













在Kubernetes中,有时候我们需要更精确地控制Pod的调度,将其分配到集群中特定的节点上。kubernetes对Pod的调度规则,kubernetes提供了四大类调度方式:
- 自动调度:运行在哪个节点上完全由Scheduler经过一系列的算法计算得出
- 定向调度:NodeName、NodeSelector
- 亲和性调度:NodeAffinity、PodAffinity、PodAntiAffinity
- 污点(容忍)调度:Taints、Toleration
本教程将向您介绍两种方法:使用定向调度和亲和性调度,以确保Pod只在我们指定的节点上运行。

一、定向调度
1.什么是NodeSelector
NodeSelector 是 Kubernetes 中一种用于调度 Pod 到特定节点的机制。通过在 Pod 的配置中定义 nodeSelector 字段,您可以为 Pod 指定一组键值对标签。这些标签将与集群中的节点标签进行匹配,以确定 Pod 应该被调度到哪个节点上运行。
具体而言,nodeSelector 允许您按照节点的标签选择性地将 Pod 调度到集群中。这种机制非常适用于具有特定硬件要求或运行特定环境的 Pod,以确保它们在正确的节点上运行。
2.NodeSelector基本用法
此 Pod 配置文件描述了一个拥有节点选择器 disktype: ssd 的 Pod。这表明该 Pod 将被调度到有 disktype=ssd 标签的节点。
apiVersion:v1
kind:Pod
metadata:
name:nginx
labels:
env:test
spec:
containers:
-name:nginx
image:nginx
imagePullPolicy:IfNotPresent
nodeSelector:
disktype:ssd以下通过案例演示的方式来阐述NodeSelector的基本用法:
(1) 列出你的集群中的节点, 包括这些节点上的标签,输出类似如下:
controlplane $ kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
controlplane Ready control-plane 12h v1.29.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=controlplane,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
node01 Ready <none> 12h v1.29.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux(2) 从你的节点中选择一个,为它添加标签
kubectl label nodes node01 disktype=ssd(3) 验证你选择的节点确实带有 disktype=ssd 标签:

(4) 创建一个将被调度到你选择的节点的Pod:
kubectl create -f pod-nginx.yaml- pod-nginx.yaml文件的内容是上述yaml所示。
- 创建成功后这个pod会调度到包含有disktype=ssd的标签中
执行成功后,验证Pod 确实运行在你选择的节点上:
controlplane $ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 11s 192.168.1.4 node01 <none> <none>我们还可以通过设置spec.nodeName参数将某个Pod 调度到特定的节点。演示yaml如下:
apiVersion:v1
kind:Pod
metadata:
name:nginx
spec:
nodeName:foo-node# 调度 Pod 到特定的节点
containers:
-name:nginx
image:nginx
imagePullPolicy:IfNotPresent二、亲和性调度
kubernetes还提供了一种亲和性调度(Affinity)。它在NodeSelector的基础之上的进行了扩展,可以通过配置的形式,实现优先选择满足条件的Node进行调度,如果没有,也可以调度到不满足条件的节点上,使调度更加灵活。Affinity主要分为三类:
- nodeAffinity(node亲和性): 以node为目标,解决pod可以调度到哪些node的问题
- podAffinity(pod亲和性) : 以pod为目标,解决pod可以和哪些已存在的pod部署在同一个拓扑域中的问题
- podAntiAffinity(pod反亲和性) : 以pod为目标,解决pod不能和哪些已存在pod部署在同一个拓扑域中的问题
11.NodeAffinity
NodeAffinity意为Node亲和性调度策略。是用于替换NodeSelector的全新调度策略。目前有两种节点节点亲和性表达:
- RequiredDuringSchedulingIgnoredDuringExecution:必须满足制定的规则才可以调度pode到Node上。相当于硬限制。
- PreferredDuringSchedulingIgnoreDuringExecution:强调优先满足制定规则,调度器会尝试调度pod到Node上,但并不强求,相当于软限制。多个优先级规则还可以设置权重值,以定义执行的先后顺序。
首先来看一下NodeAffinity的可配置项:
pod.spec.affinity.nodeAffinity
requiredDuringSchedulingIgnoredDuringExecution #Node节点必须满足指定的所有规则才可以,相当于硬限制
nodeSelectorTerms #节点选择列表
matchFields #按节点字段列出的节点选择器要求列表
matchExpressions #按节点标签列出的节点选择器要求列表(推荐)
key #键
values #值
operat or #关系符 支持Exists, DoesNotExist, In, NotIn, Gt, Lt
preferredDuringSchedulingIgnoredDuringExecution #优先调度到满足指定的规则的Node,相当于软限制 (倾向)
preference #一个节点选择器项,与相应的权重相关联
matchFields #按节点字段列出的节点选择器要求列表
matchExpressions # 按节点标签列出的节点选择器要求列表(推荐)
key #键
values #值
operator #关系符 支持In, NotIn, Exists, DoesNotExist, Gt, Lt
weight #倾向权重,在范围1-100。例如,下面这个Pod需要部署到不是disktype=ssd标签上的node上。
apiVersion:v1
kind:Pod
metadata:
name:nginx
labels:
env:test
spec:
containers:
-name:nginx
image:nginx
imagePullPolicy:IfNotPresent
affinity:
nodeAffinity:#设置node亲和性
requiredDuringSchedulingIgnoredDuringExecution:# 硬限制
nodeSelectorTerms:
-matchExpressions:
-key:disktype
operator:NotIn
values:["ssd"]执行创建命令后,该pod会被调度标签disktype值中不包含ssd这个值的node上。
controlplane $ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 20s 192.168.0.4 controlplane <none> <none>
controlplane $ kubectl get node --show-labels
NAME STATUS ROLES AGE VERSION LABELS
controlplane Ready control-plane 15h v1.29.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=controlplane,kubernetes.io/os=linux,node-role.kubernetes.io/control-plane=,node.kubernetes.io/exclude-from-external-load-balancers=
node01 Ready <none> 14h v1.29.0 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,disktype=ssd,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux2.podAffinity
podAffinity 是 Kubernetes 中的一种调度机制,它允许您指定一组条件,以影响 Pod 之间的调度关系。具体而言,podAffinity 允许您在同一节点上调度具有相似属性或关系的 Pod,或者在不同节点上调度具有相关属性的 Pod。podAffinity 同样通过 requiredDuringSchedulingIgnoredDuringExecution 和 preferredDuringSchedulingIgnoredDuringExecution两种方式来实现。下面通过实例来说明 Pod 间的亲和性和互斥性策略设置。
(1) 参照目标Pod
首先,创建一个名为 pod-flag 的 Pod ,带有标签 security=S1 和 app=nginx ,后面的例子将使用 pod-flag 作为 Pod 亲和与互斥的目标 Pod 。
apiVersion:v1
kind:Pod
metadata:
name:pod-flag
labels:
security:"S1"
app:nginx
spec:
containers:
-name:nginx
image:nginx(2) Pod的亲和性调度
下面创建第 2 个 Pod 来说明 Pod 的亲和性调度,这里定义的亲和标签是security=S1 ,对应上面的 Pod pod-flag, topologyKey 的值被设置为 kubemetes.io/hostname
apiVersion:v1
kind:Pod
metadata:
name:pod-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
-labelSelector:
matchExpressions:
-key:security
operator:In
values:
-S1
topologyKey:kubernetes.io/hostname
containers:
-name:with-pod-affinity
image:nginx两个Pod创建成功后,使用kubectl get pods -o wide命令可以看到,这两个 Pod 处于同一个 Node之上运行 。
controlplane $ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity 1/1 Running 0 8s 192.168.1.5 node01 <none> <none>
pod-flag 1/1 Running 0 94s 192.168.1.4 node01 <none> <none>在创建pod-affinity这个Pod 之前,删掉这个节点的kubemetes.io/hostname标签,重复上面的创建步骤,将会发现 Pod 会一直处于 Pending 状态,这是因为找不到满足条件的 Node 了。
controlplane $ kubectl label node node01 kubernetes.io/hostname-
node/node01 unlabeled
controlplane $ kubectl get pod
NAME READY STATUS RESTARTS AGE
pod-affinity 1/1 Running 0 4m49s
pod-flag 1/1 Running 0 6m15s
controlplane $ kubectl delete pod pod-affinity
pod "pod-affinity" deleted
controlplane $ kubectl apply -f pod-affinity.yaml
pod/pod-affinity created
controlplane $ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-affinity 0/1 Pending 0 16s <none> <none> <none> <none>
pod-flag 1/1 Running 0 6m59s 192.168.1.4 node01 <none> <none>(3) Pod的互斥性调度
创建第3个Pod , 我们希望它不能与参照目标 Pod 运行在同一个Node 上 。
apiVersion:v1
kind:Pod
metadata:
name:anti-affinity
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
-labelSelector:
matchExpressions:
-key:security
operator:In
values:
-S1
topologyKey:beta.kubernetes.io/arch
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
-labelSelector:
matchExpressions:
-key:app
operator:In
values:
-nginx
topologyKey:kubernetes.io/hostname
containers:
-name:anti-affinity
image:registry.aliyuncs.com/google_containers/pause:3.1这里要求这个新 Pod 与 security=S1 的 Pod 为同一个arch平台 ,但是不与 app=nginx 的 Pod 为同一个 Node 。创建 Pod 之后,同样用kubectl get pods -o wide 来查看,会看到新的 Pod 被调度到了其他arch平台 内的不同的 Node 上去。
controlplane $ kubectl apply -f anti-affinity.yaml
pod/anti-affinity created
controlplane $ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
anti-affinity 1/1 Running 0 6s 192.168.0.6 controlplane <none> <none>
pod-affinity 1/1 Running 0 24m 192.168.1.6 node01 <none> <none>
pod-flag 1/1 Running 0 31m 192.168.1.4 node01 <none> <none>三、CKA真题
1.真题截图
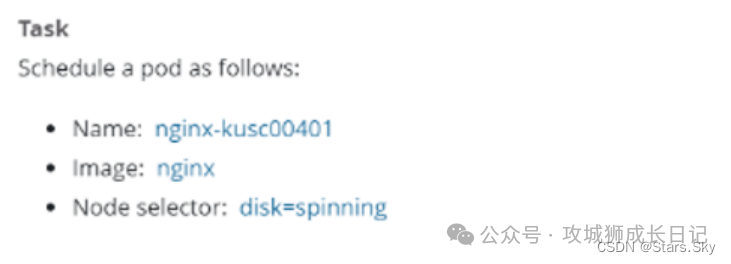
2.中文解析
切换 k8s 集群环境:kubectl config use-context k8sTask:创建一个 Pod,名字为 nginx-kusc00401,镜像地址是 nginx,调度到具有 disk=spinning 标签的节点上。
3.官方参考文档
指定Pod调度到某个Node
4.解题作答
切换切换k8s集群环境:
kubectl config use-context k8s创建Pod的资源对象:
apiVersion:v1
kind:Pod
metadata:
name:nginx-kusc00401
spec:
containers:
-name:nginx
image:nginx
imagePullPolicy:IfNotPresent
nodeSelector:
disk:spinning
执行命令创建pod:
kubectl apply -f nginx-kusc00401.yaml
























