












来自腾讯的研究者们做了一个关于 agent 的scaling property(可拓展性)的工作。发现:通过简单的采样投票,大语言模型(LLM)的性能,会随着实例化agent数量的增加而增强。其第一次在广泛的场景下验证了该现象的普遍性,与其他复杂方法的正交性,以及研究了其背后的原因,并提出进一步促成scaling发挥威力的办法。

- 论文标题:More Agents Is All You Need
- 论文地址:https://arxiv.org/abs/2402.05120
- 代码地址:https://github.com/MoreAgentsIsAllYouNeed/More-Agents-Is-All-You-Need
本文中,来自腾讯的研究者发现:只需通过一种简单的采样投票法,大语言模型的性能就会随着实例化 agent 的数量的增大而增强,呈现scaling property(可拓展性),无需复杂的多 LLM agents 协作框架以及prompt工程方法的加持。此外,该方法与现有的复杂方法正交,结合之后,可进一步增强 LLM,其增强程度与任务难度相关。该论文做了第一个关于 raw agent(指不依赖复杂的prompt工程和协作框架的LLM agent)的 scaling property 的研究,其对各种 LLM 基准进行了全面的实验,以验证此发现的普遍性,并研究了可以促进其发生的策略。目前代码已开源。

多个小模型超过大模型
论文讨论了诸多集成 LLM 的相关工作,包括 LLM 自集成、异构 LLM 集成、还有关于多个 LLM Agents 协作框架的工作,并与提出的方法进行了对比,可以看出论文进行了更全面的研究和分析:

为了研究大型语言模型的性能如何随着实例化 agents 数量的增加而提升。论文使用了一种简单的采样和投票方法(作者用了 simple (st) 的说法,可见他们认为这个方法也许是最简单的方法之一)。值得注意的是,此方法可与现有的复杂方法正交结合。它可以被分为两个阶段:
- 将任务 query 输入到单个 LLM 或多个 LLM Agents 协作框架中,生成多个输出;
- 通过多数投票确定最终结果

论文从 Llama2 和 GPT 系列选择不同规模的语言模型进行评估,任务数据集涵盖推理和生成等多个领域。实验结果表明,在所有任务和不同种类、规模的 LLM 上,发现 LLM 的性能随着实例化 agent 的数量而增加。

例如,在 GSM8K 任务上提升了 12% 至 24%,在 MATH 上提升了 6% 至 10%。有趣的是,多个小 LLM 集成可以达到甚至超越较大 LLM 的性能。例如,多个 Llama2-13B 的集成在 GSM8K 上达到了 59% 准确率,超过了单一 Llama2-70B 的 54% 的准确率。

进一步地,作者还探索了与其他方法的兼容性。尽管这些方法实现各不相同,但是在与之结合使用时,性能可以进一步提升,并同样符合实例化 agent 越多,性能增益越强的现象。实验结果显示增益范围从 1% 到 27% 不等,说明这个简单的方法通过和其他方法正交使用可以进一步增强 LLM 的性能。
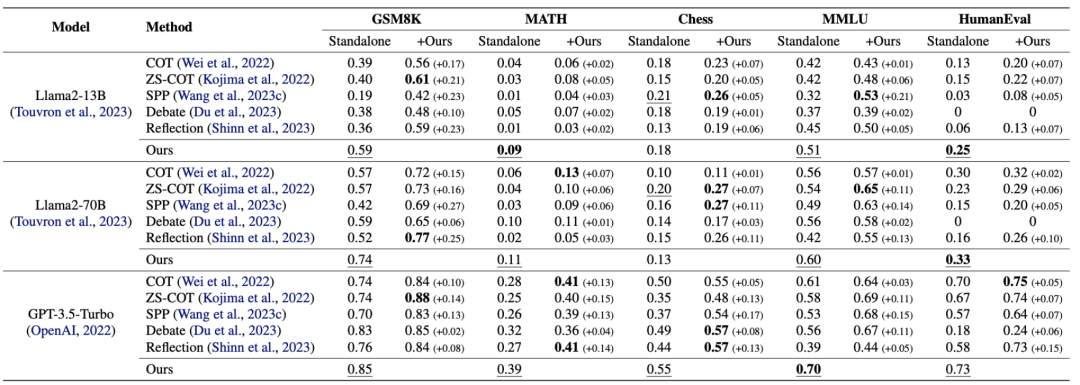

基于 LLama13B

基于 LLama70B

基于 GPT-3.5-Turbo
此外,论文还分析了性能提升与问题难度之间的关系。
- 固有难度:随着任务固有难度的增加,性能提升(即相对性能增益)也会增加,但当难度达到一定程度后,增益会逐渐减少。这表明在任务过于复杂时,模型的推理能力可能无法跟上,导致性能提升的边际效应递减。
- 步骤数量:随着解决任务所需的步骤数量增加,性能提升也会增加。这表明在多步骤任务中,通过增加 agent 数量可以帮助模型更好地处理每一步,从而整体提高任务的解决性能。
- 先验概率:正确答案的先验概率越高,性能提升越大。这意味着在正确答案更有可能的情况下,增加 agent 数量更有可能带来显著的性能提升。

节点:步骤,虚线:可能的替代步骤。节点的深度:步骤的数量,颜色的强度:固有难度的水平。图示帮助读者理解任务的复杂性是如何通过这些维度来衡量的。
基于此,论文提出了两种优化策略来进一步提升方法的有效性:
- 逐步采样和投票(Step-wise Sampling-and-Voting):这种方法将任务分解为多个步骤,并在每个步骤中应用采样和投票,以减少累积错误并提高整体性能。
- 分层采样和投票(Hierarchical Sampling-and-Voting):这种方法将低概率任务分解为多个高概率子任务,并分层解决,同时可以使用不同模型来处理不同概率的子任务以降低成本。

最后,提出了未来的工作方向,包括优化采样阶段以降低成本,并继续开发相关机制来减轻 LLM 幻觉(hallucinations)的带来的潜在负面影响,确保这些强大模型的部署既负责任又有益。























