原标题:Anything in Any Scene: Photorealistic Video Object Insertion
论文链接:https://arxiv.org/pdf/2401.17509.pdf
代码链接:https://github.com/AnythingInAnyScene/anything_in_anyscene
作者单位:小鹏汽车

论文思路
逼真的(realistic)视频仿真(video simulation)在从虚拟现实到电影制作等各种应用领域都显示出巨大的潜力。尤其是在现实世界中捕捉视频不切实际或成本高昂的情况下。视频仿真中的现有方法通常无法准确地建模光照环境、表示物体几何形状或实现高水平的照片级真实感。本文提出了 Anything in Any Scene ,这是一种新颖且通用的真实视频仿真框架,可以将任何物体无缝插入到现有的动态视频中,并强调物理真实感。本文提出的总体框架包含三个关键过程:1)将真实的物体集成到给定的场景视频中,并放置适当的位置以确保几何真实感(geometric realism);2)估计天空和环境光照分布并模拟真实阴影,增强光照真实感(light realism);3)采用风格迁移网络来细化最终的视频输出,以最大限度地提高照片真实感(photorealism)。本文通过实验证明 Anything in Any Scene 框架可以生成具有出色的几何真实感、光照真实感和照片真实感的仿真视频。通过显着缓解与视频数据生成相关的挑战,本文的框架为获取高质量视频提供了高效且经济高效的解决方案。此外,其应用远远超出了视频数据增强的范围,在虚拟现实、视频编辑和各种其他以视频为中心的应用中显示出广阔的潜力。
主要贡献
本文引入了一种新颖且可扩展的 Anything in Any Scene 视频仿真框架,能够将任何物体集成到任何动态场景视频中。
本文的框架独特地专注于在视频仿真中保留几何真实感、光照真实感和照片真实感,确保高质量和真实的输出。
本文进行了广泛的验证,证明该框架有能力制作逼真的视频仿真,极大地扩展了该领域的应用范围和潜力。
论文设计
图像和视频仿真在从虚拟现实到电影制作的各种应用中都取得了成功。通过逼真的图像和视频仿真生成多样化和高质量的视觉内容的能力具有推动这些领域发展的潜力,能够引入新的可能性和应用。尽管在现实世界中捕获的图像和视频的真实性非常宝贵,但它们经常受到长尾分布的限制。这导致常见场景的代表性过高,而罕见但关键的情况的代表性不足,从而提出了称为 out-of-distribution problem 的挑战。通过视频采集和编辑来解决这些限制的传统方法被证明是不切实际的或成本过高,因为难以涵盖所有可能的情况。视频仿真的重要性,特别是通过将现有视频与新插入的物体相集成,对于克服这些挑战变得至关重要。通过生成大规模、多样化和逼真的视觉内容,视频仿真有助于增强虚拟现实、视频编辑和视频数据增强方面的应用。
然而,考虑物理真实性生成逼真的仿真视频仍然是一个具有挑战性的开放问题。现有方法通常因专注于特定设置而表现出局限性,特别是室内环境[9,26,45,46,57]。这些方法可能无法充分解决室外场景的复杂性,包括不同的光照条件和快速移动的物体。依赖 3D 模型配准的方法仅限于集成有限类别的物体 [12,32,40,42]。许多方法忽略了一些重要因素,例如光照环境建模、正确的物体放置和实现真实感 [12, 36]。失败的案例如图 1 所示。因此,这些限制极大地限制了它们在需要高度可扩展、几何一致和真实场景视频仿真的领域(例如自动驾驶和机器人)中的应用。
本文提出了一个用于解决这些挑战的逼真视频物体插入的综合框架 Anything in Any Scene。该框架设计具有通用性,适用于室内和室外场景,保证几何真实感、光照真实感和照片真实感等方面的物理准确性。本文的目标是创建视频仿真,不仅有利于机器学习中的视觉数据增强,而且适用于各种视频应用,例如虚拟现实和视频编辑。
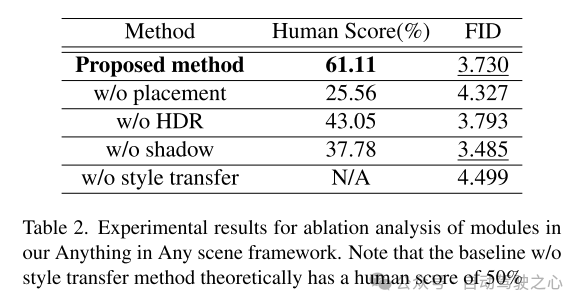
本文的 Anything in Any Scene 框架的概述如图 2 所示。本文在第 3 节中详细介绍了本文新颖且可扩展的流程,用于构建场景视频和物体网格(object mesh)的多样化资产库。本文介绍了一种视觉数据查询引擎,旨在利用描述性关键词从视觉查询中高效检索相关视频片段。接下来,本文提出两种生成 3D meshes 的方法,利用现有 3D 资产以及多视图图像重建。这允许不受限制地插入任何所需的物体,即使它非常不规则或语义较弱。在第 4 节中,本文详细介绍了将物体集成到动态场景视频中的方法,重点是保持物理真实感。本文设计了第 4.1 节中描述的物体放置和稳定方法,确保插入的物体稳定地锚定(anchored)在连续的视频帧上。为了解决创建逼真的光照和阴影效果的挑战,本文估计天空和环境光照并在渲染过程中生成逼真的阴影,如第 4.2 节所述。生成的仿真视频帧不可避免地包含与现实世界捕获的视频不同的不现实的伪影,例如噪声水平、色彩保真度和清晰度方面的成像质量差异。本文在 4.3 节中采用风格迁移网络来增强照片真实感。
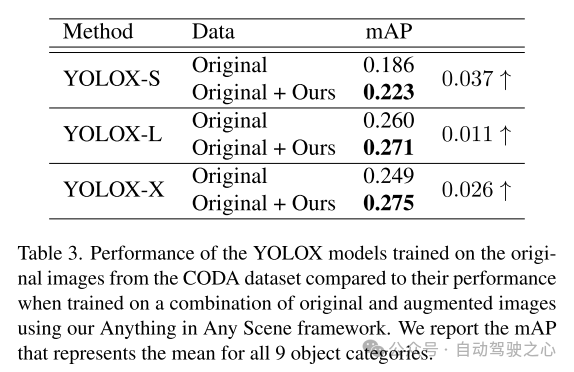
从本文提出的框架生成的仿真视频达到了高度的光照真实感、几何真实感和照片真实感,在质量和数量上都优于其他视频,如第 5.3 节所示。本文在5.4节中进一步展示了本文的仿真视频在训练感知算法中的应用,以验证其实用价值。Anything in Any Scene 框架能够创建大规模、低成本的视频数据集,用于具有时间效率和逼真视觉质量的数据增强,从而减轻视频数据生成的负担,并有可能改善长尾分布和分布外的挑战。凭借其通用的框架设计,Anything in Any Scene 框架可以轻松整合改进的模型和新模块,例如改进的 3D mesh 重建方法,进一步增强视频仿真性能。
 图 1. 光照环境估计错误、物体摆放位置错误和纹理风格不真实的仿真视频帧示例,这些问题使得图像缺乏物理真实感。
图 1. 光照环境估计错误、物体摆放位置错误和纹理风格不真实的仿真视频帧示例,这些问题使得图像缺乏物理真实感。 图 2. 用于逼真视频物体插入的 Anything in Any Scene 框架概述
图 2. 用于逼真视频物体插入的 Anything in Any Scene 框架概述 图 3. 用于放置物体的驾驶场景视频示例。每幅图像中的红点是物体插入的位置。
图 3. 用于放置物体的驾驶场景视频示例。每幅图像中的红点是物体插入的位置。
实验结果

图 4. 原始天空图像、重建的 HDR 图像及其相关的太阳光照分布图的示例

图 5. 原始和重建的 HDR 的环境全景图像示例

图 6. 为插入的物体生成阴影的示例

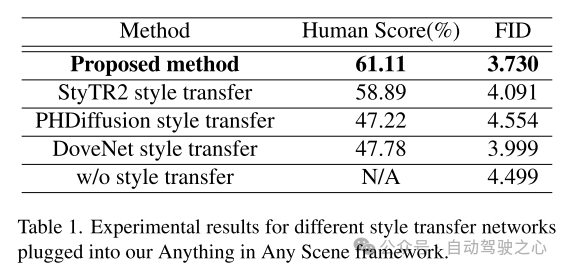
图 7. 使用不同风格迁移网络对 PandaSet 数据集的仿真视频帧进行定性比较。

图 8. PandaSet 数据集的仿真视频帧在各种渲染条件下的定性比较。
总结:
本文提出了一个创新且可扩展的框架,”Anything in Any Scene",专为逼真的视频仿真而设计。本文提出的框架将各种物体无缝集成到不同的动态视频中,确保保留几何真实感、光照真实感和照片真实感。通过广泛的演示,本文展示了其在缓解视频数据收集和生成相关挑战方面的功效,提供了适用于各种场景的经济高效且省时的解决方案。本文的框架的应用在下游感知任务中显示出显着的改进,特别是在解决目标检测中的长尾分布问题方面。本文框架的灵活性允许直接集成每个模块的改进模型,本文的框架为逼真视频仿真领域的未来探索和创新奠定了坚实的基础。
引用:
Bai C, Shao Z, Zhang G, et al. Anything in Any Scene: Photorealistic Video Object Insertion[J]. arXiv preprint arXiv:2401.17509, 2024.