介绍
作为数据工程师,我们经常面临这样的情况:我们必须从运营数据库中获取一个特别大的数据集,对其进行一些转换,然后将其写回分析数据库或云对象存储(例如S3桶)。
如果数据集太大无法装入内存,但同时使用分布式计算不值得或不可行,该怎么办呢?
在这种情况下,我们需要找到一种方法,在不影响数据团队其他同事(例如通过使用Airflow实例中可用内存的大部分)的情况下完成工作。这就是Python生成器可能会派上用场的时候,通过避免内存峰值来高效地从数据库获取数据。
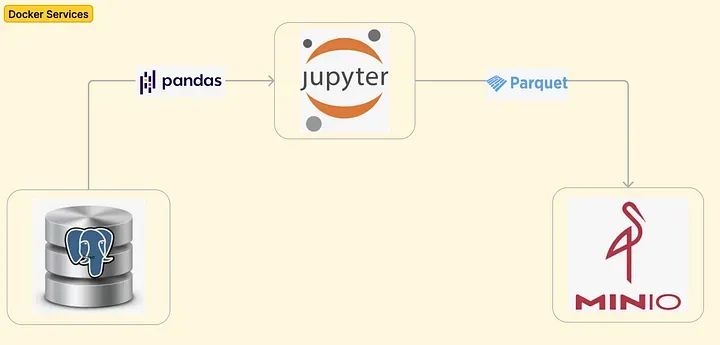
事实上,在本教程中,我们将通过旋转运行三个服务(PostgresDB、Jupyter Notebook和MinIO)的Docker容器来模拟一个真实的端到端数据工作流程,探讨在数据工程师中使用生成器的两个实际用例。

Python中使用生成器的优点
在Python中,标准函数计算并返回单个值然后终止,而生成器可以随时间产生一系列值,根据需要暂停和恢复。生成器是一种特殊的函数,它使用`yield`子句而不是`return`来产生一系列的值。值逐个创建,无需将整个序列存储在内存中。
当调用生成器函数时,它返回一个迭代器对象,可以用于迭代生成器产生的值的序列。例如,让我们创建一个squares_generator(n)函数,该函数生成介于零和输入变量n之间的数字的平方:
def squares_generator(n):
num = 0
while num < n:
yield num * num
num += 1当调用该函数时,它只返回一个迭代器:
squares_generator(n)
#Output:
# <generator object squares_generator at 0x10653bdd0>为了触发整个值序列,我们必须在循环中调用生成器函数:
for num in squares_generator(5):
print(num)
#Output:
0
1
4
9
16另一种更优雅的选择是创建一个生成器表达式,它执行与上述函数相同的操作,但作为一行代码:
n = 5
generator_exp = (num * num for num in range(n))现在,可以直接使用`next()`方法访问值:
print(next(generator_exp)) # 0
print(next(generator_exp)) # 1
print(next(generator_exp)) # 4
print(next(generator_exp)) # 9
print(next(generator_exp)) # 16正如我们所看到的,生成器函数返回值的方式并不像常规Python函数那样直观,这可能是为什么许多数据工程师没有像他们应该的那样经常使用生成器的原因。
目标与设置
本教程的目标是:
- 从Postgres数据库中获取数据并将其存储为pandas数据框。
- 将pandas数据框以parquet格式写入S3桶。
每个目标都将使用常规函数和生成器函数两种方法实现。为了模拟这样的工作流程,我们将使用三个服务旋转一个Docker容器:
- Postgres数据库(这个服务将是我们的源操作数据库,从中获取数据。Docker-compose还涉及创建一个mainDB,以及在名为transactions的表中插入500万个模拟记录。请注意:可以插入任意数量的行来模拟一个更大的数据集(在准备本教程的材料时,尝试过5000万和1亿行),但Docker服务的性能会受到严重影响。)
- MinIO(这个服务将用于模拟AWS S3桶,然后使用awswrangler包帮助将pandas数据框以parquet格式写入其中。)
- Jupyter Notebook(这个服务将用于通过熟悉的编译器以交互方式运行Python片段。)
下面的图表是对到目前为止所描述的内容的可视化表示:
第一步,我们项目的GitHub存储库并切换到相关文件夹:
git clone git@github.com:anbento0490/projects.git &&
cd fetch_data_with_python_generators然后,我们可以运行docker-compose来启动这三个服务:
docker compose up -d
[+] Running 5/5
⠿ Network shared-network Created 0.0s
⠿ Container jupyter-notebooks Started 1.0s
⠿ Container minio Started 0.7s
⠿ Container postgres-db Started 0.9s
⠿ Container mc Started最终,我们可以验证:
(1) 在Postgres数据库中存在一个名为transactions的表,其中包含5百万条记录。
docker exec -it postgres-db /bin/bash
root@9632469c70e0:/# psql -U postgres
psql (13.13 (Debian 13.13-1.pgdg120+1))
Type "help" for help.
postgres=# \c mainDB
You are now connected to database "mainDB" as user "postgres".
mainDB=# select count(*) from transactions;
count
---------
5000000
(1 row)(2) 可以通过端口localhost:9001访问MinIO UI(在要求凭据时插入管理员和密码),并且已经创建了一个名为generators-test-bucket的空桶:
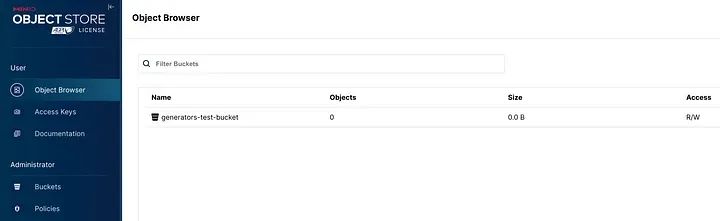
MinIO UI端口9001处的用户界面
(3) 可以通过localhost:8889访问Jupyter Notebook用户界面,并通过以下方法检索令牌:
docker exec -it jupyter-notebooks /bin/bash
root@eae08d1f4bf6:~# jupyter server list
Currently running servers:
http://eae08d1f4bf6:8888/?token=8a45d846d03cf0c0e4584c3b73af86ba5dk9e83c8ac47ee7 :: /home/jovyan
很好!我们已经准备好在Jupyter上运行一些代码了。但在我们这样做之前,我们需要创建一个新的access_key和secret_access_key,以便能够与MinIO桶进行交互:
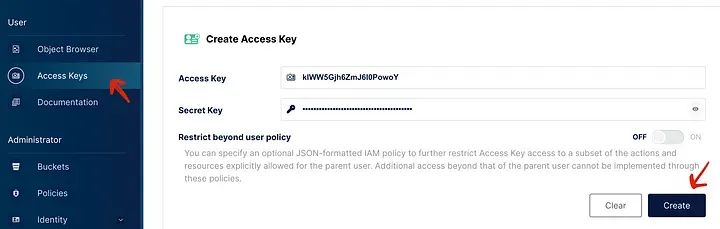
如何在MinIO中生成新的密钥对
注意:MinIO桶的最酷的功能之一是,我们可以与它们交互,就像它们是AWS S3桶一样(例如使用boto3、awswrangler等),但它们是免费的,而且无需担心暴露密钥,因为它们仅存在于我们的本地环境中,并且除非持久保存,否则将在容器停止时被删除。
现在,在生成器笔记本中,让我们运行以下代码(确保替换secrets):
import psycopg2
import pandas as pd
import boto3
import awswrangler as wr
#######################################################
######## CONNECTING TO PG DB + CREATING CURSORS #######
connection = psycopg2.connect(user="postgres",
password="postgres",
port="5432",
database="mainDB")
cursor = connection.cursor()
query = "select * from transactions;"
#######################################################
######## CONNECTING TO MINIO BUCKET ###################
boto3.setup_default_session(aws_access_key_id = 'your_access_key',
aws_secret_access_key = 'your_secret_key')
bucket = 'generators-test-bucket'
folder_gen = 'data_gen'
folder_batch = 'data_batch'
parquet_file_name = 'transactions'
batch_size = 1000000
wr.config.s3_endpoint_url = 'http://minio:9000'这将创建一个连接到mainDB的连接以及用于执行查询的游标。还将设置一个default_session,以与generators-test-bucket进行交互。
用例 #1:从数据库读取数据
作为数据工程师,在将大型数据集从数据库或外部服务抓取到Python管道中时,我们经常需要在以下方面找到合适的平衡:
- 内存:一次性拉取整个数据集可能导致OOM错误或影响整个实例/集群的性能。
- 速度:逐行获取数据也会导致昂贵的I/O网络操作。
方法 #1:使用批处理
一个合理的折衷方案(在实践中经常使用)是以批处理方式获取数据,其中批处理的大小取决于可用内存以及数据管道的速度要求。
# 1.1. CREATE DF USING BATCHES
def create_df_batch(cursor, batch_size):
print('Creating pandas DF using generator...')
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
df = pd.DataFrame(columns=colnames)
cursor.execute(query)
while True:
rows = cursor.fetchmany(batch_size)
if not rows:
break
# some tramsformation
batch_df = pd.DataFrame(data = rows, columns=colnames)
df = pd.concat([df, batch_df], ignore_index=True)
print('DF successfully created!\n')
return df上面的代码执行以下操作:
- 创建一个空的df(数据框);
- 执行查询,将整个结果缓存到游标对象中;
- 初始化一个while循环,每次迭代都获取等于指定batch_size的行数(在此示例中为1百万行),并使用这些数据创建一个batch_df(批数据框)。
- 最终将batch_df附加到主df。该过程重复进行,直到整个数据集被遍历。
让我们明确一下:这只是一个基本示例,我们可以在while循环的一部分执行许多其他操作(过滤、排序、聚合、将数据写入其他位置等),而不仅仅是一次一个批次地创建df。当在笔记本中执行该函数时,我们得到:
%%time
df_batch = create_df_batch(cursor, batch_size)
df_batch.head()
Output:
Creating pandas DF using generator...
DF successfully created!
CPU times: user 9.97 s, sys: 13.7 s, total: 23.7 s
Wall time: 25 s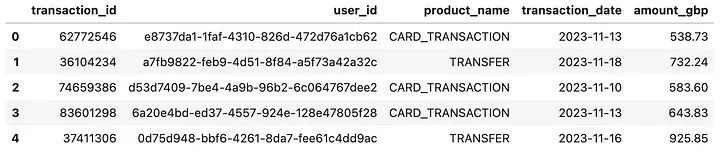
df_batch数据框的前5行
方法 #2:使用生成器
一种不太常见但强大的数据工程师策略是使用生成器以流的形式获取数据:
# AUXILIARY FUNCTION
def generate_dataset(cursor):
cursor.execute(query)
for row in cursor.fetchall():
# some tramsformation
yield row
# 2.1. CREATE DF USING GENERATORS
def create_df_gen(cursor):
print('Creating pandas DF using generator...')
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
df = pd.DataFrame(data = generate_dataset(cursor), columns=colnames)
print('DF successfully created!\n')
return df在上面的代码片段中,我们创建了`generate_dataset` 辅助函数,该函数执行查询,然后将行作为序列生成。该函数直接传递给`pd.DataFrame()` 子句的`data`参数,该子句在背后遍历所有获取的记录,直到行被耗尽。
同样,这个例子非常基础(主要是为了演示目的),但我们可以在辅助函数中执行任何类型的过滤或转换。当执行该函数时,我们得到df_gen数据框的前5行
%%time
df_gen = create_df_gen(cursor)
df_gen.head()
Creating pandas DF using generator...
DF successfully created!
CPU times: user 9.04 s, sys: 2.1 s, total: 11.1 s
Wall time: 14.4 s
看起来似乎两种方法最终都使用了同样的内存量(因为df都是以不同方式返回的),但事实并非如此,因为数据在生成df本身时的处理方式是不同的:
- 对于方法 #1,是急切地获取数据,通过网络进行数据交换有点低效,导致内存占用峰值较高;
- 对于方法 #2,是懒惰地获取数据,只有在需要时才计算,并且逐个计算,从而降低内存占用。
用例 #2:写入云对象存储
有时,数据工程师需要获取存储在数据库中的大量数据,并将这些记录外部共享(例如与监管机构、审计员、合作伙伴共享)。
一种常见的解决方案是创建一个云对象存储,数据将被传递到该存储中,以便第三方(具有适当访问权限的人)能够读取并将数据复制到其系统中。
实际上,我们创建了一个名为`generators-test-bucket`的桶,数据将以parquet格式写入其中,利用了`awswrangler`包。
`awswrangler`的优势在于它与pandas数据框非常有效地配合,并允许以保留数据集结构的方式将它们转换为parquet格式。
方法 #1:使用批处理
与第一个用例一样,一个常见的解决方案是以批处理方式获取数据,然后写入数据,直到整个数据集被遍历:
# 1.2 WRITING DF TO MINIO BUCKET IN PARQUET FORMAT USING BATCHES
def write_df_to_s3_batch(cursor, bucket, folder, parquet_file_name, batch_size):
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
cursor.execute(query)
batch_num = 1
while True:
rows = cursor.fetchmany(batch_size)
if not rows:
break
print(f"Writing DF batch #{batch_num} to S3 bucket...")
wr.s3.to_parquet(df= pd.DataFrame(data = rows, columns=colnames),
path=f's3://{bucket}/{folder}/{parquet_file_name}',
compression='gzip',
mode = 'append',
dataset=True)
print('Batch successfully written to S3 bucket!\n')
batch_num += 1执行`write_df_to_s3_batch()` 函数会在桶中创建五个parquet文件,每个文件包含1百万条记录:
write_df_to_s3_batch(cursor, bucket, folder_batch, parquet_file_name, batch_size)
Writing DF batch #1 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #2 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #3 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #4 to S3 bucket...
Batch successfully written to S3 bucket!
Writing DF batch #5 to S3 bucket...
Batch successfully written to S3 bucket!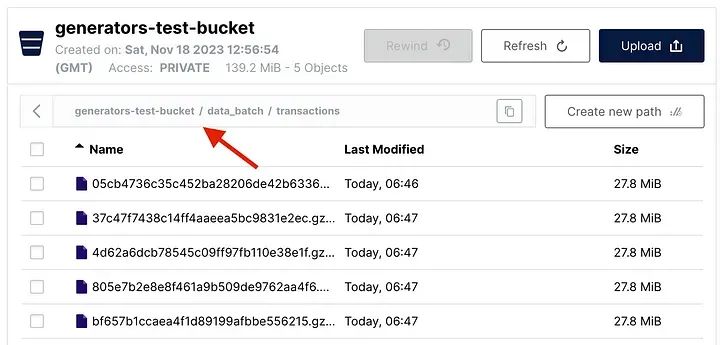
在MinIO中以批处理方式写入的数据
方法 #2:使用生成器
或者,可以通过利用生成器提取数据并将其写入桶中。由于生成器在提取和移动数据时不会导致内存效率问题,我们甚至可以决定一次性写入整个df:
# 2.2 WRITING DF TO MINIO BUCKET IN PARQUET FORMAT USING GENERATORS
def write_df_to_s3_gen(cursor, bucket, folder, parquet_file_name):
print('Writing DF to S3 bucket...')
colnames = ['transaction_id',
'user_id',
'product_name',
'transaction_date',
'amount_gbp']
wr.s3.to_parquet(df= pd.DataFrame(data = generate_dataset(cursor), columns=colnames),
path=f's3://{bucket}/{folder}/{parquet_file_name}',
compression='gzip',
mode = 'append',
dataset=True)
print('Data successfully written to S3 bucket!\n')当执行`write_df_to_s3_gen()` 函数时,将一个包含所有5百万行的唯一较大parquet文件保存到桶中:
write_df_to_s3_gen(cursor, bucket, folder_gen, parquet_file_name)
Writing DF to S3 bucket...
Data successfully written to S3 bucket!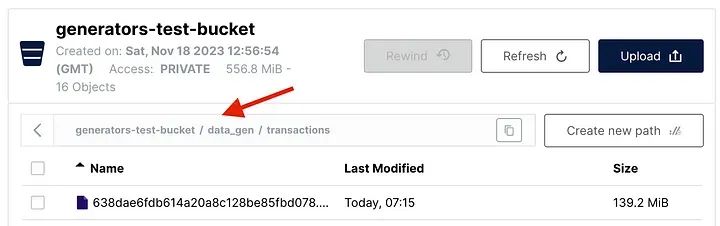
利用生成器写入MinIO的数据