













本文经自动驾驶之心公众号授权转载,转载请联系出处。
写在前面&笔者的个人理解
在过去的二十年里,SLAM领域的研究经历了重大的发展,突出了其在实现未知环境的自主探索方面的关键作用。这种演变从手工制作的方法到深度学习时代,再到最近专注于神经辐射场(NeRFs)和3D高斯泼溅(3DGS)表示的发展。我们意识到越来越多的研究和缺乏对该主题的全面调查,本文旨在通过辐射场的最新进展,首次全面概述SLAM的进展。它揭示了背景、进化路径、固有优势和局限性,并作为突出动态进展和具体挑战的基本参考。

相关背景
现有SLAM综述回顾
SLAM有了显著的增长,诞生了各种各样的综合论文。在早期阶段,达兰特-怀特和贝利介绍了SLAM问题的概率性质,并强调了关键方法。Grisetti等人进一步深入研究了基于图的SLAM问题,强调了它在未知环境中导航的作用。在视觉SLAM领域,Yousif概述了定位和映射技术,结合了视觉里程计和SLAM的基本方法和进展。多机器人系统的出现使Saeedi和Clark回顾了最先进的方法,重点关注多机器人SLAM的挑战和解决方案。
在现有文献中,出现了两种主要的SLAM策略,即frame-to-frame和frame-to-model跟踪方法。通常,前一种策略用于实时系统,通常涉及通过闭环(LC)或全局束调整(BA)对估计的姿态进行进一步优化,而后一种策略从重建的3D模型中估计相机姿态,通常避免进一步优化,但导致对大场景的可扩展性较低。这些策略构成了我们即将深入研究的方法论的基础。
虽然现有的调查涵盖了传统的和基于深度学习的方法,但最近的文献缺乏对SLAM技术前沿的全面探索,这些前沿植根于辐射领域的最新进展。
图2展示了辐射场的三种表达形式

辐射场理论的演进
基于神经场的表面重建
尽管NeRF及其变体有可能捕捉场景的3D几何结构,但这些模型是在神经网络的权重中隐含定义的。通过3D网格获得场景的显式表示对于3D重建应用是可取的。从NeRF开始,实现粗略场景几何的基本方法是对MLP预测的密度进行阈值设置。更高级的解决方案探讨了三种主要表示形式。
占用情况。该表示通过用学习的离散函数o(x)∈{0,1}代替沿射线的α值αi,对自由空间和占用空间进行建模。具体而言,通过运行行进立方体算法来估计占有概率∈[0,1],并获得表面。
符号距离函数(SDF)。场景几何体的另一种方法是从任意点到最近曲面的符号距离,在对象内部产生负值,在对象外部产生正值。NeuS是第一个重新访问NeRF体积渲染引擎的人,用MLP预测SDF为f(r(t)),并用ρ(t)代替α,从SDF推导如下:
截断有符号距离函数(TSDF)。最后,使用MLP预测截断的SDF允许在渲染过程中消除任何SDF值离单个表面太远的贡献。像素颜色是作为沿射线采样的颜色的加权和获得的:
3D Gaussian Splatting
3DGS由Kerbl于2023年推出,是一种用于高效、高质量渲染3D场景的显式辐射场技术。与传统的显式体积表示(如体素网格)不同,它提供了一种连续而灵活的表示,用于根据可微分的3D高斯形状基元对3D场景进行建模。这些基元用于参数化辐射场,并可以进行渲染以生成新的视图。此外,与依赖于计算昂贵的体积射线采样的NeRF相比,3DGS通过基于瓦片的光栅化器实现实时渲染。这种概念上的差异在图3中突出显示。这种方法在不依赖神经组件的情况下提供了改进的视觉质量和更快的训练,同时也避免了在空白空间中进行计算。更具体地说,从具有已知相机姿势的多视图图像开始,3DGS学习一组3D高斯。这允许将单个高斯基元的空间影响紧凑地表示为:
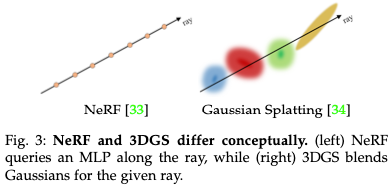
相反对于优化,该过程从SfM点云或随机值的参数初始化开始,然后使用L1和D-SSIM损失函数对GT和渲染视图进行随机梯度下降(SGD)。此外,周期性自适应致密化通过调整具有显著梯度的点和移除低不透明度点来处理欠重建和过重建,优化场景表示并减少渲染错误。
数据集
本节总结了最近SLAM方法中常用的数据集,涵盖了室内和室外环境中的各种属性,如传感器、GT准确性和其他关键因素。图4展示了来自不同数据集的定性示例,这些示例将在剩余部分中介绍。

TUM RGB-D数据集包括带有注释的相机轨迹的RGB-D序列,使用两个平台记录:手持和机器人,提供不同的运动范围。该数据集有39个序列,其中一些带有循环闭包。核心元素包括来自微软Kinect传感器的彩色和深度图像,以30赫兹和640×480分辨率拍摄。GT轨迹来源于一个运动捕捉系统,该系统有八台高速摄像机,工作频率为100赫兹。数据集的多功能性通过典型办公环境和工业大厅中的各种轨迹得到了证明,包括不同的平移和角速度。
ScanNet数据集提供了真实世界室内RGB-D采集的集合,其中包括707个独特空间中1513次扫描的250万张图像。特别地,它包括估计的校准参数、相机姿态、3D表面重建、纹理网格、对象级别的详细语义分割以及对齐的CAD模型。
开发过程包括创建一个用户友好的捕获管道,使用定制的RGB-D捕获设置,将结构传感器连接到iPad等手持设备上。随后的离线处理阶段导致了全面的3D场景重建,包括可用的6-DoF相机姿势和语义标签。请注意,ScanNet中的相机姿势源自BundleFusion系统,该系统可能不如TUM RGB-D等替代系统准确。
Replica数据集具有18个照片级真实感3D室内场景,具有密集网格、HDR纹理、语义数据和反射表面。它跨越不同的场景类别,包括88个语义类,并结合了单个空间的6次扫描,捕捉不同的家具布置和时间快照。重建涉及定制的RGB-D捕捉设备,该设备具有同步IMU、RGB、IR和广角灰度传感器,通过6个自由度(DoF)姿势准确融合原始深度数据。尽管原始数据是在现实世界中捕获的,但用于SLAM评估的数据集部分是由重建过程中产生的精确网格综合生成的。因此,合成序列缺乏真实世界的特性,如镜面反射高光、自动曝光、模糊等。
KITTI数据集是评估双目、光流、视觉里程计/SLAM算法等的流行基准。该数据集来自一辆配备了双目摄像头、Velodyne LiDAR、GPS和惯性传感器的汽车,包含来自61个代表自动驾驶场景的场景的42000个立体对和LiDAR点云。KITTI里程计数据集包含22个激光雷达扫描序列,有助于评估使用激光雷达数据的里程计方法。
Newer College数据集包括在牛津新学院周围2.2公里步行过程中采集的传感器数据。它包括来自立体惯性相机、带惯性测量的多波束3D激光雷达和三脚架安装的勘测级激光雷达扫描仪的信息,生成了一张包含约2.9亿个点的详细3D地图。该数据集为每次激光雷达扫描提供了6 DoFGT姿态,精确到约3厘米。该数据集涵盖了各种环境,包括建筑空间、开放区域和植被区。
其他数据集
此外,在最近的SLAM研究中,我们提请注意利用率较低的替代数据集。
ETH3D-SLAM数据集包括来自定制相机设备的视频,适用于评估视觉惯性单目、双目和RGB-D SLAM。它具有56个训练数据集、35个测试数据集和5个使用GTSfM技术独立捕获的训练序列。
EuRoC MAV数据集为微型飞行器提供同步立体图像、IMU和准确的GT。它支持在各种条件下进行视觉惯性算法设计和评估,包括具有毫米精度GT的工业环境和用于3D环境重建的房间。
为重新定位性能评估而创建的7场景数据集使用Kinect以640×480的分辨率进行记录。GT姿势是通过KinectFusion获得的。来自不同用户的序列被分为两组——一组用于模拟关键帧采集,另一组用于误差计算。该数据集带来了诸如镜面反射、运动模糊、照明条件、平坦表面和传感器噪声等挑战。
ScanNet++数据集包括460个高分辨率3D室内场景重建、密集语义注释、单反图像和iPhone RGB-D序列。使用亚毫米分辨率的高端激光扫描仪拍摄,每个场景都包括1000多个语义类的注释,解决标签歧义,并为3D语义场景理解和新颖视图合成引入新的基准。
SLAM
本节介绍利用辐射场表示的最新进展的最新SLAM系统。这些论文以基于方法的分类法进行组织,按其方法进行分类,为读者提供清晰有序的展示。本节首先对RGB-D、RGB和激光雷达方法进行基本分类,为特定子类别的发展奠定基础。每个类别都按发表日期列出了在会议/期刊上正式发表的论文,然后是arXiv按其初始预印本日期排列的预印本。
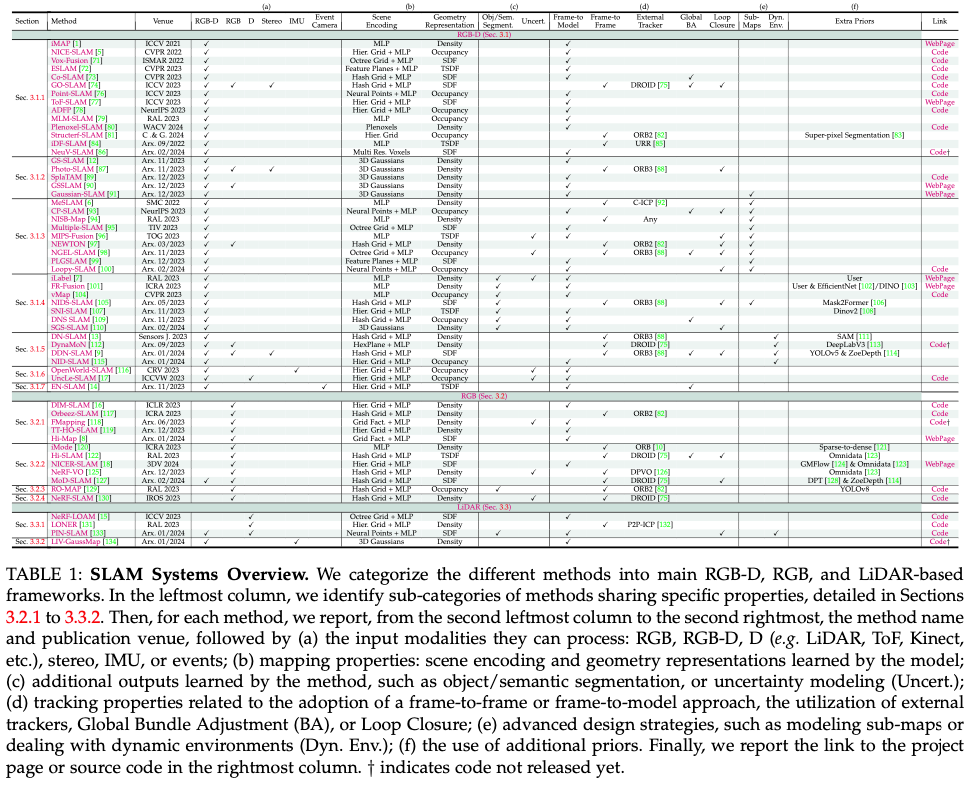
为了全面了解,表1提供了调查方法的详细概述。此表提供了深入的摘要,突出显示了每种方法的关键功能,并包括对项目页面或源代码的引用(只要可用)。有关更多细节或方法细节,请参阅原始论文。
RGB-D SLAM
在这里,我们重点关注密集SLAM技术使用RGB-D相机,捕捉彩色图像和逐像素的深度信息的环境。这些技术分为不同的类别:NeRF风格的SLAM解决方案和基于3D高斯飞溅表示的替代方案。从这两种方法派生的专门解决方案包括用于大型场景的基于子映射的SLAM方法、处理语义的框架以及为动态场景量身定制的框架。在这种分类中,一些技术通过不确定性来评估可靠性,而另一些技术则探索集成其他传感器,如基于事件的相机。
NeRF-style RGB-D SLAM
隐式神经表示的最新进展已经实现了精确和密集的3D表面重建。这导致了源自NeRF或受其启发的新型SLAM系统,最初设计用于已知相机姿势的离线使用。在本节中,我们描述了这些密集神经VSLAM方法,分析了它们的主要特征,并对它们的优势和劣势进行了清晰的概述。
iMAP。这项工作标志着首次尝试利用SLAM的隐式神经表示。这一突破性的成就不仅突破了SLAM的界限,而且为该领域确立了新的方向。特别地,iMAP展示了MLP动态创建特定场景的隐式3D模型的潜力。
NICE-SLAM。与iMAP使用单个MLP作为场景表示不同,NICE-SLAM采用了集成多层次局部数据的分层策略。这种方法有效地解决了诸如过度平滑的重建和较大场景中的可扩展性限制等问题。
Vox Fusion。这项工作将传统的体积融合方法与神经隐式表示相结合。具体而言,它利用基于体素的神经隐式表面表示来编码和优化每个体素内的场景。虽然与NICE-SLAM有相似之处,但其独特之处在于采用了基于八叉树的结构来实现动态体素分配策略。
ESLAM。ESLAM的核心是实现了与传统体素网格不同的多尺度轴对齐特征平面。这种方法通过二次缩放优化内存使用,与基于体素的模型所表现出的三次增长形成对比。
其他工作如Co-SLAM、GO-SLAM、Point-SLAM、ToF-SLAM、ADFP、MLM-SLAM、Plenoxel-SLAM、Structerf-SLAM、iDF-SLAM、NeuV-SLAM可以参考具体论文。
3DGS-style RGB-D SLAM
在这里,我们概述了使用基于3D高斯飞溅的显式体积表示来开发SLAM解决方案的开创性框架。这些方法通常利用3DGS的优势,例如与其他现有场景表示相比,更快、更真实的渲染。它们还提供了通过添加更多高斯基元、完全利用每像素密集光度损失和直接参数梯度流来提高地图容量的灵活性,以促进快速优化。到目前为止,3DGS表示主要用于离线系统,该离线系统致力于从已知相机姿势合成新的视图。在下一节中,我们将介绍开创性的SLAM方法,这些方法能够同时优化场景几何结构和相机姿态。
GS-SLAM。GS-SLAM通过利用3D高斯作为表示,结合飞溅渲染技术,引入了一种范式转变。与依赖神经隐式表示的方法相比,GS-SLAM通过采用一种新方法,利用3D高斯以及不透明度和球面谐波来封装场景几何结构和外观,从而大大加速了地图优化和重新渲染,如图6所示。
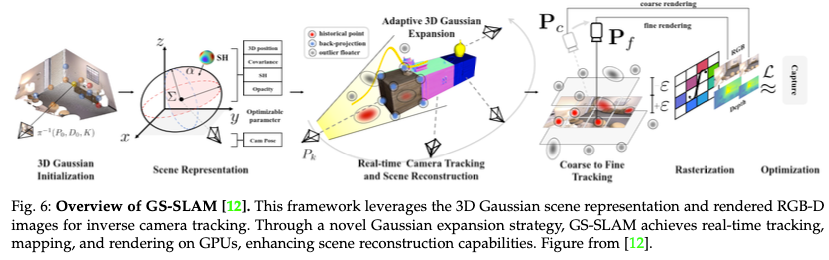
Photo-SLAM。这项工作将显式几何特征和隐式纹理表示集成在超基元地图中。该方法结合了ORB特征、旋转、缩放、密度和球面谐波系数,以优化相机姿态和贴图精度,同时最大限度地减少光度损失。
SplaTAM。这种方法将场景表示为简化的3D高斯图的集合,从而实现高质量的彩色和深度图像渲染。SLAM管道包括几个关键步骤:相机跟踪-高斯稠密化-地图更新。
GSSLAM。该系统采用3D高斯飞溅作为其唯一的表示,使用单个移动的RGB或RGB-D相机进行在线3D重建。该框架包括几个关键组件,如跟踪和相机姿态优化、高斯形状验证和正则化、建图和关键帧以及资源分配和修剪。
高斯SLAM。该框架采用了涉及地图构建和优化的管道,创建由单独的3D高斯点云表示的单独的子地图,以防止灾难性遗忘并保持计算效率。
Submaps-based SLAM
在这一类别中,我们专注于解决灾难性遗忘的挑战以及先前讨论的受密集辐射场启发的SLAM系统在大型环境中面临的适用性问题的方法。
MeSLAM。MeSLAM引入了一种新的SLAM算法,用于具有最小内存占用的大规模环境映射。这是通过将神经隐式映射表示与新的网络分布策略相结合来实现的。具体而言,通过使用分布式MLP网络,全局映射模块有助于将环境分割成不同的区域,并在重建过程中协调这些区域的缝合。
CP-SLAM。这项工作是一种协作的神经隐式SLAM方法,其特点是包含前端和后端模块的统一框架。其核心是利用与关键帧相关的基于神经点的3D场景表示。这允许在姿势优化过程中进行无缝调整,并增强协作建图功能。
NISB地图。NISB Map采用多个小型MLP网络,遵循iMAP的设计,以紧凑的空间块表示大规模环境。与具有深度先验的侧面稀疏光线采样一起,这实现了低内存使用率的可扩展室内映射。
多个SLAM。本文介绍了一种新的协作隐式SLAM框架来解决灾难性遗忘问题。通过使用多个SLAM代理来处理块中的场景,它最大限度地减少了轨迹和建图错误。
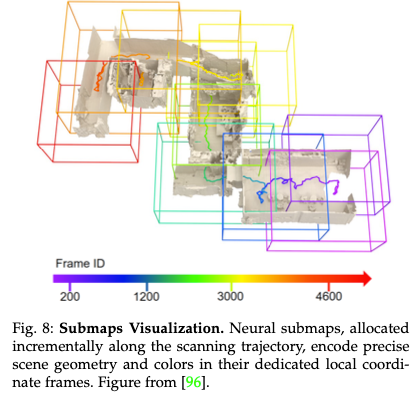
MIPS-Fusion。如图8所示,这项工作引入了一种用于在线密集RGB-D重建的分治映射方案,使用了一种无网格的纯神经方法,该方法具有增量分配和多个神经子映射的动态学习。
NEWTON。大多数神经SLAM系统使用具有单个神经场模型的以世界为中心的地图表示。然而,这种方法在捕捉动态和实时场景方面面临挑战,因为它依赖于准确和固定的先前场景信息。这在广泛的映射场景中可能特别有问题。
NGEL-SLAM。该系统利用两个模块,即跟踪和映射模块,将ORB-SLAM3的鲁棒跟踪能力与多个隐式神经映射提供的场景表示相结合。
PLGSLAM。本工作中提出的渐进式场景表示方法将整个场景划分为多个局部场景表示,允许对更大的室内场景进行可扩展性,并提高鲁棒性。
Loopy-SLAM。该系统利用子地图形式的神经点云进行局部建图和跟踪。该方法采用帧到模型跟踪和数据驱动的基于点的子地图生成方法,在场景探索过程中基于相机运动动态生长子地图。
Semantic RGB-D SLAM
作为SLAM系统运行,这些方法本身包括映射和跟踪过程,同时还包含语义信息以增强环境的真实性。这些框架针对对象识别或语义分割等任务量身定制,为场景分析提供了一种整体方法——识别和分类对象和/或有效地将图像区域分类为特定的语义类(如桌子、椅子等)。
iLabel。该框架是一个用于交互理解和分割3D场景的新颖系统。它使用神经场表示将三维坐标映射到颜色、体积密度和语义值。
FR-Fusion。该方法将神经特征融合系统无缝集成到iMAP框架中。通过结合2D图像特征提取器(基于EfficientNet或DINO)并使用潜在体积绘制技术增强iMAP,该系统可以有效地融合高维特征图,同时降低计算和内存需求。
其他算法如vMap、NIDS-SLAM、SNI-SLAM、DNS SLAM、SGS-SLAM可以参考具体论文。
SLAM in Dynamic Environments
到目前为止,大多数SLAM方法都是基于以刚性、不移动物体为特征的静态环境的基本假设。虽然这些技术在静态场景中表现良好,但它们在动态环境中的性能面临重大挑战,限制了它们在现实世界场景中的适用性。因此,在本节中,我们概述了专门为应对动态环境中精确映射和定位估计的挑战而设计的方法。
DN-SLAM。这项工作集成了各种组件,以解决动态环境中准确位置估计和地图一致性方面的挑战。DN-SLAM利用ORB特征进行对象跟踪,并采用语义分割、光流和分段任意模型(SAM),有效地识别和隔离场景中的动态对象,同时保留静态区域,增强SLAM性能。具体而言,该方法包括利用语义分割进行对象识别,通过SAM细化动态对象分割,提取静态特征,以及使用NeRF生成密集地图。
DynaMoN。该框架建立在DROID-SLAM的基础上,通过运动和语义分割对其进行了增强。该方法将这些元素集成到密集BA过程中,利用运动和分割掩码对优化过程进行加权,并忽略潜在的动态像素。通过预先训练的DeepLabV3网络,语义分割有助于细化已知对象类的掩码,并结合了基于运动的过滤来处理未知的动态元素。
其他算法如DDN-SLAM、NID-SLAM可以参考具体论文。
不确定性估计
分析输入数据中的不确定性,尤其是深度传感器噪声,对于鲁棒系统处理至关重要。这包括过滤不可靠的传感器测量值或将深度不确定性纳入优化过程等任务。总体目标是防止SLAM过程中可能严重影响系统准确性的不准确。同时,承认神经模型重建中的内在不确定性为评估系统可靠性增加了一个关键层,尤其是在具有挑战性的场景中。本节标志着神经SLAM不确定性探索的开始,强调将认知(基于知识)和预测(基于环境噪声)不确定性信息作为提高SLAM系统整体性能的重要组成部分。
OpenWorld-SLAM。这项工作改进了NICE-SLAM。解决其非实时执行、有限的轨迹估计以及由于依赖预定义网格而适应新场景的挑战。为了增强在开放世界场景中的适用性,这项工作引入了新的改进,包括从RGB-D图像中集成深度不确定性以进行局部精度细化,来自惯性测量单元(IMU)的运动信息利用以及用于不同环境处理的有限前景网格和背景球面网格的NeRF的划分。这些增强提高了跟踪精度和地图表示,同时保持了基于NeRF的SLAM优势。这项工作强调了对支持基于NeRF的SLAM的专业数据集的需求,特别是那些提供户外网格模型、运动数据和特征良好的传感器的数据集。
UncLe-SLAM。UncLe-SLAM在飞行中联合学习场景几何和任意深度的不确定性。这是通过采用与输入深度传感器相关联的拉普拉斯误差分布来实现的。与缺乏深度不确定性建模集成的现有方法不同,UncLeSLAM采用了一种学习范式,根据不同图像区域的估计置信度,自适应地为其分配权重,而无需地面实况深度或3D。
Event-based SLAM
虽然辐射场启发的VSLAM方法在精确的密集重建中具有优势,但涉及运动模糊和照明变化的实际场景带来了重大挑战,影响了映射和跟踪过程的稳健性。在本节中,我们将探讨一类系统,这些系统利用事件摄像机捕获的数据来利用其动态范围和时间分辨率。由给定像素的亮度对数变化触发的异步事件生成机制在低延迟和高时间分辨率方面显示出潜在的优势。这有可能提高神经VSLAM在极端环境中的鲁棒性、效率和准确性。尽管基于事件相机的SLAM系统仍处于研究的早期阶段,但我们相信,正在进行的研究有望克服传统基于RGB的方法的局限性。
EN-SLAM。该框架通过隐式神经范式将事件数据与RGB-D无缝集成,引入了一种新的范式转变。它旨在克服现有SLAM方法在以运动模糊和照明变化等问题为特征的非理想环境中操作时遇到的挑战。
RGB-based SLAM
本节探讨RGB密集SLAM方法,该方法仅依赖于彩色图像的视觉提示,从而消除了对深度传感器的需求,这些传感器通常是光敏的、有噪声的,在大多数情况下仅适用于室内。因此,使用单目或双目相机的仅RGB SLAM在RGB-D相机不切实际或成本高昂的情况下越来越受到关注,使RGB相机成为适用于更广泛的室内和室外环境的更可行的解决方案。然而,这些方法经常面临挑战,特别是在单目设置中,因为它们缺乏几何先验,导致深度模糊问题。因此,由于较少的约束优化,它们往往表现出较慢的优化收敛。
NeRF-style RGB SLAM
DIM-SLAM。本文介绍了第一个使用神经隐式映射表示的RGB SLAM系统。与NICE-SLAM类似,它结合了可学习的多分辨率体积编码和用于深度和颜色预测的MLP解码器。该系统动态学习场景特征和解码器。此外,DIM-SLAM通过跨尺度融合特征,在一步中优化占用率,提高了优化速度。值得注意的是,它引入了受多视图立体启发的光度扭曲损失,通过解决与视图相关的强度变化,加强了合成图像和观测图像之间的对齐,以提高准确性。与其他RGB-D方法类似,DIM-SLAM利用并行跟踪和映射线程来同时优化相机姿势和隐含场景表示。
其他算法Orbeez-SLAM、FMapping、TT-HO-SLAM、Hi-Map可以参考具体论文。
辅助监督
在本节中,我们探讨了基于RGB的SLAM方法,该方法使用外部框架将正则化信息集成到优化过程中,称为辅助监督。这些框架包括各种技术,例如从从单视图或多视图图像获得的深度估计导出的监督、表面法线估计、光流等等。外部信号的结合对于消除优化过程的歧义至关重要,并且有助于显著提高仅使用RGB图像作为输入的SLAM系统的性能。
iMODE。该系统通过由三个核心进程组成的多线程体系结构运行。首先,定位过程利用ORB-SLAM2稀疏SLAM系统在CPU上进行实时相机姿态估计,为后续映射选择关键帧。其次,受iMAP的启发,半密集映射过程通过监督深度渲染几何体的实时训练来提高重建精度。
其他算法Hi-SLAM、NICER-SLAM、NeRF-VO、MoD-SLAM可以参考具体论文。
Semantic RGB SLAM
RO-MAP。RO-MAP是一种实时多目标建图系统,无需深度先验,利用神经辐射场进行目标表示。这种方法将轻量级的以对象为中心的SLAM与NeRF模型相结合,用于从单目RGB输入中同时定位和重建对象。该系统有效地为每个对象训练单独的NeRF模型,展示了语义对象建图和形状重建的实时性能。主要贡献包括开发了第一个3D先验免费单目多目标映射管道,一个为目标量身定制的高效损失函数,以及一个高性能CUDA实现。
不确定性估计
NeRF SLAM。通过采用DROID-SLAM作为跟踪模块和Instant NGP作为分层体积神经辐射场图的实时实现,该方法在给定RGB图像作为输入的情况下成功地实现了实时操作效率。此外,结合深度不确定性估计解决了深度图中的固有噪声,通过对神经辐射场的深度损失监督(权重由深度的边际协方差确定)改善了结果。具体来说,管道涉及两个实时同步的线程:跟踪和建图。跟踪线程最大限度地减少了滑动关键帧窗口的BA重新投影错误。映射线程在没有滑动窗口的情况下优化跟踪线程中的所有关键帧。只有当跟踪线程创建新的关键帧,共享关键帧数据、姿势、深度估计和协变量时,才会发生通信。
LiDAR-Based SLAM
虽然到目前为止讨论的VSLAM系统在RGB和密集深度数据都可用的较小室内场景中成功运行,但它们的局限性在RGB-D相机不切实际的大型室外环境中变得明显。激光雷达传感器在长距离和各种户外条件下提供稀疏而准确的深度信息,在确保这些环境中的稳健映射和定位方面发挥着关键作用。然而,激光雷达数据的稀疏性和RGB信息的缺乏对先前概述的密集SLAM方法在户外环境中的应用提出了挑战。我们现在的重点是利用3D增量激光雷达数据的精度来改善户外场景中的自主导航的新方法,同时利用基于辐射场的场景表示,即使在传感器覆盖范围稀疏的区域中,也有可能实现密集、平滑的环境地图重建。
NeRF-style LiDAR-based SLAM
NeRF-LOAM。NeRF LOAM引入了第一种神经隐式方法来联合确定传感器的位置和方向,同时使用激光雷达数据构建大规模环境的综合3D表示。该框架包括三个相互连接的模块:神经里程计、神经建图和网格重建。神经里程计模块通过固定的隐式网络最小化SDF误差,为每次进入的激光雷达扫描估计6-DoF姿态。随后通过反向投影对姿态进行优化。并行地,神经映射模块在基于八叉树的架构中使用动态体素嵌入,熟练地捕捉局部几何。这种动态分配策略确保了计算资源的有效利用,避免了预分配嵌入或时间密集型哈希表搜索的复杂性。该方法使用动态体素嵌入查找表,提高了效率并消除了计算瓶颈。关键扫描细化策略提高了重建质量,并解决了增量映射过程中的灾难性遗忘问题,从而在最后一步中生成详细的3D网格表示。
其他算法LONER、PIN-SLAM可以参考具体论文。
3DGS-style LiDAR-based SLAM
LIV-GaussMap。所提出的激光雷达惯性视觉(LIV)融合辐射场映射系统将硬件同步激光雷达惯性传感器与相机集成,以实现精确的数据对齐。该方法从激光雷达惯性里程计开始,利用尺寸自适应体素来表示平面表面。激光雷达点云被分割成体素,并计算初始椭圆飞溅估计的协方差矩阵。该系统是通过使用视觉衍生的光度梯度优化球面谐波系数和激光雷达高斯结构来改进的,提高了映射精度和视觉真实性。高斯的初始化涉及大小自适应体素分割,并基于指定参数进行进一步细分。3D高斯图的自适应控制通过结构细化和光度梯度优化来解决重建不足和过密场景。该系统使用光栅化和阿尔法混合实现实时渲染。
实验及分析
在本节中,我们比较了数据集之间的方法,重点是跟踪和3D重建。此外,我们还探索了新颖的视图合成,并分析了运行时和内存使用方面的性能。在随后的每个表中,我们使用粗体强调子类别中的最佳结果,并用紫色突出显示绝对最佳结果。在我们的分析中,我们使用通用评估协议组织了论文中的定量数据,并对结果进行了交叉验证。我们的首要任务是纳入具有一致基准的论文,确保为多个来源的比较提供可靠的基础。尽管这种方法并非详尽无遗,但它保证了在我们的表格中包含具有可验证结果和共享评估框架的方法。为了进行性能分析,我们使用了具有可用代码的方法来报告通用硬件平台(单个NVIDIA 3090 GPU)上的运行时和内存需求。关于每种方法的具体实施细节,鼓励读者参考原始论文。
Visual SLAM评测
表2提供了对TUM RGB-D数据集的三个场景的相机跟踪结果的全面分析,这些场景以具有挑战性的条件为标志,例如稀疏的深度传感器信息和RGB图像中的高运动模糊。关键基准包括Kintinous、BAD-SLAM和ORB-SLAM2等已建立的方法,这些方法表示传统的手工制作的基线。

表3给出了对ScanNet数据集的六个场景的相机跟踪方法的评估。
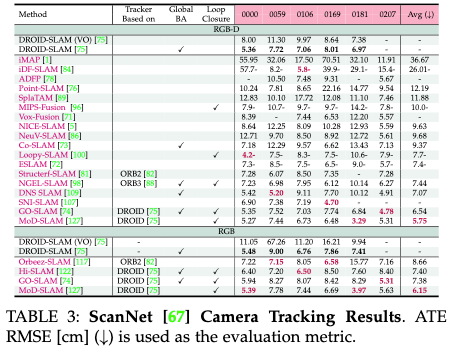
表4评估了Replica中八个场景的相机跟踪,与ScanNet和TUM RGB-D等具有挑战性的同行相比,使用了更高质量的图像。评估包括报告每个场景的ATE RMSE结果以及平均结果。
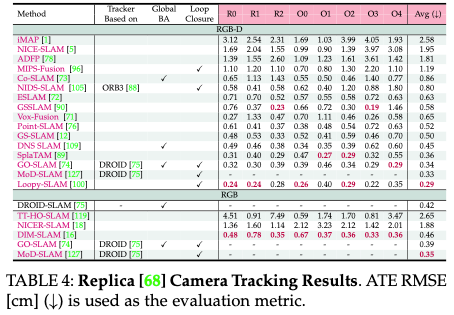
在表5中,我们提供了建图结果,突出了Replica数据集在3D重建和2D深度估计方面的性能。
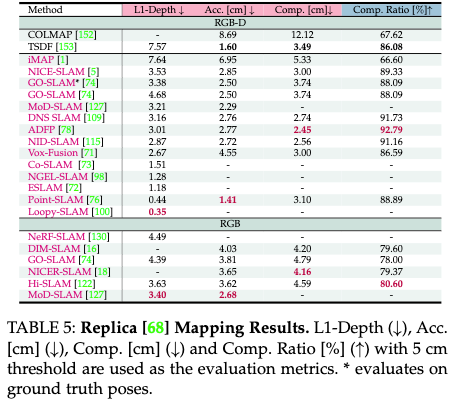
在表6中,我们显示了Replica的训练输入视图上的渲染质量,遵循Point SLAM和NICE-SLAM的标准评估方法。
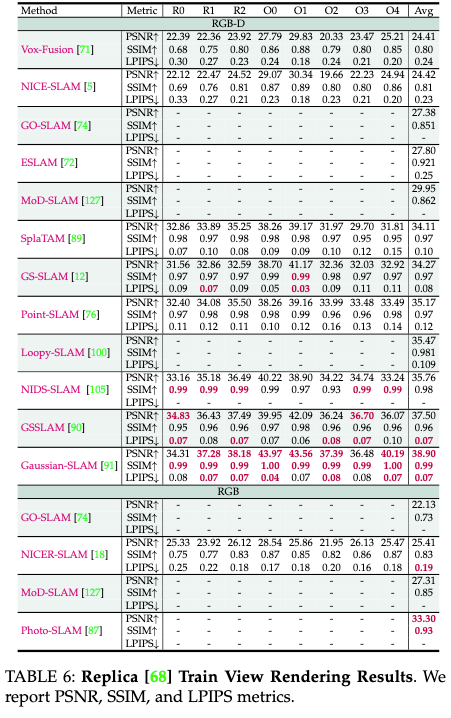
LiDAR SLAM/Odometry评测
表7显示了对KITTI数据集上的激光雷达SLAM策略的评估,详细说明了顶部的里程计准确性和底部的SLAM性能指标。
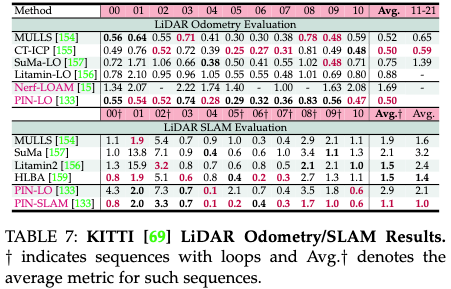
表8报告了根据ATE RMSE测量的Newer College数据集的跟踪精度。
 图片
图片
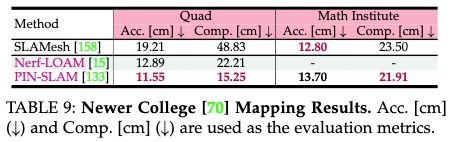
表9收集了关于New College数据集上的3D重建质量的结果。
性能分析
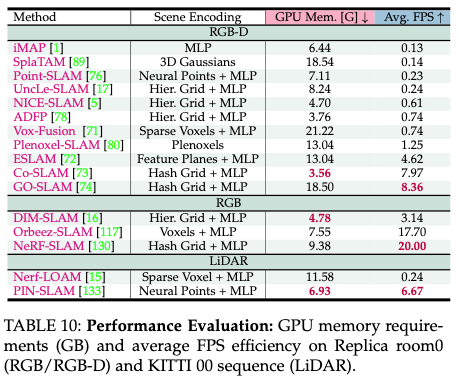
我们通过考虑迄今为止综述的SLAM系统的效率来结束实验研究。为此,我们使用公开的源代码运行方法,并测量1)GPU内存需求(以GB为单位的峰值内存使用量)和2)在单个NVIDIA RTX 3090板上实现的平均FPS(计算为处理单个序列所需的总时间,除以其中的帧总数)。表10收集了我们在Replica上运行的RGB-D和RGB系统的基准测试结果,按平均FPS的升序排序。最重要的是,我们考虑RGB-D框架:我们可以注意到,尽管SplaTAM在渲染图像方面效率很高,但在同时处理跟踪和映射方面却慢得多。使用分层特征网格的混合方法也是如此,另一方面,所需的GPU内存要少得多——与SplaTAM相比低4到5倍。最后,使用更高级的表示,如散列网格或点特征,可以实现更快的处理。这也通过对仅RGB方法的研究得到了证实,在中间,NeRF-SLAM比DIM-SLAM快6倍。最后,关于激光雷达SLAM系统,我们可以观察到PIN-SLAM是如何比Nerf LOAM高效得多的,在以近7 FPS的速度运行时只需要7 GB的GPU内存,而Nerf LOAM需要近12 GB和每帧4秒。
该分析强调了尽管新一代SLAM系统带来了巨大的前景,但它们中的大多数在硬件和运行时要求方面仍然不令人满意,使它们还没有准备好用于实时应用。
讨论
本节中,我们重点强调调查的主要发现。我们将概述通过所审查的最新方法取得的主要进展,同时确定该领域当前的挑战和未来研究的潜在途径。
场景表示。场景表示的选择在当前的SLAM解决方案中至关重要,它会显著影响映射/跟踪精度、渲染质量和计算。早期的方法,如iMAP,使用基于网络的方法,使用基于坐标的MLP隐式地对场景进行建模。虽然这些提供了紧凑、连续的场景建模,但由于在更新局部区域和缩放大型场景方面的挑战,它们难以进行实时重建。此外,它们往往会产生过度平滑的场景重建。随后的研究探索了基于网格的表示,如多分辨率分层和稀疏八叉树网格,这些网格已经很受欢迎。网格允许快速查找邻居,但需要预先指定的网格分辨率,这导致在空闲空间中内存使用效率低下,并且捕获受分辨率限制的精细细节的能力有限。最近的进展,如Point SLAM,支持基于混合神经点的表示。与栅格不同,点密度自然变化,无需预先指定。与基于网络的方法相比,点可以有效地集中在曲面周围,同时为细节分配更高的密度,从而促进可扩展性和本地更新。然而,与其他NeRF风格的方法类似,体积射线采样显著限制了其效率。有前景的技术包括基于3D高斯飞溅范式的显式表示,与以前的表示相比,这种表示表现出更快的渲染/优化。然而,在各种限制中,它们严重依赖初始化,对未观察到的区域的原始生长缺乏控制。
尽管在过去三年中取得了重大进展,但正在进行的研究仍在积极克服现有的场景表示限制,并寻找更有效的替代方案来提高SLAM的准确性和实时性能。
灾难性遗忘。现有的方法往往表现出忘记先前学习的信息的趋势,特别是在大型场景或扩展视频序列中。在基于网络的方法的情况下,这归因于它们依赖于单个神经网络或具有固定容量的全局模型,这些网络或模型在优化过程中会受到全局变化的影响。缓解这一问题的一种常见方法是在从历史数据中回放关键帧的同时,使用当前观测的稀疏射线采样来训练网络。然而,在大规模增量映射中,这种策略会导致数据的累积增加,需要复杂的重新采样过程来提高内存效率。遗忘问题延伸到基于网格的方法。尽管努力解决这一问题,但由于二次或三次空间复杂性,仍存在障碍,这对可扩展性提出了挑战。同样,虽然显式表示(如3DGS风格的解决方案)为灾难性遗忘提供了一种实用的解决方案,但由于内存需求增加和处理速度缓慢,尤其是在大型场景中,它们面临着挑战。一些方法试图通过使用稀疏帧采样来减轻这些限制,但这会导致整个3D空间的信息采样效率低下,与集成稀疏射线采样的方法相比,导致模型更新速度较慢且不太均匀。
最终,一些策略建议将环境划分为子图,并将局部SLAM任务分配给不同的代理。然而,这在处理多个分布式模型和设计有效策略来管理重叠区域同时防止地图融合伪影的发生方面带来了额外的挑战。
实时限制。所审查的许多技术在实现实时处理方面面临挑战,通常无法与传感器帧速率相匹配。这种限制主要是由于所选择的地图数据结构或基于计算密集型光线渲染的优化,这在NeRF风格的SLAM方法中尤为明显。特别地,使用分层网格的混合方法需要较少的GPU内存,但表现出较慢的运行时性能。另一方面,散列网格或稀疏体素等高级表示允许更快的计算,但对内存的要求更高。最后,尽管目前的3DGS风格的方法在快速图像渲染方面具有优势,但它们仍难以有效处理多时间跟踪和映射处理,阻碍了它们在实时应用中的有效使用。
全局优化。实现LC和全局BA需要大量的计算资源,冒着性能瓶颈的风险,尤其是在实时应用程序中。由于更新整个3D模型的计算复杂性过高,许多已综述的帧到模型方法都面临着闭环和全局束调整的挑战。相比之下,帧对帧技术通过在背景线程中执行全局BA来促进全局校正,这显著提高了跟踪精度,如所报道的实验所示,尽管与实时速率相比计算速度较慢。对于这两种方法,计算成本很大程度上是由于潜在特征网格缺乏灵活性,无法适应环路闭合的姿态校正。事实上,这需要重新分配特征网格,并在校正循环和更新姿势后重新训练整个地图。然而,随着处理帧数的增加,这一挑战变得更加明显,导致相机漂移误差的累积,最终导致不一致的3D重建或重建过程的快速崩溃。
SLAM中NeRF vs. 3DGS。NeRF风格的SLAM主要依赖于MLP,非常适合于新的视图合成、映射和跟踪,但由于其依赖于每像素光线行进,因此面临着过度平滑、易发生灾难性遗忘和计算效率低下等挑战。3DGS绕过每像素光线行进,并通过基元上的可微分光栅化来利用稀疏性。这有利于SLAM的显式体积表示、快速渲染、丰富的优化、直接梯度流、增加的地图容量和显式的空间范围控制。因此,尽管NeRF显示出非凡的合成新视图的能力,但其训练速度慢和难以适应SLAM是显著的缺点。3DGS以其高效的渲染、明确的表示和丰富的优化能力,成为一种强大的替代品。尽管有其优点,但当前3DGS风格的SLAM方法仍有局限性。这些问题包括大型场景的可扩展性问题、缺乏直接的网格提取算法、无法准确编码精确的几何体,以及无法控制的高斯增长到未观察到的区域的可能性,从而导致渲染视图和底层3D结构中的伪影。
评估不一致。缺乏标准化的基准或具有明确评估协议的在线服务器,导致评估方法不一致,难以在方法之间进行公平比较,并在不同研究论文中提出的方法中出现不一致。ScanNet等数据集的挑战就是例证,其中地面实况姿态是从Bundle Fusion中得出的,这引发了人们对评估结果的可靠性和可推广性的担忧。此外,使用训练视图作为输入来评估渲染性能会引发对特定图像过拟合风险的合理担忧。我们强调有必要探索在SLAM背景下评估新视图渲染的替代方法,并强调解决这些问题对更稳健的研究结果的重要性。
其他挑战。SLAM方法,无论是传统的、基于深度学习的,还是受辐射场表示的影响,都面临着共同的挑战。一个值得注意的障碍是动态场景的处理,由于静态环境的基本假设,这被证明是困难的,导致重建场景中的伪影和跟踪过程中的错误。虽然一些方法试图解决这个问题,但仍有很大的改进空间,尤其是在高度动态的环境中。
另一个挑战是对传感器噪声的敏感性,包括运动模糊、深度噪声和剧烈旋转,所有这些都会影响跟踪和映射的准确性。场景中存在的非朗伯对象(如玻璃或金属表面)进一步加剧了这种情况,由于其反射特性的变化,这些对象会带来额外的复杂性。在这些挑战的背景下,值得注意的是,许多方法往往忽视了对输入模式的明确不确定性估计,阻碍了对系统可靠性的全面理解。
此外,缺乏外部传感器,特别是深度信息,给仅RGB的SLAM带来了一个根本问题,导致深度模糊和3D重建优化收敛问题。
一个不那么关键但具体的问题是场景的渲染图像的质量。由于缺乏对模型中的视图方向进行建模,从而影响渲染质量,因此已审查的技术通常难以处理与视图相关的外观元素,如镜面反射。
结论
总之,这篇综述开创了受辐射场表示最新进展影响的SLAM方法的探索。从iMap等开创性作品到最新进展,这篇综述揭示了在短短三年内出现的大量文献。通过结构化的分类和分析,它突出了关键的局限性和创新,提供了有价值的见解和跟踪、绘制和渲染的比较结果。它还确定了当前悬而未决的挑战,为未来的探索提供了有趣的途径。
因此,这项调查旨在为新手和经验丰富的专家提供重要指南,使其成为这一快速发展领域的综合参考。






















