标是平均互斥等级(MRR)。
为了计算它,研究者生成了一组增强目标图像(实际为 256 幅)。他们通过预测器输入干净图像的表征,目的是预测目标图像。然后计算预测结果与增强表征库之间的距离,从中得出目标图像在该 NN 图中的等级。通过对多个图像和变换的倒数等级进行平均,就可以得到 MRR,从而了解世界模型的质量。MRR 接近 1 意味着世界模型能够应用变换,相反,MRR 接近 0 则意味着世界模型不能应用变换。
为了构建性能良好的 IWM,研究者分离出三个关键方面:预测器对变换(或操作)的条件限制、控制变换的复杂性以及控制预测器的容量。如果对其中任何一个环节处理不当,都会导致表征不稳定。
如表 1 所示,不进行调节会导致世界模型无法应用变换,而使用序列轴或特征轴进行调节则会导致良好的世界模型。研究者在实践中使用了特征调节,因为它能带来更高的下游性能。

如表 2 所示,增强越强,学习强世界模型就越容易。在更广泛的增强方案中,这一趋势仍在继续。

如果变换很复杂,预测器就需要更大的能力来应用它,意味着能力成为了学习图像世界模型的关键因素。如上表 2 ,深度预测器意味着能在更广泛的增强上学习到强大的世界模型,这也是 IWM 取得成功的关键。因此,预测能力是强大世界模型的关键组成部分。
与计算 MRR 的方法相同,我们可以将预测的表征与变换图像库进行比较,并查看与预测最近邻的图像。如图 1 所示,IWM 学习到的世界模型能够正确应用潜空间中的变换。不过,可以看到灰度反转时存在一些误差,因为灰度无法正确反转。
以下可视化效果有助于强化 IWM 能够为图像转换学习强大的世界模型这一事实。

利用世界模型完成下游任务
论文还探讨了如何使用世界模型完成下游任务。
在图像上学习的世界模型的局限性在于,它们所解决的任务与大多数下游任务并不一致。
研究者表示,已经证明 IWM 可以应用色彩抖动或对图像进行着色,但这些并不是推动计算机视觉应用的任务。这与 LLM 形成了鲜明对比,在 LLM 中,预测下一个 token 是此类模型的主要应用之一。
因此,研究者探索了如何在视觉中利用世界模型来完成应用变换之外的任务,重点是图像分类和图像分割等判别任务。
首先,需要对预测器进行微调以解决判别任务。研究者按照 He et al. (2021) 的方法,重点放在与微调协议的比较上。所研究的所有方法都在 ImageNet 上进行了预训练和评估,并使用 ViT-B/16 作为编码器。
表 3 展示了定义预测任务的各种方法及其对性能的影响。

表 4 中比较了预测器微调和编码器微调以及预测器和编码器的端到端微调,编码器使用了 ViTB/16。

从表 5 中可以看出,在对所有协议的性能进行汇总时,利用 IWM 可以在冻结编码器的情况下获得最佳性能,即允许利用预训练的每一部分。

表 6 展示了 I-JEPA 和 IWM 在 ADE20k 图像分割任务中的表现。

在图 3 中,展示了预测器微调与编码器微调相比的效率。

表征学习的主要目标之一是获得可用于各种任务的表征。就像预测器是为解决各种任务(着色、内画、变色)而训练的一样,对于每个任务,都有一个任务 token,以及一个任务特定的头和 / 或损失函数。然后合并所有任务损失,并更新预测器和特定任务头。这里研究了一种简单的情况,即批次在任务之间平均分配,同时注意到其他采样策略可能会进一步提高性能。
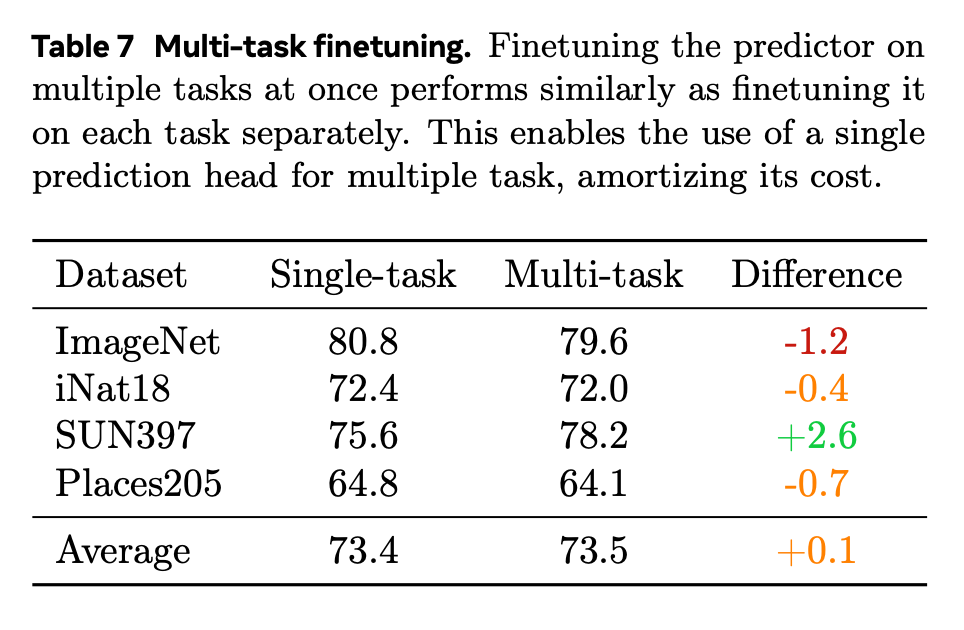
总之,当学习到一个好的世界模型后,通过微调就可以将其重新用于下游任务。这样就能以极低的成本实现与编码器微调相媲美的性能。通过进行多任务微调,它还能变得更加高效,更凸显了这种方法的多功能性。
图像世界模型使表征更加灵活
为了完成对 IWM 在表征学习中的分析,研究者研究了它在自监督学习中常用的轻量级评估协议上的表现。本文重点关注线性探测和注意力探测。
如表 8 所示,当 IWM 学习一个不变的世界模型时,其表现类似于对比学习方法,如 MoCov3,在线性探测中与 MIM 或其他基于 JEPA 的方法相比有显著的性能提升。同样,当 IWM 学习一个等变的世界模型时,其表现类似于 MIM 方法,如 MAE,在线性探测中性能较低,但在注意力探测中表现更具竞争力。

这表明,方法之间的重大区别不一定在于表征的质量,而在于它们的抽象级别,即从中提取信息的难易程度。线性探测是最简单的评估之一,注意力探测稍微复杂一些,而微调则是更复杂的协议。
图 4 可以看出,评估协议的适用性与世界模型的等价性之间有着明显联系。不变性较高的世界模型在线性探测中表现出色,而等变世界模型在使用更大的评估头部,如在预测器微调中,有组合更好的表现。研究者们还注意到,由等变世界模型产生的更丰富的表征在跨域 OOD 数据集上具有更好的性能。

图 5 中按表征的抽象程度将方法分类。对比学习方法占据了高抽象度的一端,只需一个简单的协议就能轻松提取信息。然而,如表 5 所示,当忽略调整成本时,这些方法的峰值性能较低。与之相反的是掩蔽图像建模法(MIM),它在微调等复杂评估中性能更强,但在线性探测中由于信息不易获取而表现不佳。通过改变世界模型的等变性,IWM 能够在对比学习方法和 MIM 之间有属于自己的位置,如图 4 和表 8 所示, 和
和  是 IWM 光谱的两个极端。
是 IWM 光谱的两个极端。

这个光谱可以用自监督学习(SSL)的理念「学习可预测之物」来概括。通过一个弱世界模型进行学习意味着它无法正确地建模世界,编码器会移除那些无法预测的信息。反之,如果世界模型非常强大,那么表征就不需要那么抽象或语义化,因为它能够在任何情况下找到预测表征的方法。这意味着,学习一个世界模型提供了一种可度量的方式来控制表征的抽象级别。
更多技术细节,请参阅原文。






























