












最近,OpenAI 的视频生成模型 Sora 爆火,生成式 AI 模型在多模态方面的能力再次引起广泛关注。
现实世界本质上是多模态的,生物体通过不同的渠道感知和交换信息,包括视觉、语言、声音和触觉。开发多模态系统的一个有望方向是增强 LLM 的多模态感知能力,主要涉及多模态编码器与语言模型的集成,从而使其能够跨各种模态处理信息,并利用 LLM 的文本处理能力来产生连贯的响应。
然而,该策略仅限于文本生成,不包含多模态输出。一些开创性工作通过在语言模型中实现多模态理解和生成取得了重大进展,但这些模型仅包含单一的非文本模态,例如图像或音频。
为了解决上述问题,复旦大学邱锡鹏团队联合 Multimodal Art Projection(MAP)、上海人工智能实验室的研究者提出了一种名为 AnyGPT 的多模态语言模型,该模型能够以任意的模态组合来理解和推理各种模态的内容。具体来说,AnyGPT 可以理解文本、语音、图像、音乐等多种模态交织的指令,并能熟练地选择合适的多模态组合进行响应。
例如给出一段语音 prompt,AnyGPT 能够生成语音、图像、音乐形式的综合响应:
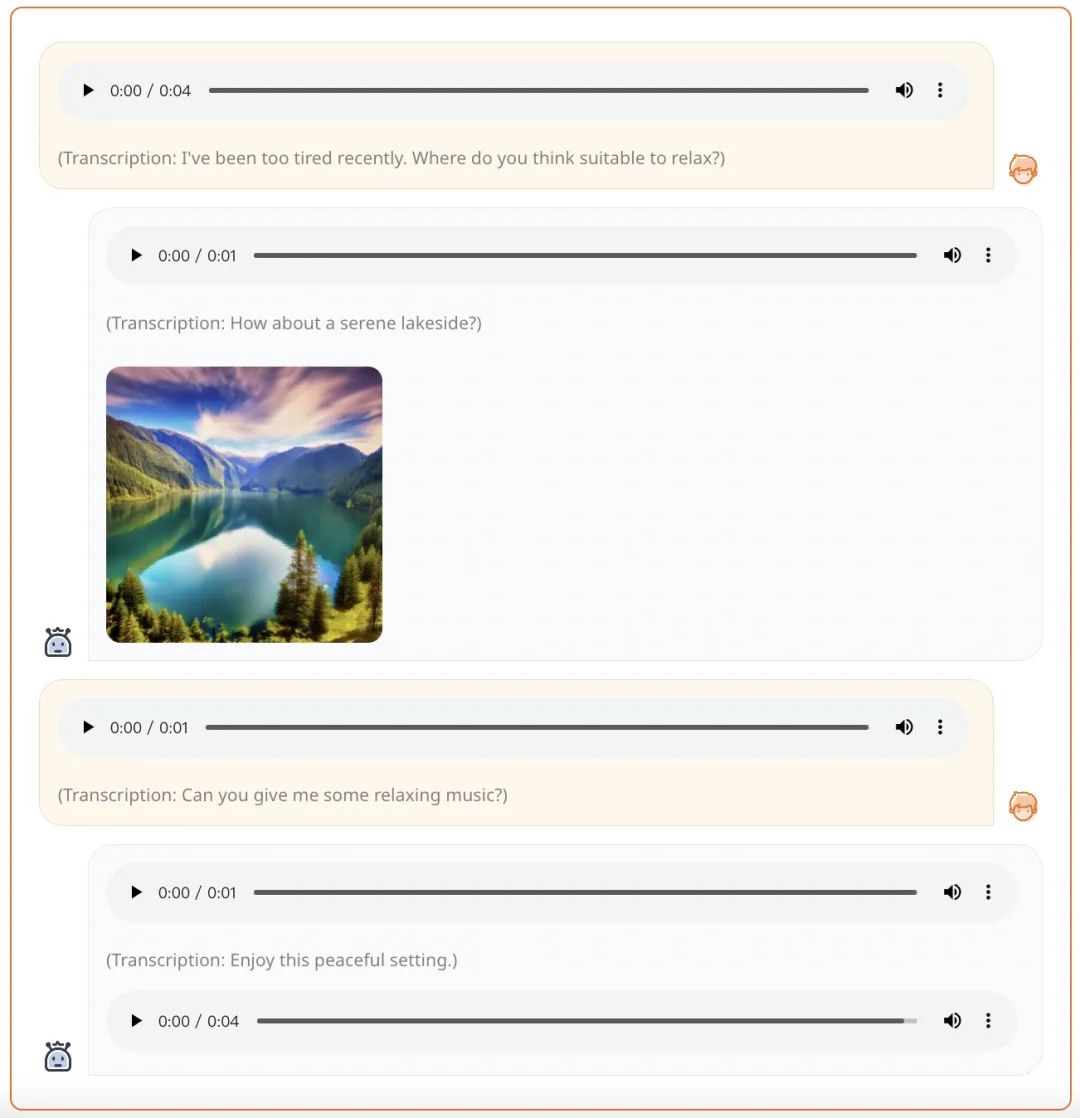
给出文本 + 图像形式的 prompt,AnyGPT 能够按照 prompt 要求生成音乐:


- 论文地址:https://arxiv.org/pdf/2402.12226.pdf
- 项目主页:https://junzhan2000.github.io/AnyGPT.github.io/
方法简介
AnyGPT 利用离散表征来统一处理各种模态,包括语音、文本、图像和音乐。
为了完成任意模态到任意模态的生成任务,该研究提出了一个可以统一训练的综合框架。如下图 1 所示,该框架由三个主要组件组成,包括:
- 多模态 tokenizer
- 作为主干网络的多模态语言模型
- 多模态 de-tokenizer

其中,tokenizer 将连续的非文本模态转换为离散的 token,随后将其排列成多模态交错序列。然后,语言模型使用下一个 token 预测训练目标进行训练。在推理过程中,多模态 token 被相关的 de-tokenizer 解码回其原始表征。为了丰富生成的质量,可以部署多模态增强模块来对生成的结果进行后处理,包括语音克隆或图像超分辨率等应用。
AnyGPT 可以稳定地训练,无需对当前的大型语言模型(LLM)架构或训练范式进行任何改变。相反,它完全依赖于数据级预处理,使得新模态无缝集成到 LLM 中,类似于添加新语言。
这项研究的一个关键挑战是缺乏多模态交错指令跟踪数据。为了完成多模态对齐预训练,研究团队利用生成模型合成了第一个大规模「任意对任意」多模态指令数据集 ——AnyInstruct-108k。它由 108k 多轮对话样本组成,这些对话错综复杂地交织着各种模态,从而使模型能够处理多模态输入和输出的任意组合。


这些数据通常需要大量比特才能准确表征,从而导致序列较长,这对语言模型的要求特别高,因为计算复杂度随着序列长度呈指数级增加。为了解决这个问题,该研究采用了两阶段的高保真生成框架,包括语义信息建模和感知信息建模。首先,语言模型的任务是生成在语义层面经过融合和对齐的内容。然后,非自回归模型在感知层面将多模态语义 token 转换为高保真多模态内容,在性能和效率之间取得平衡。


实验
实验结果表明,AnyGPT 能够完成任意模态对任意模态的对话任务,同时在所有模态中实现与专用模型相当的性能,证明离散表征可以有效且方便地统一语言模型中的多种模态。
该研究评估了预训练基础 AnyGPT 的基本功能,涵盖所有模态的多模态理解和生成任务。该评估旨在测试预训练过程中不同模态之间的一致性,具体来说是测试了每种模态的 text-to-X 和 X-to-text 任务,其中 X 分别是图像、音乐和语音。
为了模拟真实场景,所有评估均以零样本模式进行。这意味着 AnyGPT 在评估过程中不会对下游训练样本进行微调或预训练。这种具有挑战性的评估设置要求模型泛化到未知的测试分布。
评估结果表明,AnyGPT 作为一种通用的多模态语言模型,在各种多模态理解和生成任务上取得了令人称赞的性能。
图像
该研究评估了 AnyGPT 在图像描述任务上的图像理解能力,结果如表 2 所示。

文本到图像生成任务的结果如表 3 所示。
 语音
语音
该研究通过计算 LibriSpeech 数据集的测试子集上的词错误率 (WER) 来评估 AnyGPT 在自动语音识别 (ASR) 任务上的性能,并使用 Wav2vec 2.0 和 Whisper Large V2 作为基线,评估结果如表 5 所示。


音乐
该研究在 MusicCaps 基准上评估了 AnyGPT 在音乐理解和生成任务方面的表现,采用 CLAP_score 分数作为客观指标,衡量生成的音乐和文本描述之间的相似度,评估结果如表 6 所示。

感兴趣的读者可以阅读论文原文,了解更多研究内容。


















