












最近,OpenAI 视频生成模型 Sora 的爆火,给基于 Transformer 的扩散模型重新带来了一波热度,比如 Sora 研发负责人之一 William Peebles 与纽约大学助理教授谢赛宁去年提出的 DiT(Diffusion Transformer)。
当然,随着视频生成这波 AI 趋势的继续演进,类似架构的模型会越来越多。就在昨天,开发出 SnapChat 图片分享软件的 Snap 公司、特伦托大学等机构联合发布了类似 Sora 的文本生成视频模型 Snap Video,这次他们使用到了可扩展的时空 Transformer。
相关的论文《Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis》已经放出。

论文地址:https://arxiv.org/pdf/2402.14797.pdf
项目地址:https://snap-research.github.io/snapvideo/#title-footer
如你我所见,统一图像生成架构(如带有公开可用图像预训练模型的 U-Nets)的可用性,使得它们成为构建大规模视频生成器的逻辑基础,并且主要的架构修改在于插入特定层来捕获时序依赖性。同样地,训练是在基于图像的扩散框架下进行的,其中可以将模型应用于视频和一组单独的图像,从而提升结果的多样性。
本文中,研究者认为这种方法不是最理想的,因而想要系统性地解决。首先图像和视频模态呈现出了由连续视频帧中相似内容决定的内在差异。以此类推,图像和视频压缩算法基于完全不同的方法。为此,研究者重写了 EDM(出自 2022 年论文 Elucidating the Design Space of Diffusion-Based Generative Models)框架,并重点关注高分辨率视频。
具体来讲,与以往将视频视为图像序列的工作不同,研究者通过将图像作为高帧率视频来执行联合视频 - 图像训练,从而避免纯图像训练中缺乏时间维度而导致的模态不匹配。其次,以往需要利用 U-Net 架构来充分处理每个视频帧,与纯文本到图像模型相比,这种做法增加了计算开销,对模型可扩展性造成了实际的限制。然而,可扩展性是获得高质量结果的关键因素。
此外,扩展基于 U-Net 的架构以自然地支持空间和时间维度需要进行体积注意力运算,又会产生令人望而却步的计算需求。如果无法做到,则会影响输出,导致生成的是动态图像或运动伪影,而不是具有连贯和多样化动作的视频。
按照研究者自己的压缩类比,他们提出利用重复帧,并引入可扩展的 transformer 架构来将空间和时间维度视为单个压缩的 1D 潜在向量。研究者利用这种高压缩的表示来联合执行时空计算,并对复杂运动进行建模。
本文的架构受到 FIT(出自 2023 年论文 Far-reaching interleaved transformers)的启发,并首次将它扩展到了数十亿参数。与 U-Net 相比,Snap Video 模型的训练速度快了 3.31 倍,推理速度快了 4.49 倍,同时实现了更高的生成质量。
我们先来看 Snap Video 的一些生成示例。
越野车和摩托车穿过广阔的沙漠,空气中弥漫着灰尘,追逐跳跃的沙丘、具有挑战性的地形以及挑战极限的参赛者的兴奋感。(Dust fills the air as off-road vehicles and motorcycles tear through a vast desert landscape. Capture the excitement of jumps over sand dunes, challenging terrain, and competitors pushing the limits of their machines.)

一张柯基犬在时代广场骑自行车的照片,它戴着太阳镜和沙滩帽。(A photo of a Corgi dog riding a bike in Times Square. It is wearing sunglasses and a beach hat.)

在陡峭的悬崖顶上,两名武士正在进行一场剑战,捕捉决斗的复杂编排,强调每一次冲突和招架,使用横扫镜头来展示令人惊叹的风景。(Atop dramatic cliffs, two warriors engage in a sword fight. Capture the intricate choreography of the duel, emphasizing every clash and parry. Use sweeping crane shots to showcase the breathtaking scenery.)

骑在狮子背上的牛仔熊猫,手持拍摄镜头。(a cowboy panda riding on the back of a lion, hand-held camera)

在浩瀚太空中,星际飞船展开了一场宇宙冲突,渲染航天器、爆炸和宇宙碎片的复杂细节,利用横扫镜头的移动来传达战斗的激烈程度和激烈时刻的特写。(In the vastness of space, starships engage in a cosmic clash. Render intricate details of the spacecraft, explosions, and cosmic debris. Utilize sweeping camera movements to convey the enormity of the battle and close-ups for intense moments.)

前往电影拍摄地,水獭担任电影导演,皱起眉头、举起爪子大喊「开机」,捕捉这一刻的紧张气氛,聚焦导演椅、剧本和忙碌的摄制组的 4K 细节,使用动态的摄像机角度来传达电影布景的活力。(Transport to a movie set where an otter serves as a film director. Capture the intensity of the moment with furrowed brows and raised paws shouting "Action!" Focus on the 4K details of the director's chair, script, and the bustling film crew. Use dynamic camera angles to convey the energy of the film set.)

研究者在广泛采用的 UCF101 和 MSR-VTT 数据集上对 Snap Video 进行评估,结果显示,该模型在各种基准上均实现了 SOTA 性能,尤其能生成高质量的运动。最有趣的是, 他们针对最近的开源和闭源方法展开大量用户研究,参与者表示,Snap Video 具有与 Runway Gen-2 相当的真实感,同时明显优于 Pika 和 Floor33。
此外,在评估文本对齐和运动质量时,参与者大多偏向 Snap Video。与 Gen-2 在 prompt - 视频对齐方面的对比时,Snap Video 在 81% 的情况下受到青睐(80% 不选择 Pika、81% 不选择 Floor33);在生成运动量最大的动态视频方面,96% 不选择 Gen2,89% 不选择 Pika、88% 不选择 Floor33;在生成最佳的运动质量方面,79% 不选择 Gen-2、 71% 不选择 Pika、79% 不选择 Floor33。
与 Runway Gen-2、Pika、Floor33 的比较结果一目了然。相同的 prompt:两只大象在海滩上玩耍,享用着美味的沙拉酱牛肉大餐。(Two elephants are playing on the beach and enjoying a delicious beef stroganoff meal.)

一名男子骑着摩托车穿越城市,感受肾上腺素激增的感觉(A man cruises through the city on a motorcycle, feeling the adrenaline rush)

论文提出了生成高分辨率视频的方法,即针对高维输入重写 EDM 扩散框架,并提出一种基于 FIT 的高效 transformer 架构,该架构可扩展至数十亿参数和数万输入 patch。
第 3.1 节介绍了 EDM 框架,第 3.2 节强调了将扩散框架应用于高维输入所面临的挑战,并提出了重新审视的基于 EDM 的扩散框架。第 3.3 节提出了一种缩小图像和视频联合训练模式之间差距的方法。最后,第 3.4 节介绍了本文的可扩展视频生成架构,第 3.5 节和第 3.6 节分别介绍了训练和推理过程。
我们重点看一下 3.3 节和 3.4 节的内容。
用于生成高分辨率视频的 EDM,如何实现图像 - 视频模态匹配
EDM 最初是作为图像生成框架提出的,其参数针对 64 × 64px 图像生成进行了优化。改变空间分辨率或引入帧间共享内容的视频,可使去噪网络以更高的信噪比(SNR)在原始分辨率下琐碎地恢复有噪声的帧,而原始框架的设计目的是在较低的噪声水平下看到这种情况。
与图像相比,有字幕的视频数据量有限,因此研究上广泛采用图像 - 视频联合训练的方法,通常对两种模态采用相同的扩散过程,但视频中 T 帧的存在需要采用与具有相同分辨率的图像不同的处理过程。
其中一种可能性是对两种模式采用不同的输入缩放因子。本文研究者认为这种解决方案并不可取,因为它增加了框架的复杂性,而且图像训练无法促进去噪模型学习时间推理,而时间推理是视频生成器的基本能力。
为了避免这些问题,同时使用统一的扩散过程,研究者将图像视为具有无限帧率的 T 帧视频,从而匹配图像和视频模态,并引入可变帧率训练程序,消除图像和视频模态之间的差距。
可扩展的视频生成器
在视频生成过程中,U-Net 通常使用时间注意力或卷积来建模时间维度。这种方法需要对 T 个视频帧中的每个帧进行一次完整的 UNet 前向传递,其成本之高令人望而却步(见图 3a)。这些因素对模型的可扩展性造成了实际限制(可扩展性是实现高生成质量的首要因素),同样也限制了时空联合建模的可能性。研究者认为,以可分离的方式处理空间和时间建模会导致运动伪影、时间不一致或生成动态图像,而不是具有生动动态的视频。视频帧包含空间和时间上的冗余内容,可以进行压缩。学习和运算压缩视频表示法并对空间和时间维度进行联合建模,是实现高质量视频生成所需的可扩展性和运动建模能力的必要步骤。
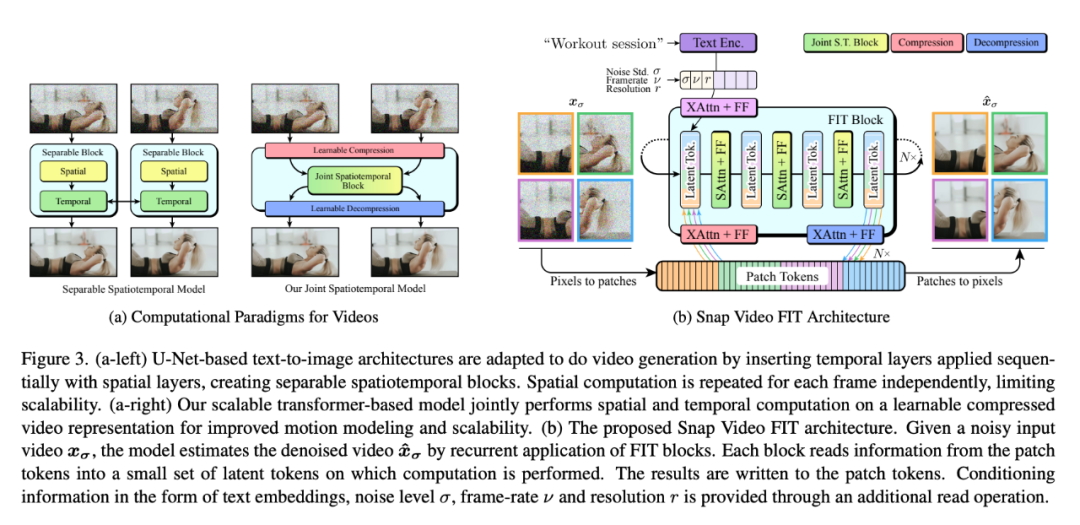
FIT 是一种基于 transformer 的高效架构,最近被提出用于高分辨率图像合成和视频生成。其主要思想如图 3 所示,即通过一组可学习的潜在 token 来学习输入的压缩表示,并将计算集中在这个可学习的潜在空间上,从而允许输入维度的增长而几乎不影响性能。
虽然这些架构前景广阔,但尚未扩展到最先进的基于 U-Net 的视频生成器的十亿参数规模,也未应用于高分辨率视频生成。要实现这些目标,需要考虑很多架构因素。
时间建模是高质量视频生成器的一个基本方面。FIT 通过考虑跨越空间和时间维度的 Tp×Hp×Wp 大小的三维 patch 来生成 patch token。研究者发现 Tp > 1 的值会限制时间建模的性能,因此只考虑跨空间维度的 patch。
与 patch 类似,FIT 也会将 patch token 分成跨越时间和空间维度的组,并逐组执行交叉注意力运算。每组的时间尺寸应配置为每组覆盖所有 T 个视频帧,以获得最佳的时间建模效果。此外,由于时间维度的存在,视频比图像包含更多的信息,因此增加了代表压缩空间大小的潜在 token 的数量,在压缩空间中进行联合时空计算。最后,FIT 利用局部层对同一组对应的 patch token 进行自关注运算。
研究者发现,对于大量的 patch token(最大分辨率为 147.456)来说,这种运算的计算成本很高,因此在每次交叉注意力「读取」或「写入」运算后,他们都会用一个前馈模块来替代。
本文的模型利用由一系列调节 token 表示的调节信息来控制生成过程。除了代表当前 σ 的标记外,为实现文本调节,还引入了 T5-11B 文本编码器,从输入文本中提取文本嵌入。为了支持训练数据中视频帧率的变化以及分辨率和宽高比的巨大差异,本文连接了代表当前输入帧率和原始分辨率的附加 token。
为了生成高分辨率的输出,研究者部署了一个模型级联,包含生成 36×64px 视频的第一阶段模型和生成 288 × 512px 视频的第二阶段上采样模型。
为了提高上采样质量,研究者在训练期间使用可变级别的噪声来破坏第二阶段的低分辨率输入,并在推理期间将一定级别的噪声应用于超参数搜索获得的第一阶段输出。
评估
消融实验
在消融实验中,研究者选择了两个不同容量的 U-Net 变体和一个较小的 FIT 变体,以评估这两种架构的可扩展性。
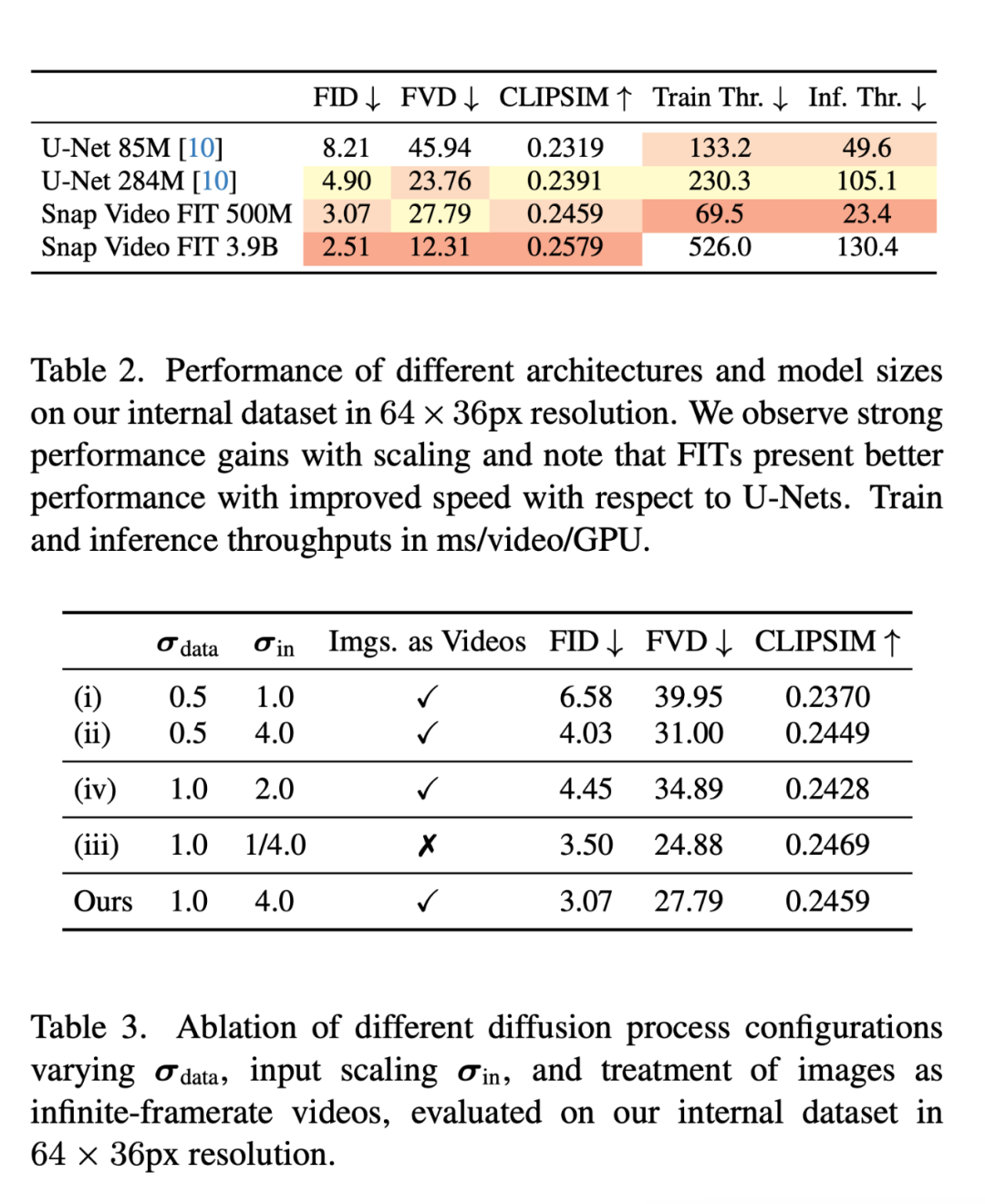
定量评估
表 4 和表 5 分别展示了 Snap Video 和 UCF101 、 MSR-VTT 的对比:

定性评估
定性评估如图 4 所示,本文方法生成的样本更能呈现出生动、高质量的动态效果,避免了基线中出现的闪烁假象:





























