














在 Java 并发编程中,有 3 个最常用的关键字:synchronized、ReentrantLock 和 volatile。
虽然 volatile 并不像其他两个关键字一样,能保证线程安全,但 volatile 也是并发编程中最常见的关键字之一。例如,单例模式、CopyOnWriteArrayList 和 ConcurrentHashMap 中都离不开 volatile。
那么,问题来了,我们知道 synchronized 底层是通过监视器 Monitor 实现的,ReentrantLock 底层是通过 AQS 的 CAS 实现的,那 volatile 的底层是如何实现的?
1.volatile 作用
在了解 volatile 的底层实现之前,我们需要先了解 volatile 的作用,因为 volatile 的底层实现和它的作用息息相关。
volatile 作用有两个:保证内存可见性和有序性(禁止指令重排序)。
(1)内存可见性
说到内存可见性问题就不得不提 Java 内存模型,Java 内存模型(Java Memory Model)简称为 JMM,主要是用来屏蔽不同硬件和操作系统的内存访问差异的,因为在不同的硬件和不同的操作系统下,内存的访问是有一定的差异得,这种差异会导致相同的代码在不同的硬件和不同的操作系统下有着不一样的行为,而 Java 内存模型就是解决这个差异,统一相同代码在不同硬件和不同操作系统下的差异的。
Java 内存模型规定:所有的变量(实例变量和静态变量)都必须存储在主内存中,每个线程也会有自己的工作内存,线程的工作内存保存了该线程用到的变量和主内存的副本拷贝,线程对变量的操作都在工作内存中进行。线程不能直接读写主内存中的变量,如下图所示:
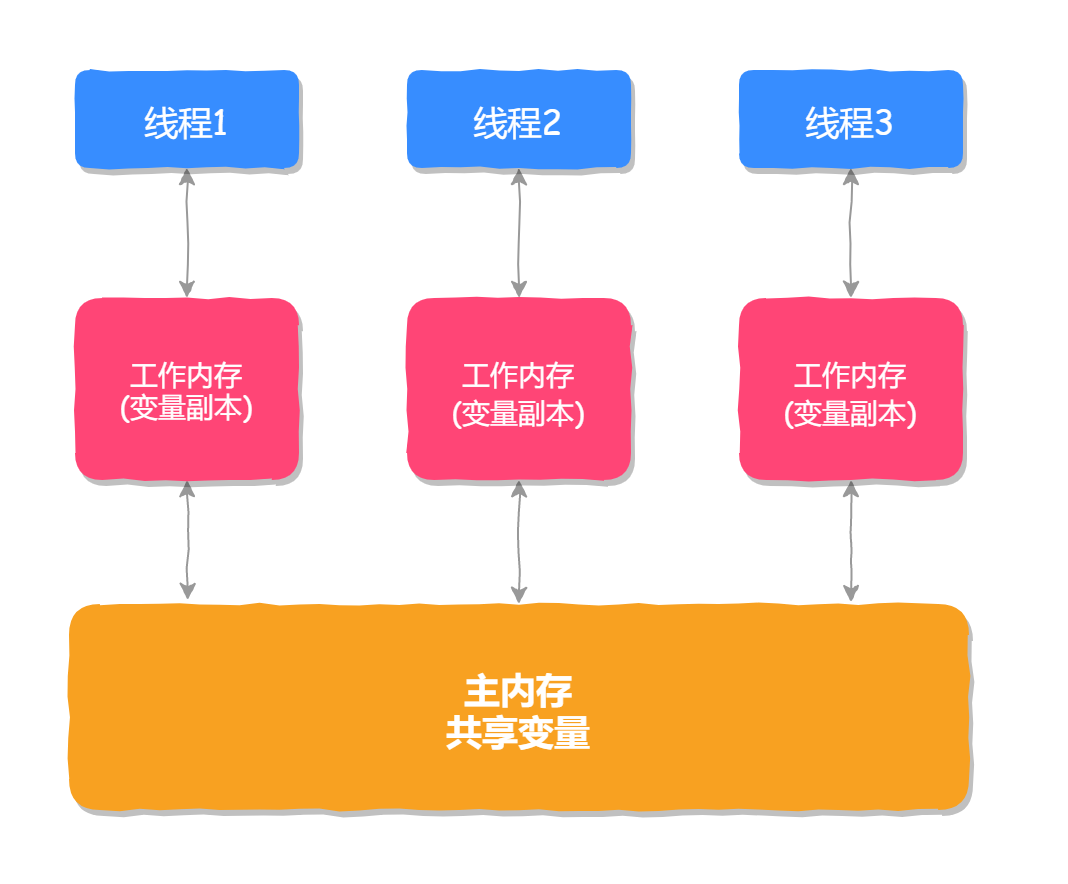
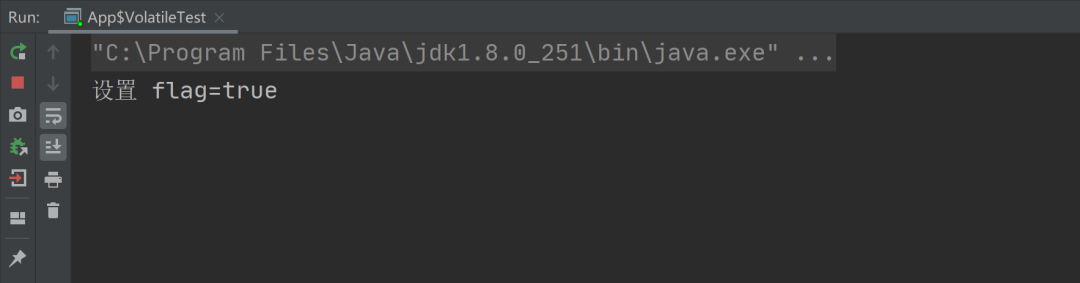
然而,Java 内存模型会带来一个新的问题,那就是内存可见性问题,也就是当某个线程修改了主内存中共享变量的值之后,其他线程不能感知到此值被修改了,它会一直使用自己工作内存中的“旧值”,这样程序的执行结果就不符合我们的预期了,这就是内存可见性问题,我们用以下代码来演示一下这个问题:
以上代码我们预期的结果是,在线程 1 执行了 1s 之后,线程 2 将 flag 变量修改为 true,之后线程 1 终止执行,然而,因为线程 1 感知不到 flag 变量发生了修改,也就是内存可见性问题,所以会导致线程 1 会永远的执行下去,最终我们看到的结果是这样的:
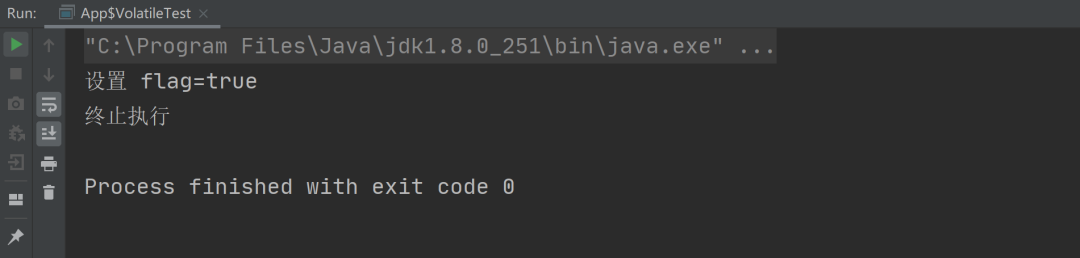
如何解决以上问题呢?只需要给变量 flag 加上 volatile 修饰即可,具体的实现代码如下:
以上程序的执行结果如下图所示:
(2)有序性
有序性也叫做禁止指令重排序。
指令重排序是指编译器或 CPU 为了优化程序的执行性能,而对指令进行重新排序的一种手段。
指令重排序的实现初衷是好的,但是在多线程执行中,如果执行了指令重排序可能会导致程序执行出错。指令重排序最典型的一个问题就发生在单例模式中,比如以下问题代码:
以上问题发生在代码 ② 这一行“instance = new Singleton();”,这行代码看似只是一个创建对象的过程,然而它的实际执行却分为以下 3 步:
- 创建内存空间。
- 在内存空间中初始化对象 Singleton。
- 将内存地址赋值给 instance 对象(执行了此步骤,instance 就不等于 null 了)。
如果此变量不加 volatile,那么线程 1 在执行到上述代码的第 ② 处时就可能会执行指令重排序,将原本是 1、2、3 的执行顺序,重排为 1、3、2。但是特殊情况下,线程 1 在执行完第 3 步之后,如果来了线程 2 执行到上述代码的第 ① 处,判断 instance 对象已经不为 null,但此时线程 1 还未将对象实例化完,那么线程 2 将会得到一个被实例化“一半”的对象,从而导致程序执行出错,这就是为什么要给私有变量添加 volatile 的原因了。
要使以上单例模式变为线程安全的程序,需要给 instance 变量添加 volatile 修饰,它的最终实现代码如下:
2.volatile 实现原理
volatile 实现原理和它的作用有关,我们首先先来看它的内存可见性。
(1)内存可见性实现原理
volatile 内存可见性主要通过 lock 前缀指令实现的,它会锁定当前内存区域的缓存(缓存行),并且立即将当前缓存行数据写入主内存(耗时非常短),回写主内存的时候会通过 MESI 协议使其他线程缓存了该变量的地址失效,从而导致其他线程需要重新去主内存中重新读取数据到其工作线程中。
什么 MESI 协议?
MESI 协议,全称为 Modified, Exclusive, Shared, Invalid,是一种高速缓存一致性协议。它是为了解决多处理器(CPU)在并发环境下,多个 CPU 缓存不一致问题而提出的。MESI 协议定义了高速缓存中数据的四种状态:
- Modified(M):表示缓存行已经被修改,但还没有被写回主存储器。在这种状态下,只有一个 CPU 能独占这个修改状态。
- Exclusive(E):表示缓存行与主存储器相同,并且是主存储器的唯一拷贝。这种状态下,只有一个 CPU 能独占这个状态。
- Shared(S):表示此高速缓存行可能存储在计算机的其他高速缓存中,并且与主存储器匹配。在这种状态下,各个 CPU 可以并发的对这个数据进行读取,但都不能进行写操作。
- Invalid(I):表示此缓存行无效或已过期,不能使用。
MESI 协议的主要用途是确保在多个 CPU 共享内存时,各个 CPU 的缓存数据能够保持一致性。当某个 CPU 对共享数据进行修改时,它会将这个数据的状态从 S(共享)或 E(独占)状态转变为 M(修改)状态,并等待适当的时机将这个修改写回主存储器。同时,它会向其他 CPU 广播一个“无效消息”,使得其他 CPU 将自己缓存中对应的数据状态转变为I(无效)状态,从而在下次访问这个数据时能够从主存储器或其他 CPU 的缓存中重新获取正确的数据。
这种协议可以确保在多处理器环境中,各个 CPU 的缓存数据能够正确、一致地反映主存储器中的数据状态,从而避免由于缓存不一致导致的数据错误或程序异常。
(2)有序性实现原理
volatile 的有序性是通过插入内存屏障(Memory Barrier),在内存屏障前后禁止重排序优化,以此实现有序性的。
什么是内存屏障?
内存屏障(Memory Barrier 或 Memory Fence)是一种硬件级别的同步操作,它强制处理器按照特定顺序执行内存访问操作,确保内存操作的顺序性,阻止编译器和 CPU 对内存操作进行不必要的重排序。内存屏障可以确保跨越屏障的读写操作不会交叉进行,以此维持程序的内存一致性模型。
在 Java 内存模型(JMM)中,volatile 关键字用于修饰变量时,能够保证该变量的可见性和有序性。关于有序性,volatile 通过内存屏障的插入来实现:
- 写内存屏障(Store Barrier / Write Barrier):当线程写入 volatile 变量时,JMM 会在写操作前插入 StoreStore 屏障,确保在这次写操作之前的所有普通写操作都已完成。接着在写操作后插入 StoreLoad 屏障,强制所有后来的读写操作都在此次写操作完成之后执行,这就确保了其他线程能立即看到 volatile 变量的最新值。
- 读内存屏障(Load Barrier / Read Barrier):当线程读取 volatile 变量时,JMM 会在读操作前插入 LoadLoad 屏障,确保在此次读操作之前的所有读操作都已完成。而在读操作后插入 LoadStore 屏障,防止在此次读操作之后的写操作被重排序到读操作之前,这样就确保了对 volatile 变量的读取总是能看到之前对同一变量或其他相关变量的写入结果。
通过这种方式,volatile 关键字有效地实现了内存操作的顺序性,从而保证了多线程环境下对 volatile 变量的操作遵循 happens-before 原则,确保了并发编程的正确性。
(3)简单回答
因为内存屏障的作用既能保证内存可见性,同时又能禁止指令重排序。因此你也可以笼统的回答 volatile 是通过内存屏障实现的。但是,回答的越细,面试的成绩越高,面试的通过率也就越高。




























