













最近爆火的AI初创公司Groq,推出了比目前常见GPU推理系统快4倍,成本低70%的大模型推理解决方案。

他们提供的运行Mistral Mixtral 8x7b的API演示,让大部分习惯了其他LLM「娓娓道来」的用户直呼,简直是魔法!
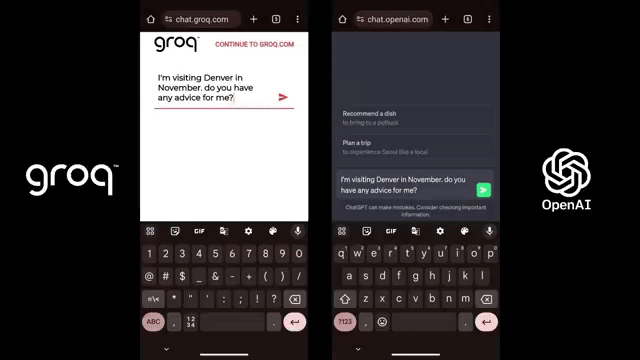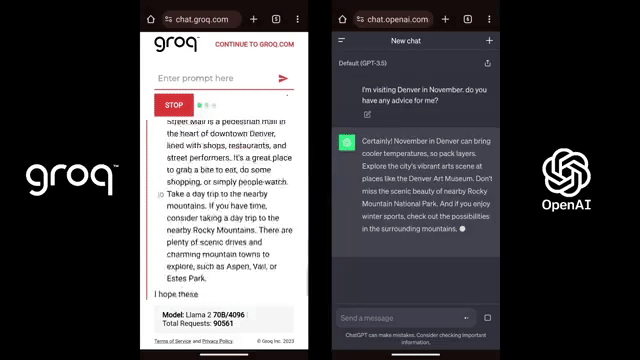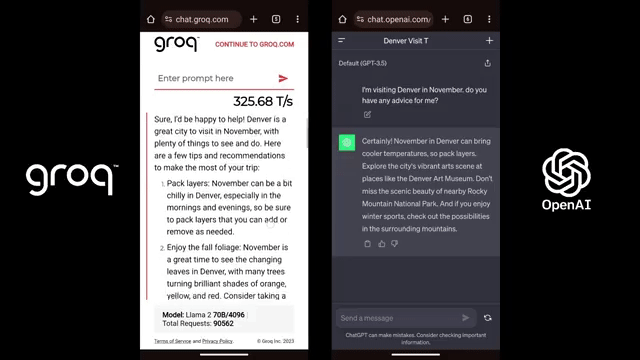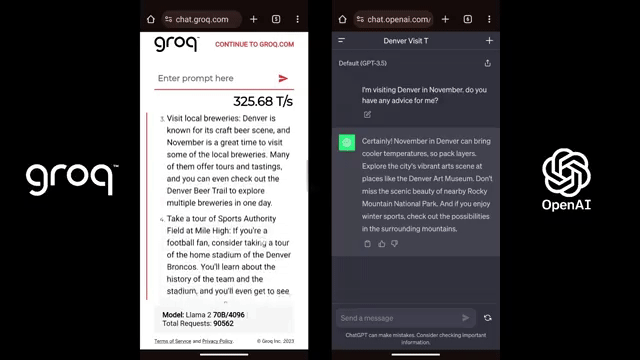
Groq在处理单个数据序列方面展现出了惊人的性能优势,这可能使得「思维链」等技术在现实世界中变得更加实用。
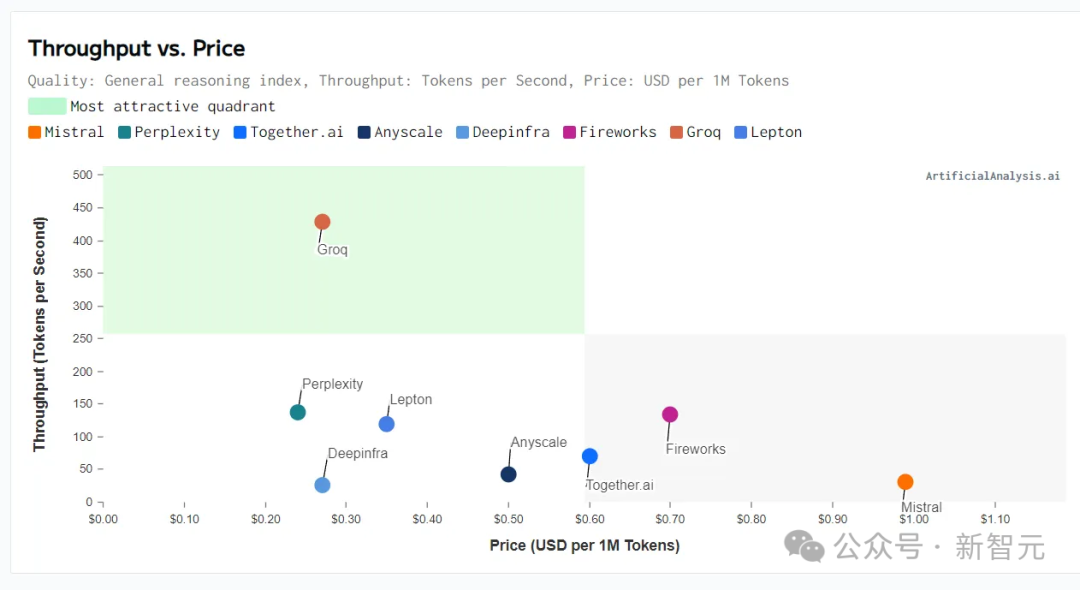
虽然Groq有如此之多的好处,但评估某款硬件是否真的具有革命性的核心标准是性能与总成本的比值。
为此,SemiAnalysis首席分析师Dylan Patel和分析师Daniel Nishball写了一篇万字长文,对Groq进行了深度地剖析。
「推理速度打破纪录,但代价是什么呢?」

现在没有人会怀疑AI时代已经到来,重要的是要认识到,AI驱动软件的成本结构与传统软件有非常大的不同。
在开发和扩展AI软件规模的过程中,芯片微架构和系统架构起着关键作用。
与之前的软件代相比,AI软件运行的硬件基础设施(Infra)对资本支出(Capex)和运营支出(Opex)以及随后的毛利润有更大的影响。
因此,优化AI基础设施,让AI软件的规模化部署成本控制在合理范围内变得尤为重要。
在基础设施方面具有优势的公司,也将在部署和扩展AI应用方面具有很大优势。
谷歌在基础设施方面的领先地位,是为什么Gemini 1.5对谷歌来说提供服务的成本比OpenAI GPT-4-Turbo更低,同时在许多任务,特别是长序列代码生成方面表现更好的原因。
谷歌使用更多的芯片来进行单个推理任务,但他们实现了更好的性能与总成本比。
于是,在这样的大背景下,性能不仅仅以为单个用户生成的原始Token的速率为唯一的指标,比如延迟优化。
在评估总成本时,必须考虑硬件同时服务的用户数量。
这就是为什么提高用于大语言模型推理的边缘硬件的性能吸引力没有那么强的主要原因。
大多数边缘系统因为不能在大量用户中摊销增加的硬件成本,而无法弥补运行大语言模型所需的增加硬件成本。
对于同时服务许多用户且批处理大小极大的情况,即吞吐量和成本优化,GPU是首选。
许多公司在其Mistral API推理服务上实际上是在亏损。
一些公司还设定了非常低的速率限制以减少经济上的损失。
但是只要提供未量化过的模型(FP16)需要至少64+的批大小才能盈利。
因此,Mistral、Together和Fireworks在提供Mistral服务时基本都处于收支平衡到略有利润的临界点上。
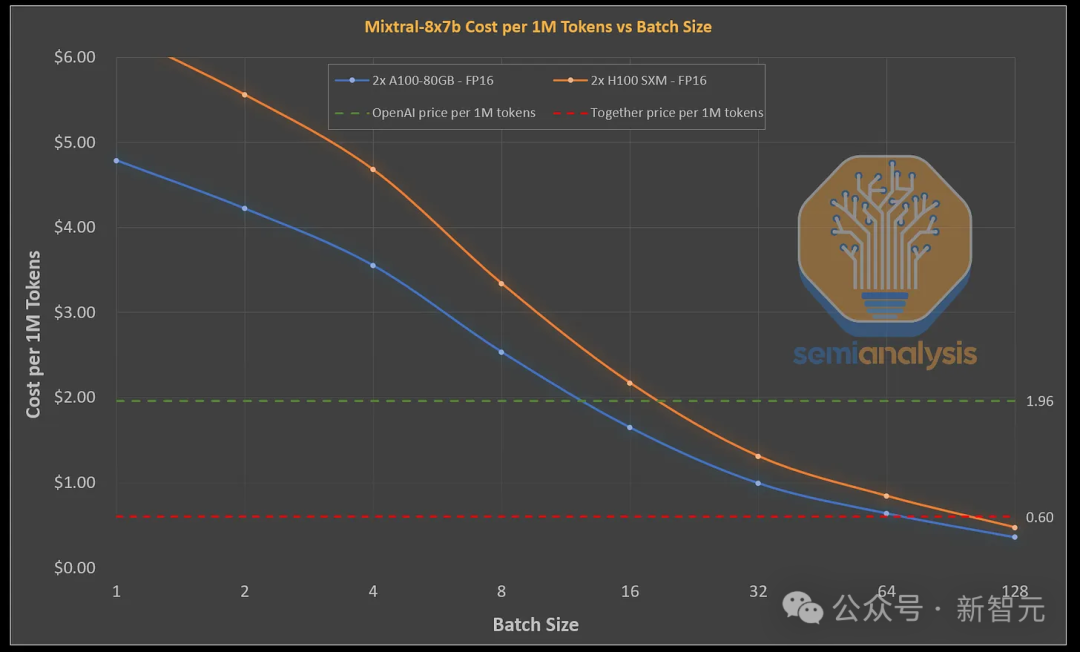
但对于其他提供Mixtral API的公司而言,情况并非如此。
他们要么在关于模型简化(量化)的声明上没有明确说清楚,要么正通过消耗风投资金来吸引客户群。
也就是说,基本上提供大模型服务的公司成本都是一个很严峻的问题。
而Groq则采取了一种大胆策略,将每百万Token的价格定为仅0.27美元,直接打起了价格战。
这样的低价是否是基于性能/总拥有成本(TCO)的考量,正如Together和Fireworks所做的那样?
还是说,这是一种通过补贴来刺激市场热度的策略?
值得注意的是,Groq最近一次融资是在2021年,去年还进行了一轮5000万美元的安全可转换债务(SAFE)融资,目前他们正在进行新一轮的筹资活动。
现在就来深入探讨Groq的芯片、系统和成本分析,来看看他们是如何将大模型的推理成本打下来的。
Groq构架解密
Groq的芯片采用了一种无缓冲、完全确定性的超长指令字(VLIW)架构,芯片面积约为725平方毫米,采用Global Foundries的14纳米制程技术。
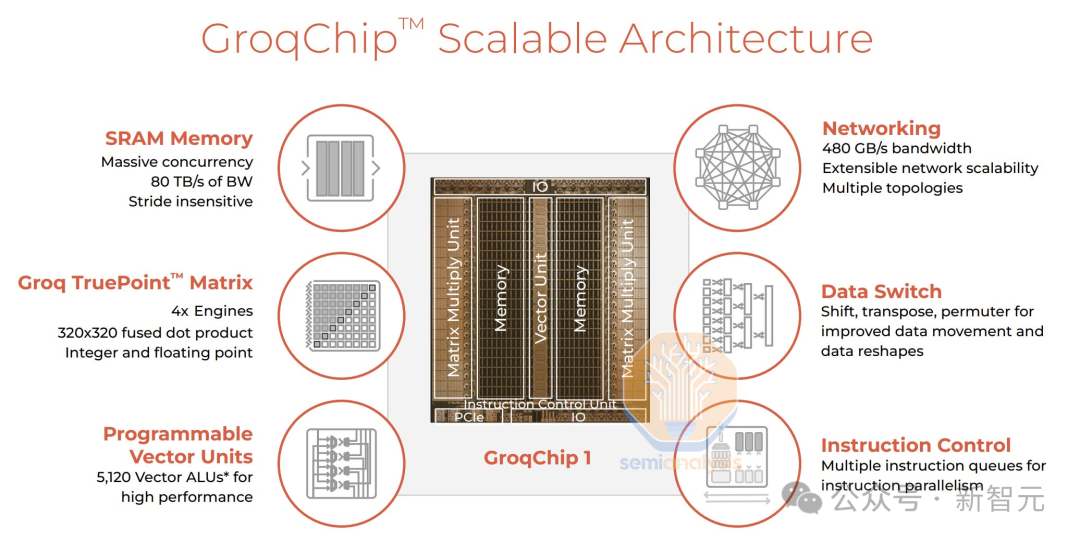
芯片不依赖外部内存,其权重、键值缓存(KVCache)和激活函数等数据在处理期间全部存储在芯片内。
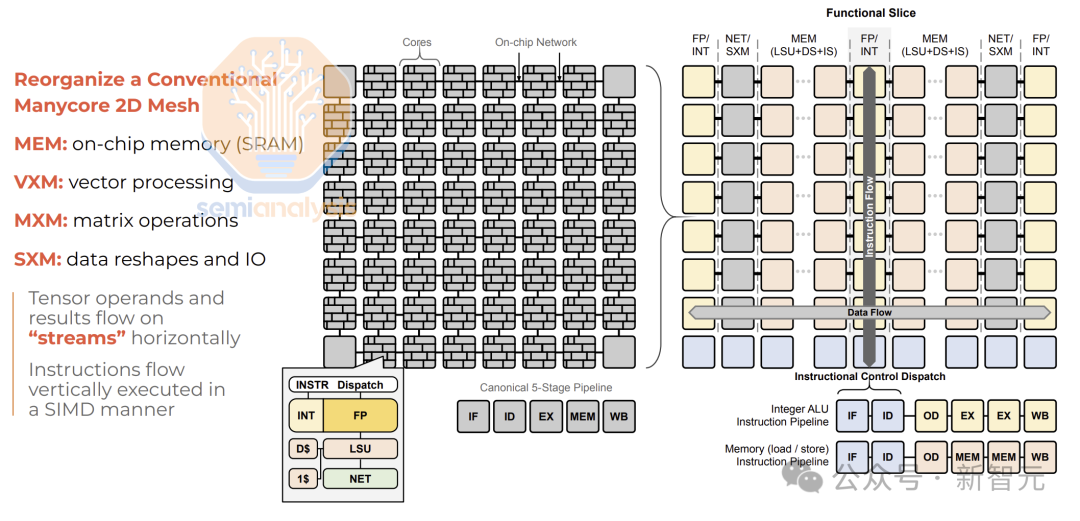
由于每块芯片只配备了230MB的静态随机存取存储器(SRAM),没有任何复杂的模型能够仅通过单个芯片运行。

因此,为了容纳整个模型,必须使用多个芯片并将它们互联。
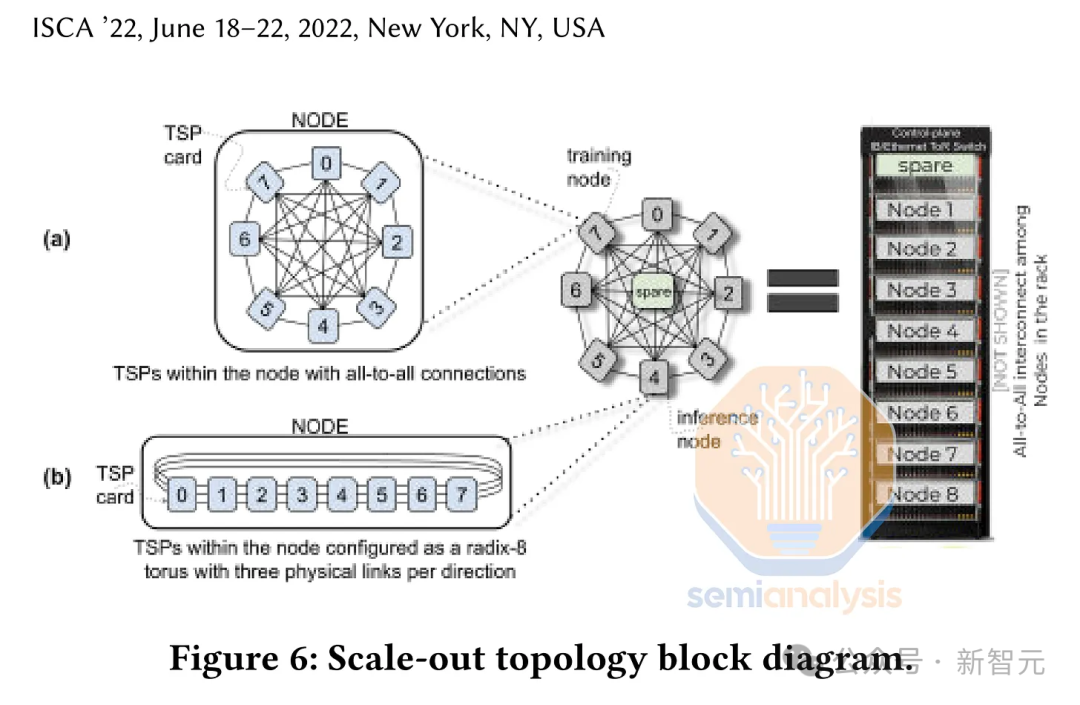
对于Mixtral模型,Groq需要使用包含576块芯片的大规模服务器集群来支持其运行,这涉及到8个机架,每个机架装有9台服务器,每台服务器则装有8块芯片。
和英伟达H100的成本对比
而英伟达只需使用一到两块H100芯片,就能根据需要处理的数据量大小,轻松适配同一模型。
Groq制造芯片所需的晶圆成本相对较低,可能不超过每晶圆6000美元。
相比之下,英伟达的H100芯片采用TSMC定制的5nm工艺生产,每晶圆成本约为16000美元。
但是,英伟达通过在大部分H100芯片上禁用约15%的部分来提高良品率,这种方法对Groq来说不太适用。
英伟达还需要为每颗H100芯片支付大约1150美元,以从SK Hynix购买80GB的高带宽存储器(HBM),并且还要承担TSMC的芯片封装技术(CoWoS)相关费用和可能的良品率损失。
相比之下,Groq的芯片不需要外部存储器,因此原材料成本要低得多。
作为一家初创公司,Groq在生产芯片时面临的固定成本相对较高,这还包括支付给Marvell的高额定制ASIC服务费用。
下表展示了三种不同的部署情况:一种是Groq的,预计下周将在生产中采用批大小为3的流水线并行处理;另外两种则分别针对英伟达H100芯片的延迟优化和吞吐量优化部署方案,展示了使用推测性解码技术的配置。
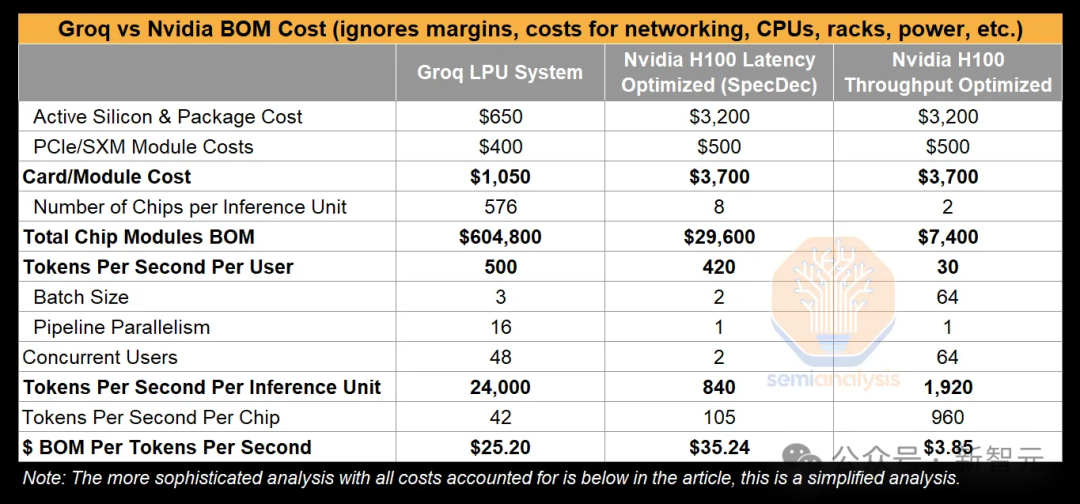
上述分析极大地简化了成本计算(同时没有考虑稍后要深入讨论的大量系统级成本,也未考虑英伟达的巨额利润)。
核心观点是,比起进行了延迟优化的英伟达系统,Groq在每输出一个Token所需的硅材料成本方面,由于其芯片架构的优势,表现得更为经济。
8块A100芯片可以支持Mixtral模型,达到每个用户每秒大约220个Token的处理速度,而8块H100芯片在不使用推测性解码的情况下,可以达到每个用户每秒大约280个Token。
通过采用推测性解码,8块H100芯片组成的推理单元可以实现接近每个用户每秒420个Token的处理速度。
尽管理论上吞吐量可以更高,但在MoE模型上应用推测性解码存在挑战。
目前,由于成本效益极差,还没有针对延迟进行优化的API服务。
API提供商目前看不到通过收取高达10倍费用以降低延迟的市场需求。
随着代理和其他要求极低延迟的任务变得越来越受欢迎,基于GPU的API供应商可能会推出延迟优化而设计的API,以补充他们现有的为吞吐量优化的API。
即便采用了推测性解码,针对延迟进行优化的英伟达系统在吞吐量和成本上仍然远远落后于即将实施批处理系统的Groq。
此外,Groq正在使用较旧的14nm工艺技术,并向Marvell支付了高额芯片利润。
如果Groq获得更多资金,并能够在2025年下半年前增加他们下一代4nm芯片的生产,经济效益可能会发生显著变化。
英伟达的后手
值得注意的是,英伟达并非没有应对策略,预计他将在不到一个月的时间内宣布他们的下一代B100芯片。
在吞吐量优化的系统中,经济效益发生了显著变化。
英伟达系统在成本效益上实现了数量级的提升,尽管每用户的处理速度较低。在吞吐量优化的场景中,Groq在架构上完全无法竞争。
然而,上述的简化分析并不适用于那些购买和部署系统的用户,因为这种分析忽略了系统成本、利润、能耗等多个重要因素。
因此,提出了一个基于性能/总拥有成本的分析。
在考虑了这些因素之后,再来计算每个token的成本情况就完全不一样了。
在英伟达方面,将使用下文展示的GPU云成本来进行分析。
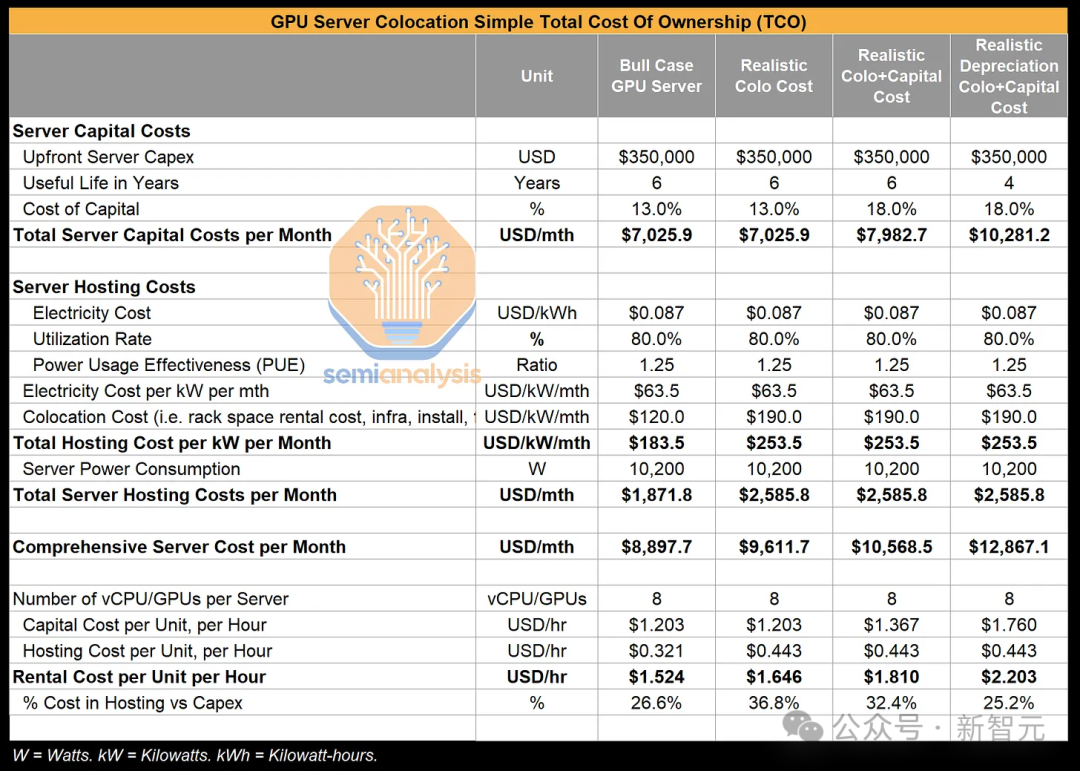
英伟达GPU主板有很高的利润率。
此外,服务器的售价高达35万美元,这个价格远超过了大型云服务商对H100服务器的采购成本,其中还包括了高昂的内存成本、8个InfiniBand网络接口卡,总带宽达到3.2Tbps(实际上这对于该推理应用并不必要),以及在英伟达利润之上的额外OEM利润。
对于Groq,在估算系统成本时,考虑到了芯片、封装、网络、CPU、内存等方面的细节,并假设了一个较低的整体制造商利润。
没有计入Groq出售硬件时的利润,因此虽然看似是不同的比较基准,但实际上这是一个公平的比较,因为Groq和推理API供应商提供的是相同的产品/模型。
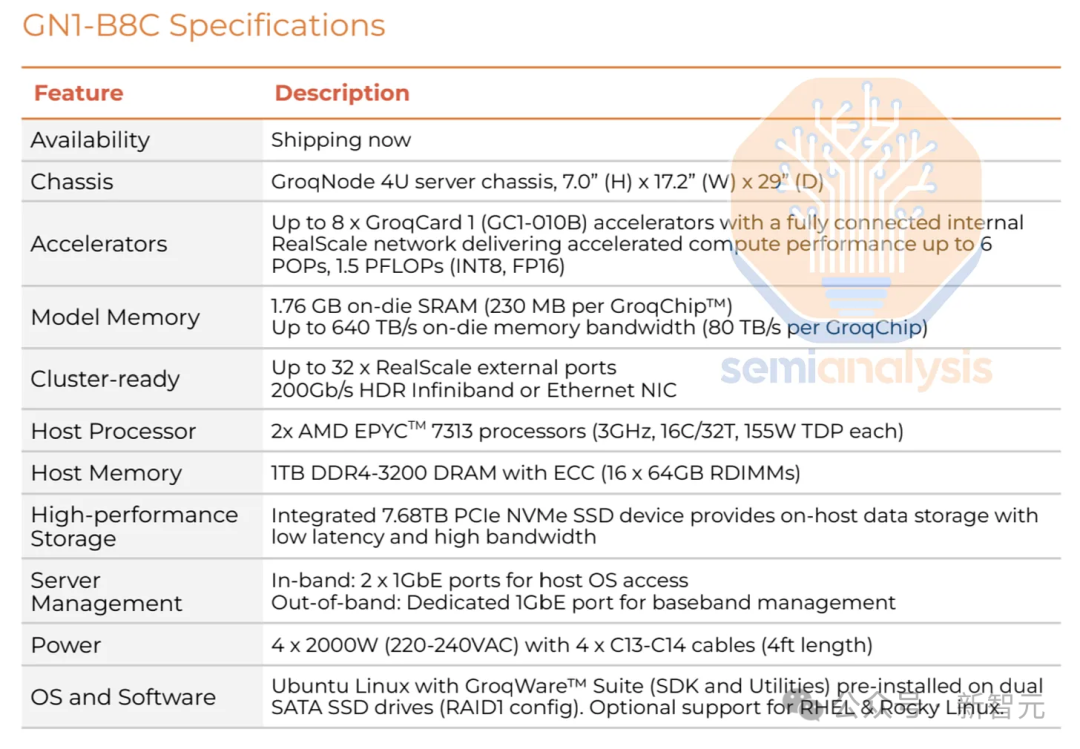
值得一提的是,8个英伟达GPU只需要配备2个CPU,而Groq的系统则配备了144个CPU和144TB的RAM,规模显著不同。
把这些组件的成本加在一起后可以发现,每台Groq LPU服务器的成本为3.5万美元,包括8个Groq LPU和所有上述的硬件。
Mixtral Groq推理部署采用了8个机架,每个机架有9台服务器,总成本为252万美元,整个部署共有576个LPU芯片。
相比之下,一个标准的H100 HGX系统的初始投资成本为35万美元,包含了8个H100芯片。而大多数基于H100的Mixtral推理实例,只需要用到其中的2个H100芯片。
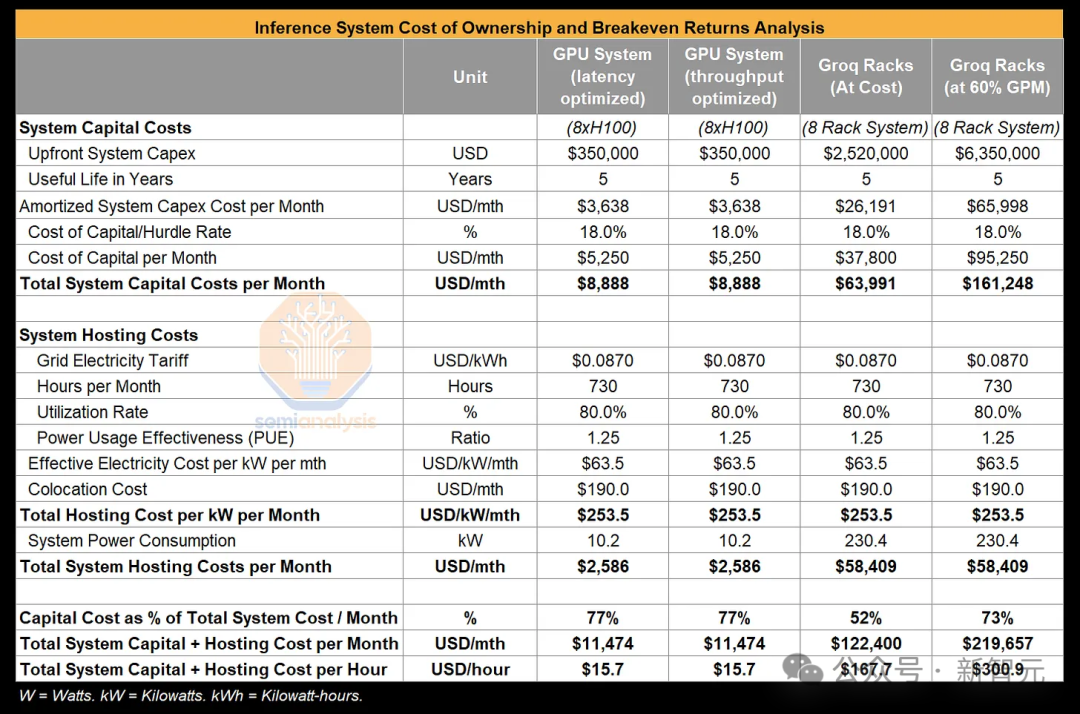
假设资本回报率为18%并且预计使用寿命为5年,H100系统的平均成本为8888美元/月,再加上2586美元/月的托管费用,整体的拥有成本达到了11474美元。
相比之下,更大规模的Groq系统的总拥有成本,高达每月12.24万美元。
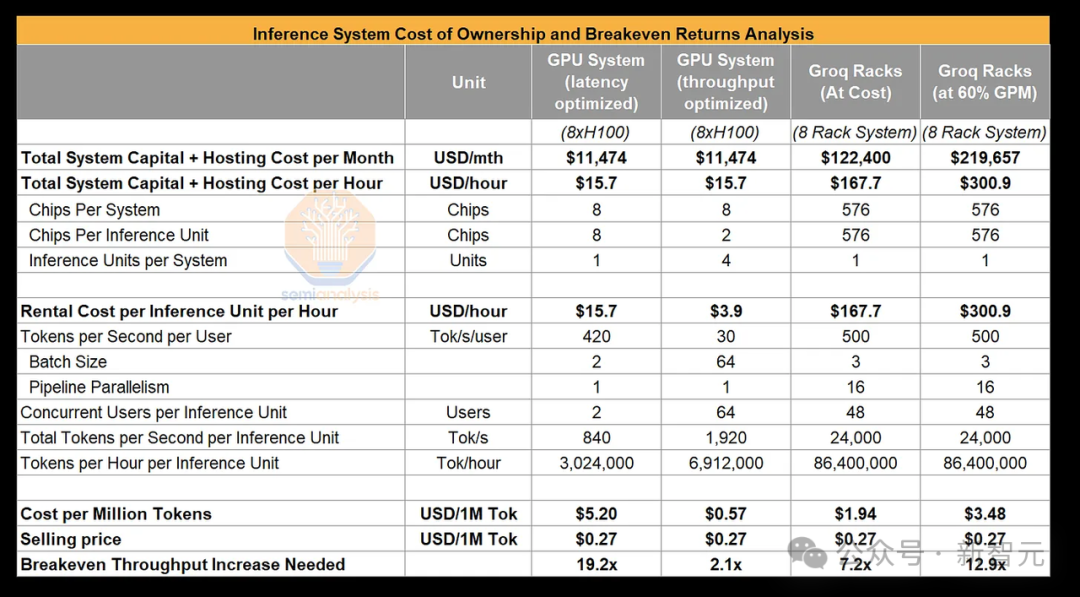
在针对延迟优化的配置下,8块H100服务器的部署成本为每百万Token 5.2美元,而针对吞吐量优化的2个H100服务器的部署仅需0.57美元。
与之相对,Groq的解决方案每百万Token的成本为1.94美元,比8个H100的配置更经济,也更高效。
和许多提供推理服务的公司一样,Groq目前的运营模式尚未实现盈利。
而想要达到收支平衡,Groq需要将其处理速度提高超过7倍。
这一目标比基于8个H100服务器的延迟优化配置要容易得多——在相同定价下要实现盈亏平衡,效率需要提高近20倍。
Groq的商业模式,不仅是提供推理API服务,还包括直接销售硬件系统。
如果Groq以60%的利润率向第三方运营商出售,那么总成本将与英伟达的H100 HGX相当,预计售价为大约635万美元。
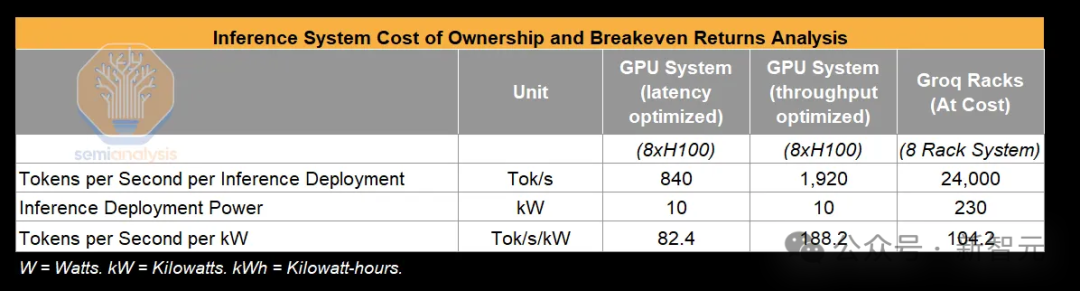
尽管Groq宣称其系统在能耗上具有优势,但从现有数据来看,这一点尚不明显。
即使在对H100服务器的极端假设下,包括CPU和所有8个NIC全速运行也只需10千瓦电力,这比Groq的576芯片服务器所需的230千瓦(每8芯片服务器约3.2千瓦)要高效得多。
Groq声称自己在每瓦性能上具有优势,但根据现有的信息很难验证这一点。
需要注意的是,尽管Groq在API业务上目前面临亏损,并且需要通过超过7.2倍的性能提升才能实现盈亏平衡,但他们已经规划了在未来几个季度通过一系列改进达成这一目标。
这些改进主要通过以下三个方向:
- 持续进行编译器的优化工作,以提升数据处理速度;
- 推出新的服务器设计,大幅减少除了芯片外的其他成本,如减少使用的CPU数量和内存大小;
- 部署更大规模的系统,通过增加处理流水线数量实现更高的数据批处理能力,这不仅可以提升性能,还能支持更大的AI模型。
虽然每项改进措施本身看似合理,但要实现7倍的性能提升无疑是一项巨大的挑战。
挑战
目前,最大的模型参数在1到2万亿之间。不过,谷歌和OpenAI很可能会推出超过10万亿参数的模型。同时,Llama 3和更大规模的Mistral模型也即将推出。
而这将需要配备数百个GPU和数十TB内存的强大推理系统。
目前,Groq已经证明他们有能力构建适用于处理不超过1000亿参数模型的系统,并且计划在两年内部署100万块芯片。
挑战一:处理极长的上下文信息
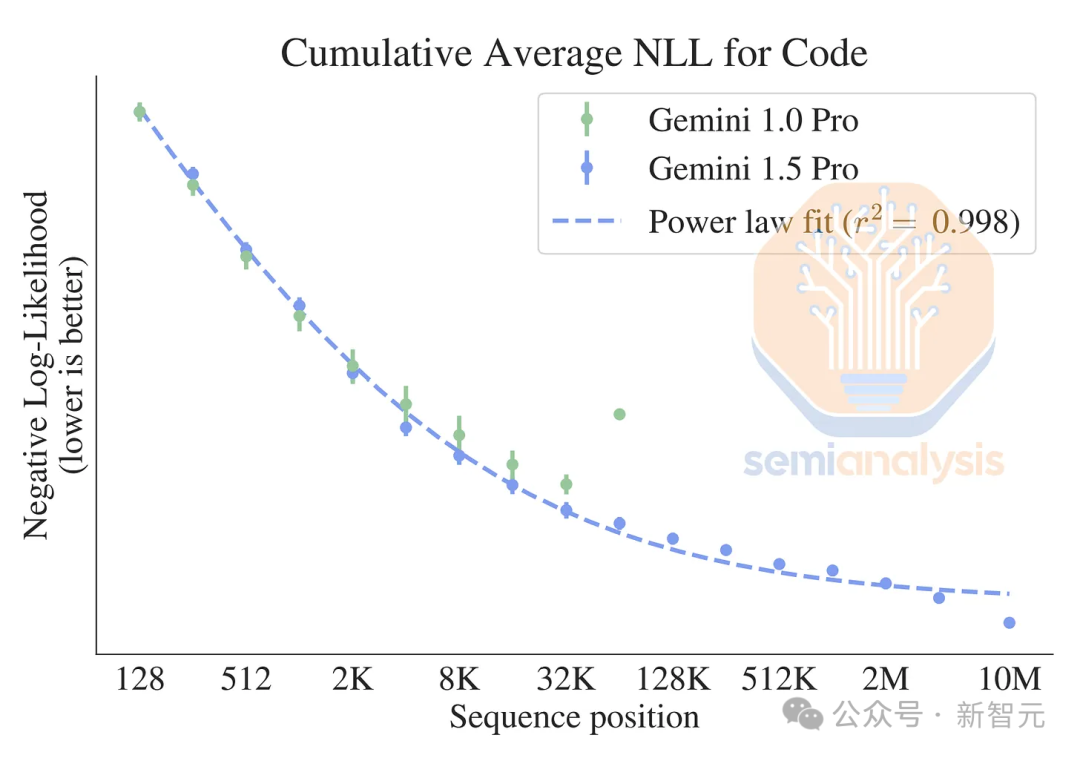
谷歌的Gemini 1.5 Pro可以处理高达1000万token的上下文,这相当于可以处理10小时的视频、110小时的音频、30万行代码或700万字的内容。
分析师预计,很多公司和服务商很快就会跟进对长上下文的支持,以便更好地管理和应用庞大的代码库和文档库,从而进一步取代在实际应用中表现不佳的RAG模型。
尽管谷歌的处理方式并非传统的注意力机制,后者的处理复杂度是O(n^2),但Gemini 1.5 Pro仍需数百GB甚至TB级别的内存来存储键值缓存(KVCache)。
相比之下,Groq在面对长上下文需求时,需要构建的是由数万芯片组成的系统,而不是谷歌、英伟达和AMD等使用的几十或几百芯片。
可以预见,GPU在四年后依然能够凭借出色的灵活性处理新的模型。但对于缺少动态随机存取内存(DRAM)的Groq来说,随着模型规模的不断增大,这可能会缩短系统的折旧寿命,从而大幅增加成本。
挑战二:推测性解码等技术的快速发展
树状/分支推测方法,已经使得推测性解码的速度提升了约3倍。
如果进一步在生产级系统上高效部署的话,那么8块H100的处理速度就可以达到每秒600个Token,而这将直接让Groq在速度上的优势不复存在。
通常,推测性解码需要通过牺牲浮点运算性能(FLOPS),来换取更高的批处理大小带来的带宽效率。此时,Groq主要受到FLOPS和网络的限制,而非静态随机存取内存(SRAM)的带宽。
挑战三:英伟达更强的GPU即将发货
与此同时,英伟达显然也不会站着挨打。
就在下个月,性能/总拥有成本(TCO)据传是H100两倍以上的B100就会发布,并在下半年开始发货。与此同时,英伟达还在迅速推进B200和X/R100的研发。
尽管如此,如果Groq能够有效扩展到数千芯片的系统,那么流水线的数量就可以得到大幅增加,而每个管线阶段的额外静态随机存取内存(SRAM)也将为更多的键值缓存提供空间,从而实现大于10的大批处理大小,并可能大幅降低成本。
分析师认为,这的确是一个有潜力的方向,但实现的可能性不大。
最后,还有一个更为关键的问题,快速响应小型模型推理这个市场到底有多大,以至于值得抛下灵活的GPU不用,转而去构建专门的基础设施。























