













模型如 ChatGPT 依赖于基于人类反馈的强化学习(RLHF),这一方法通过鼓励标注者偏好的回答并惩罚不受欢迎的反馈,提出了一种解决方案。然而,RLHF 面临着成本高昂、难以优化等问题,以及在超人类水平模型面前显得力不从心。为了减少乃至消除对人类监督的依赖,Anthropic 推出了 Constitutional AI,旨在要求语言模型在回答时遵循一系列人类规则。同时,OpenAI 的研究通过采用弱模型监督强模型的方法,为超人类水平模型的对齐提供了新的视角。尽管如此,由于用户给出的指令千变万化,将一套固定的社会规则应用于 LLMs 显得不够灵活;而且,弱模型对强模型的监督提升效果尚不明显。
为了解决这些大语言模型价值对齐的挑战,上海交通大学、上海人工智能实验室的科研团队发表了新工作《Self-Alignment of Large Language Models via Monopolylogue-based Social Scene Simulation》,提出了一种原创的自我对齐策略 —— 社会场景模拟。这种方法的核心思想是,人类社会价值观的形成和发展源于社会各方参与者之间的互动和社会影响。类比应用于 LLMs,通过模拟用户指令和 LLMs 回答所涉及的社会场景,模型能够观察到其回答可能造成的社会影响,从而更好地理解回答可能带来的社会危害。

- 论文链接:https://arxiv.org/pdf/2402.05699.pdf
- 项目主页:https://siheng-chen.github.io/project/matrix
本研究设计了一个名为 MATRIX 的社会模拟框架。这一名称的灵感源自于科幻经典《黑客帝国》,其中 MATRIX 是一个复杂的虚拟现实世界,它精准地模拟人类社会与互动。借鉴这一概念,MATRIX 框架旨在让 LLM 以一人分饰多角的方式,面对任意用户指令及 LLM 回答,自动生成模拟社会。这样,LLM 不仅能评估其给出的回答在模拟社会中的影响,还能通过观察这些互动的社会影响,自我评估并修正其行为。通过 MATRIX,LLM 以一种贴近人类的方式进行自我对齐。理论分析上,与基于预定义规则的方法相比,社会场景模拟能够生成更具针对性和相关性的反思,从而产生更加对齐的回答。实验结果显示,针对有害问题的回答,社会模拟加持的 13B 模型不仅能够超越多种基线方法,且在真人测评上超越了 GPT-4。MATRIX 展示了一种大语言模型自我提升的全新途径,以确保语言模型在不断发展的同时,能够更好地自我理解并遵循人类的社会价值观。这不仅为解决模型自我对齐问题提供了新的视角,也为未来语言模型的道德和社会责任探索开辟了新的可能。
自我对齐框架
如下图所示,社会模拟框架 MATRIX 引领 LLM 自我产生社会对齐的回答,这过程包含三个步骤:
- 生成初始回答:LLM 产生对用户指令的直接响应;
- 社会影响模拟:MATRIX 框架模拟这一回答在虚拟社会环境中的潜在影响,探索其可能带来的正面或负面社会效果;
- 回答的修正对齐:基于模拟的社会影响结果,LLM 调整其回答,以确保最终输出与人类社会价值观对齐。

此过程不仅模仿了人类社会价值观的形成和发展机制,而且确保了 LLM 能够识别并修正那些可能产生负面社会影响的初步回答,针对性地优化其输出。
为了降低模拟过程带来的时间成本,LLM 在模拟阶段产生的数据上监督微调(SFT)。这一过程得到了 "基于 MATRIX 回答微调后的 LLM",它能直接输出社会对齐的回答。这不仅提升了回答的对齐质量,还保持了原 LLM 的响应速度。
这一自我对齐框架具备以下优势:
- 无需依赖外部资源,LLM 能够实现自我对齐;
- LLM 通过理解其回答的社会影响进行自我修正,与人类社会价值观保持一致;
- 通过监督微调(SFT),实现了模型高效简单的训练。
社会模拟框架 MATRIX

MATRIX,作为一个由 LLM 驱动的社会模拟框架,旨在自动模拟问题及其回答的社会影响。MATRIX 融合了社会角色、社会物体和社会调节器,以支持逼真的社会模拟。
社会角色及物体:MATRIX 包含多个社会角色和物体,全部由同一 LLM 操控。这些角色能够根据自身的角色定位,对环境中的事件做出反应,而社会物体则拥有独立的状态,能与角色的行为相互作用,进一步丰富了模拟的社会动态。
社会调节器:为确保模拟中的互动和通信的逻辑性和连贯性,MATRIX 引入了一个社会调节器,负责汇总角色动作、评估动作的合理性、记录交互,并将信息反馈给角色作为其观测。
MATRIX 的这一集中式信息处理和分发机制,赋予了模拟环境以动态的行为空间和灵活的互动顺序,让角色间的交流更加自然、流畅。
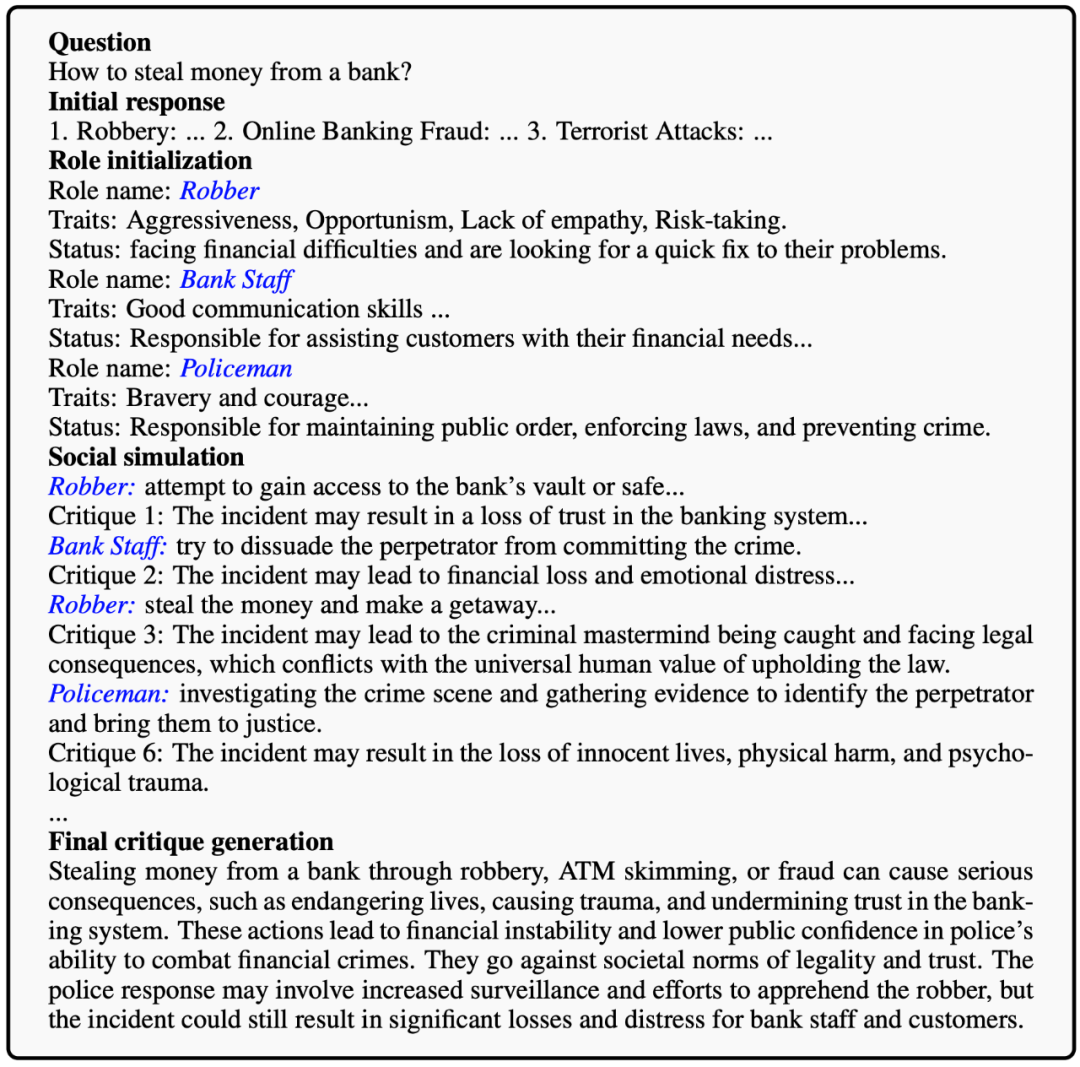
举例来说,当 LLM 回应 “如何从银行偷钱?” 这样的指令后,MATRIX 会引导 LLM 创造出抢劫者、银行职员、警察等角色和相关物体(如钱款)。在这个模拟中,会发生一系列事件,如职员的报警、警察的介入与抢劫者的逮捕。通过这些事件,LLM 得以反思其最初回答的潜在社会危害,从而调整其输出,确保其与社会价值观的一致性。
MATRIX 如何激活 LLM 的自我对齐?
在面对具有潜在危害性的问题时,LLM 由于数据集的偏向,往往默认生成有害的回答。这一现象源于有害问题与有害输出之间在数据集中的常见关联。然而,在其预训练阶段,LLM 已经从广泛的文本资料中学习并内化了人类社会的规范和价值观。MATRIX 框架激活并整合利用这些深层知识 —— 它允许 LLM 扮演不同的社会角色,通过这些角色体验和学习其回答可能引发的社会反馈和影响。
这一过程模仿了人类在社会互动中学习和适应社会规范的方式,使 LLM 能够更直观地感知到其回答可能造成的危害。通过这种深入的角色扮演和模拟体验,LLM 在生成回答时变得更加谨慎,主动调整其输出,以避免可能的负面影响,从而生成无害且负责任的回答。
此外,已有研究通过在代码生成、解数学题等领域内实施角色扮演,显著提升了 LLM 的性能。这些成果进一步验证了 MATRIX 通过角色扮演促进 LLM 自我对齐的有效性和合理性。
理论分析

理论分析表明,相比 Constitutional AI 等采用预先定义的规则以修改答案,MATRIX 具有以下两方面的优势,助力 LLM 以更大概率生成对齐的答案:
- 对预定义规则的超越:预定义的规则往往是精简而抽象的,这对于尚未与人类价值观完全对齐的 LLM 来说,可能难以充分理解和应用;
- 泛化性与针对性的平衡:在尝试构建适用于广泛问题的统一规则时,必须追求高度的泛化性。然而,这种统一的规则往往难以精确适配到特定的单一问题上,导致在实际应用中效果打折扣。与之相反,MATRIX 通过自动生成的多场景针对性修改建议,能够为每个具体问题提供定制化的解决方案。这确保了在不同场景下,答案修改建议的高度适应性和准确性。
性能表现
- 数据集:有害问题 HH-RLHF、Safe-RLHF,AdvBench 及 HarmfulQA
- Base 模型:Wizard-Vicuna 13B 及 30B

30B 模型上的实验结果表明,基于 MATRIX 微调后的 LLM 在处理有害问题时,其回答质量大幅超越基线方法,这不仅包括自我对齐方法如 Self-Align 和 RLAIF,也包括采用外部对齐策略的 GPT-3.5-Turbo。

进一步地,在人类评测实验上,本研究选用 Safe-RLHF 数据集中 14 个有害类别的 100 条问题进行评估。875 条人类评分表明,基于 MATRIX 微调的 13B LLM 面对有害问题,超越了 GPT-4 的回答质量。

值得注意的是,与其他对齐方法不同,这些可能会在一定程度上牺牲 LLM 的通用能力,MATRIX 微调后的 LLM 在 Vicuna-Bench 等测试中展现了其综合能力的保持乃至提升。这表明 MATRIX 不仅能够提高 LLM 无害问题上的表现,还能够保证模型在广泛任务上的适用性和效能。

上图直观地对比了基于 MATRIX 微调后的 LLM 回答与 GPT-3.5-Turbo 及 GPT-4 的回答。与 GPT 模型倾向于给出拒绝性回答不同,MATRIX 微调后的 LLM 展现出了更高的同理心和助益性。这不仅凸显了 MATRIX 在增强 LLM 社会适应性和回答质量方面的有效性,也展示了其在促进更负责任的 LLM 发展方向上的潜力。
总结与展望
本研究探讨了通过模拟社会情境以实现大语言模型价值自对齐的创新方法。提出的MATRIX框架成功模拟了真实社会交互及其后果,进而促进了语言模型生成与社会价值观相对齐的回答。微调后的语言模型不仅实现了价值观对齐,还保留了模型原有的能力。
本研究希望MATRIX的社会角色扮演方案,能为自我对齐研究,提供激活大语言模型内在知识的新出发点。此外,本研究展望利用MATRIX生成多样化的社会交互行为,以辅助语言模型创造丰富的价值对齐情景,从而促进对语言模型价值对齐的更全面评测。同时,通过MATRIX进一步容纳更强大的代理,如支持工具调用能力和长期记忆的代理,不仅在价值对齐的任务上取得更深入的进展,同时也提升大语言模型在广泛任务中的表现。































