在机器学习领域,概念漂移(concept drift)问题长期困扰着研究者,即数据分布随时间发生变化,使得模型难以持续有效。
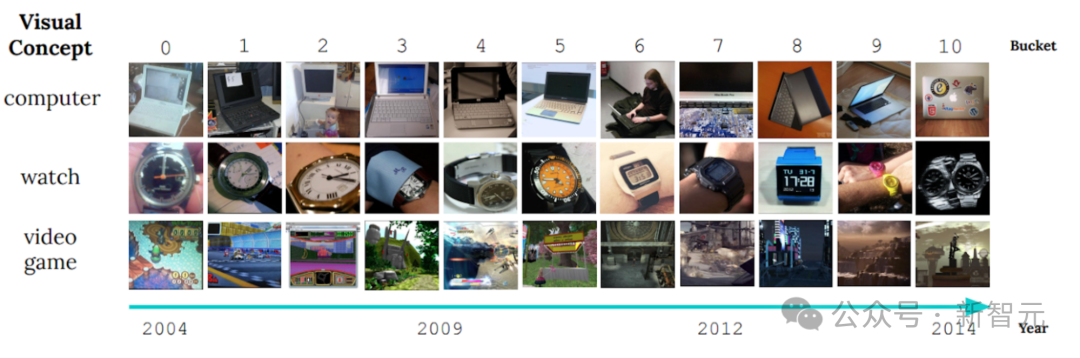
一个显著的例子是CLEAR非稳态学习基准的图像展示,它揭示了物体视觉特征在十年间发生的显著变化。
这种现象被称为「缓慢的概念漂移」,它对物体分类模型提出了严峻的挑战。当物体的外观或属性随着时间的推移而改变时,如何确保模型能够适应这种变化并持续准确地进行分类,成为了研究者关注的焦点。
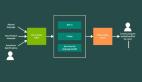
近日,针对这一挑战,Google AI的研究人员提出了一种优化驱动的方法MUSCATEL(Multi-Scale Temporal Learning) ,显著提升了模型在大型、动态数据集中的表现。该工作发表于AAAI2024。

论文地址:https://arxiv.org/abs/2212.05908
目前,针对概率漂移的主流方法是在线学习和持续学习(online and continue learning)。
这些方法的核心思想是,通过不断更新模型以适应最新数据,保持模型的时效性。然而,这种做法存在两个核心难题。
首先,它们往往只关注最新数据,导致过去数据中蕴含的有价值信息被忽略。其次,这些方法假设所有数据实例的贡献随时间均匀衰减,这与现实世界的实际情况不符。
MUSCATEL方法能有效解决这些问题,它训练实例的重要性分配分数,优化模型在未来实例中的表现。
为此,研究人员引入了一个辅助模型,结合实例及其年龄生成分数。辅助模型与主模型协同学习,解决了两个核心难题。
该方法在实际应用中表现优异,在一项涵盖3900万张照片、持续9年的大型真实数据集实验中,相较于其他稳态学习的基线方法,准确率提升了15%。
同时在两个非稳态学习数据集及持续学习环境中,也展现出优于SOTA方法的效果。
概念漂移对有监督学习的挑战
为了研究概念漂移对有监督学习的挑战,研究人员在照片分类任务中比较了离线训练(offline training)和持续训练(continue training)两种方法,使用约3,900万张10年间的社交媒体照片。
如下图所示,离线训练模型虽然初始性能高,但随时间推移准确性下降,因灾难遗忘(catastrophic forgetting)导致对早期数据理解减少。
相反,持续训练模型虽初始性能较低,但对旧数据依赖较低,测试期间退化更快。
这表明数据随时间演变,两模型的适用性降低。概念漂移对有监督学习构成挑战,需持续更新模型以适应数据变化。

MUSCATEL
MUSCATEL是一种创新的方法,旨在解决缓慢概念漂移这一难题。它通过巧妙结合离线学习与持续学习的优势,旨在减少模型在未来的性能衰减。
在庞大的训练数据面前,MUSCATEL展现了其独特的魅力。它不仅仅依赖传统的离线学习,更在此基础上审慎地调控和优化过去数据的影响,为模型未来的表现打下坚实基础。
为了进一步提升主模型在新数据上的性能,MUSCATEL引入了一个辅助模型。
根据下图中的优化目标,训练辅助模型根据每个数据点的内容和年龄为其分配权重。这一设计使得模型能够更好地适应未来数据的变化,保持持续的学习能力。

为了使辅助模型与主模型协同进化,MUSCATEL还采用了元学习(meta-learning)的策略。
这一策略的关键在于将样本实例与年龄的贡献进行有效分离,并通过结合多种固定衰变时间尺度来设定权重,如下图所示。

此外,MUSCATEL还学习将每个实例“分配”到最适合的时间尺度上,以实现更精确的学习。
实例权重评分
如下图所示,在CLEAR物体识别挑战中,学习的辅助模型成功调整了物体的权重:新外观的物体权重增加,旧外观的物体权重减少。

通过基于梯度的特征重要性评估,可以发现辅助模型聚焦于图像中的主体,而非背景或与实例年龄无关的特征,从而证明了其有效性。

大规模照片分类任务取得显著突破
在YFCC100M数据集上研究了大规模照片分类任务(PCAT),利用前五年的数据作为训练集,后五年的数据作为测试集。
相较于无加权基线以及其他鲁棒学习技术,MUSCATEL方法展现出了明显的优势。
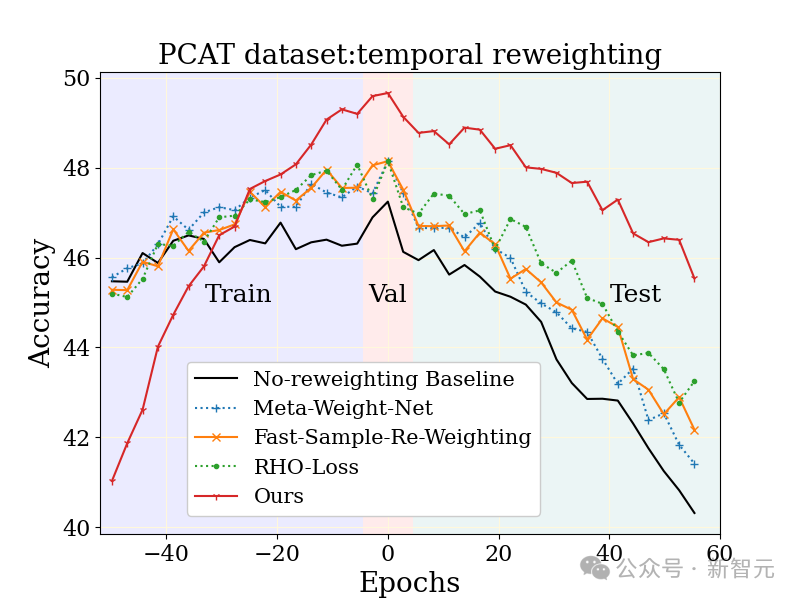
值得注意的是,MUSCATEL方法有意识地调整了对遥远过去数据的准确性,以换取测试期间性能的显著提升。这一策略不仅优化了模型对于未来数据的适应能力,同时还在测试期间表现出较低的退化程度。
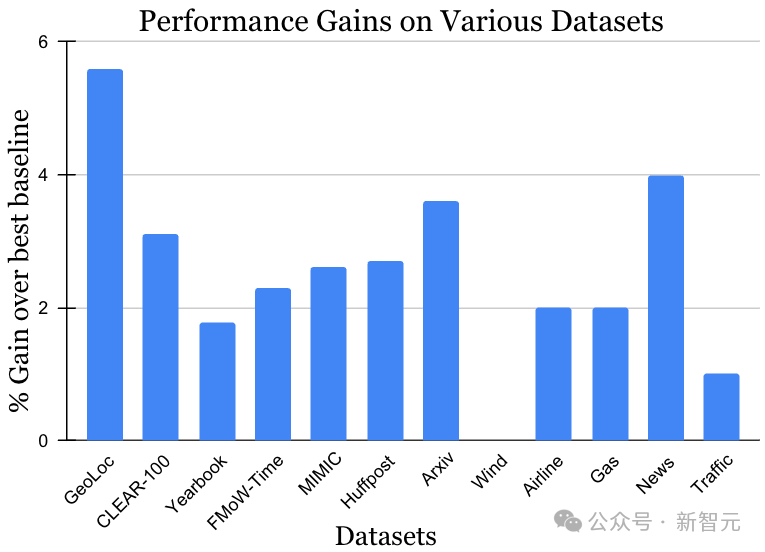
跨数据集验证广泛使用性
非稳态学习挑战的数据集涵盖了多种数据来源和模式,包括照片、卫星图像、社交媒体文本、医疗记录、传感器读数和表格数据,数据规模也从10k到3900万实例不等。值得注意的是,每个数据集之前的最优方法可能各有千秋。然而,如下图所示,在数据与方法均存在多样性的背景下,MUSCATEL方法均展现出了显著的增益效果。这一结果充分证明了MUSCATEL的广泛适用性。
拓展持续学习算法,应对大规模数据处理挑战
当面对堆积如山的大规模数据时,传统的离线学习方法可能会感到力不从心。
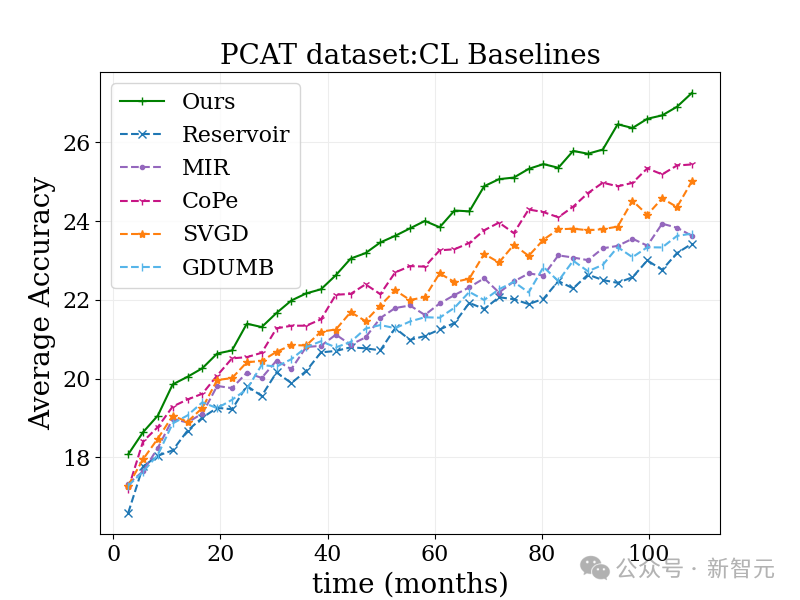
考虑到这个问题,研究团队巧妙地调整了一种受持续学习启发的方法,让它轻松适应大规模数据的处理。
这个方法很简单,就是在每一批数据上加上一个时间权重,然后顺序地更新模型。
虽然这样做还是有一些小限制,比如模型更新只能基于最新的数据,但效果却出奇地好!
在下图的照片分类的基准测试中,这个方法表现得比传统的持续学习算法和其他各种算法都要出色。
而且,由于它的思路与许多现有的方法都很搭,预计与其他方法结合后,效果会更加惊艳!
总的来说,研究团队成功将离线与持续学习相结合,破解了长期困扰业界的数据漂移问题。
这一创新策略不仅显著缓解了模型的「灾难遗忘」现象,还为大规模数据持续学习的未来发展开辟了新的道路,为整个机器学习领域注入了新的活力。