













作者提出了EfficientViT-SAM,这是一系列加速的SAM模型。在保留SAM轻量级的提示编码器和 Mask 解码器的同时,作者用EfficientViT替换了沉重的图像编码器。在训练方面,首先从SAM-ViT-H图像编码器向EfficientViT进行知识蒸馏。随后,在SA-1B数据集上进行端到端的训练。得益于EfficientViT的高效性和容量,EfficientViT-SAM在A100 GPU上实现了48.9的TensorRT速度提升,而且没有牺牲性能。
代码和预训练:https://github.com/mit-han-lab/efficientvit
1 Introduction
Segment Anything Model (SAM) 是一系列在高质量数据集上预训练的图像分割模型,该数据集包含1100万张图片和10亿个 Mask 。SAM 提供了惊人的零样本图像分割性能,并在许多应用中都有用途,包括增强现实/虚拟现实、数据标注、交互式图像编辑等。
尽管性能强大,但SAM的计算量非常大,这在时间敏感的情境中限制了其适用性。特别是,SAM的主要计算瓶颈在于其图像编码器,在推理时每张图像需要2973 GMACs。
为了加速SAM,已经进行了许多尝试,用轻量级模型替换SAM的图像编码器。例如,MobileSAM 将SAM的ViT-H模型的知识蒸馏到一个小型视觉 Transformer 中。EdgeSAM 训练了一个纯基于CNN的模型来模仿ViT-H,并采用了一种细致的蒸馏策略,过程中涉及到提示编码器和 Mask 解码器。EfficientSAM 利用MAE预训练方法来提高性能。
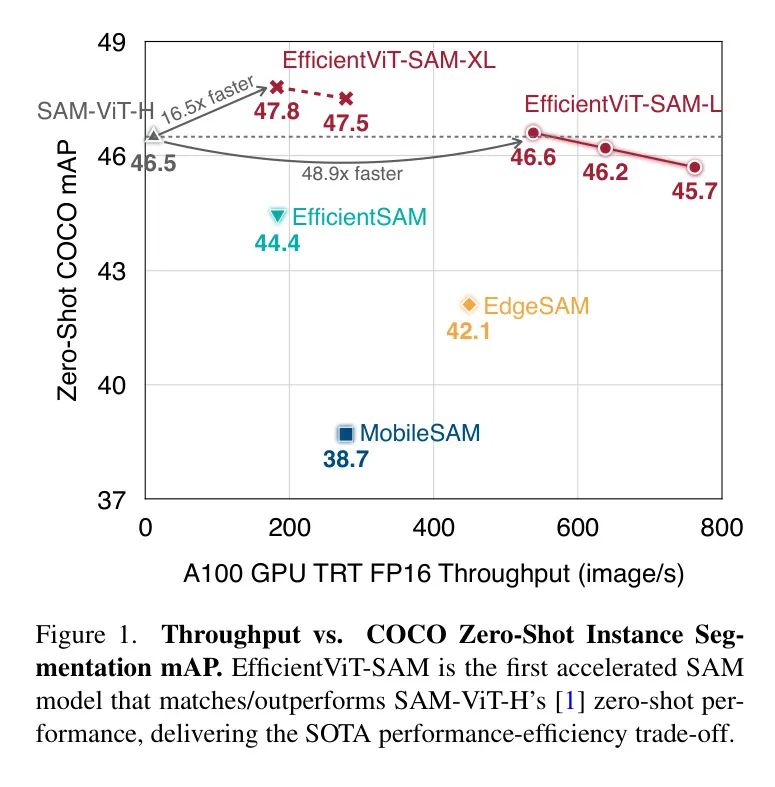
尽管这些方法可以降低计算成本,但它们都存在显著的性能下降(图1)。本文引入了EfficientViT-SAM来解决这一限制,通过利用EfficientViT来替换SAM的图像编码器。同时,作者保留了SAM的轻量级提示编码器和 Mask 解码器架构。作者的训练过程包括两个阶段。首先,作者使用SAM的图像编码器作为教师来训练EfficientViT-SAM的图像编码器。其次,作者使用整个SA-1B数据集端到端地训练EfficientViT-SAM。
作者全面评估了EfficientViT-SAM在一系列零样本基准测试上的表现。EfficientViT-SAM在性能和效率上显著优于所有之前的SAM模型。特别是,在COCO数据集上,与SAM-ViT-H相比,EfficientViT-SAM在A100 GPU上实现了48.9倍的吞吐量提升,而mAP没有下降。
2 Related Work
Segment Anything Model
SAM 在计算机视觉领域已经获得广泛认可,作为该领域的一个里程碑,它在图像分割方面展示了卓越的性能和泛化能力。SAM 将图像分割定义为可提示的任务,旨在给定任何分割提示时生成有效的分割 Mask 。为了实现这一目标,SAM 使用图像编码器和提示编码器来处理图像并提供提示。两个编码器的输出随后被送入 Mask 解码器,该解码器生成最终的 Mask 预测。
SAM 在一个大规模的分割数据集上进行训练,该数据集包含超过1100万张图像和超过10亿个高质量 Mask ,这使得它能够在零样本开放世界分割中表现出强大的能力。SAM 在各种下游应用中展示了其高度的适应性,包括图像修复、目标跟踪和3D生成。然而,SAM的图像编码器组件带来了显著的计算成本,导致高延迟,限制了在时间敏感场景中的实用性。最近的工作集中在提高SAM的效率,旨在解决其计算限制。
Efficient Deep Learning Computing
提高深度神经网络的效率在边缘和云计算平台上的实际应用中至关重要。作者的工作与有效的模型架构设计相关,旨在通过用高效的模型架构替换低效的模型架构来改善性能与效率之间的权衡。作者的工作还与知识蒸馏相关,该方法利用预训练的教师模型指导学生模型的训练。此外,作者可以将EfficientViT-SAM与其他并行技术结合,以进一步提高效率,包括剪枝、量化和硬件感知神经架构搜索。
3 Method
作者提出了EfficientViT-SAM,该方法利用EfficientViT来加速SAM。特别是,EfficientViT-SAM保留了SAM的提示编码器和 Mask 解码器架构,同时用EfficientViT替换了图像编码器。作者设计了两系列模型,EfficientViT-SAM-L和EfficientViT-SAM-XL,它们在速度和性能之间提供了平衡。随后,作者以端到端的方式使用SA-1B数据集来训练EfficientViT-SAM。
EfficientViT
EfficientViT 是一系列用于高效高分辨率密集预测的视觉 Transformer 模型。其核心构建模块是一个多尺度线性注意力模块,它通过硬件高效的运算实现了全局感受野和多尺度学习。
具体来说,它用轻量级的ReLU线性注意力替代了效率低下的softmax注意力,以拥有全局感受野。通过利用矩阵乘法的结合性质,ReLU线性注意力可以在保持功能的同时,将计算复杂度从二次降低到一次。此外,它还通过卷积增强了ReLU线性注意力,以减轻其在局部特征提取上的局限性。更多细节可在原论文中找到。
EfficientViT-SAM
模型架构。EfficientViT-SAM-XL的宏观架构如图2所示。其主干包含五个阶段。类似于EfficientViT,作者在早期阶段使用卷积块,而在最后两个阶段使用efficientViT模块。作者通过上采样和加法融合最后三个阶段的特征。融合后的特征被送入由几个融合的MBConv块组成的 Neck ,然后送入SAM Head 。

训练。为了初始化图像编码器,作者首先将SAM-ViT-H的图像嵌入信息蒸馏到EfficientViT中。作者采用L2损失作为损失函数。对于提示编码器和 Mask 解码器,作者通过加载SAM-ViT-H的权重来初始化它们。然后,作者以端到端的方式在SA-1B数据集上训练EfficientViT-SAM。
在端到端的训练阶段,作者以相等的概率随机选择框提示和点提示。在点提示的情况下,作者从真实 Mask 中随机选择1-10个前景点,以确保作者的模型能够有效应对各种点配置。在框提示的情况下,作者使用真实边界框。对于EfficientViT-SAM-L/XL模型,作者将最长边调整至512/1024,并相应地填充较短边。作者每张图像选择多达64个随机采样的 Mask 。
为了监督训练过程,作者使用Focal Loss和骰子损失的线性组合,Focal Loss与骰子损失的比例为20:1。类似于SAM中采用的消除歧义的方法,作者同时预测三个 Mask ,并且只反向传播损失最低的那个。作者还通过添加第四个输出Token来支持单一 Mask 的输出。在训练期间,作者随机交替使用两种预测模式。
作者使用SA-1B数据集对EfficientViT-SAM进行了2个周期的训练,批量大小为256。采用AdamW优化器,动量参数设为0.9,设为0.999。初始学习率对于EfficientViT-SAM-L/XL分别设定为2e/1e,并使用余弦衰减学习率计划将其降低至0。在数据增强方面,作者应用了随机水平翻转。
4 Experiment
在本节中,作者在4.1节中对EfficientViT-SAM的运行时效率进行了全面分析。随后,作者在COCO 和 LVIS 数据集上评估了EfficientViT-SAM的零样本能力,这些数据集在训练过程中未曾遇到。作者执行了两项不同的任务:4.2节中的单点有效 Mask 评估以及4.3节中的边界框提示实例分割。这些任务分别评估了EfficientViT-SAM的点提示和边界框提示特征的有效性。此外,作者在4.4节还提供了SGlnW基准测试的结果。
Runtime Efficiency
作者比较了EfficientViT-SAM与SAM及其他加速工作的模型参数、MACs和吞吐量。结果展示在表1中。作者在单个NVIDIA A100 GPU上进行了吞吐量的测量,并使用了TensorRT优化。
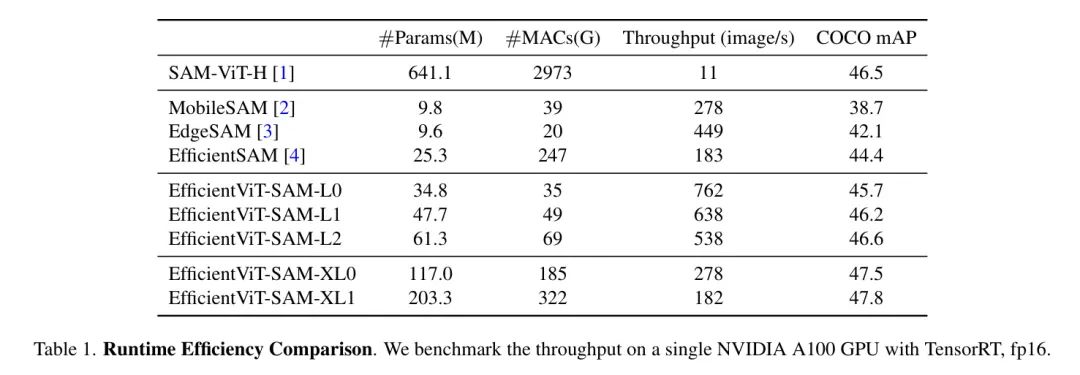
作者的结果显示,与SAM相比,作者实现了令人印象深刻的17到69倍的加速。此外,尽管EfficientViT-SAM的参数数量多于其他加速工作,但由于其有效地利用了硬件友好的运算符,因此其吞吐量显著提高。
Zero-Shot Point-Prompted Segmentation
作者在表2中评估了基于点提示对目标进行分割时EfficientViT-SAM的零样本性能。作者采用了文献[1]中描述的点选择方法。即初始点被选为距离目标边界最远的点。后续的每个点都选为距离错误区域边界最远的点,该错误区域被定义为真实值和先前预测之间的区域。
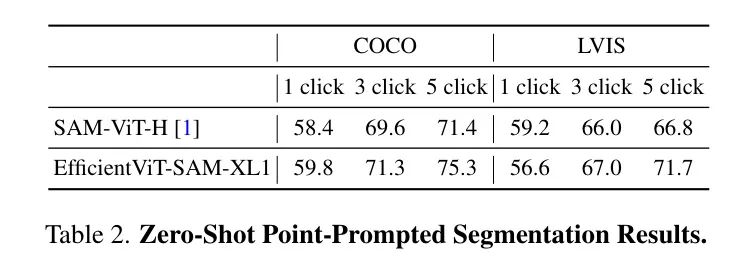
作者在COCO和LVIS数据集上使用1/3/5次点击报告性能,以mIoU(平均交并比)作为评价指标。作者的结果显示,与SAM相比,性能更优,尤其是在提供额外点提示时。
Zero-Shot Box-Prompted Segmentation
作者评估了EfficientViT-SAM在利用边界框进行目标分割中的零样本性能。首先,作者将真实边界框输入到模型中,结果展示在表4中。
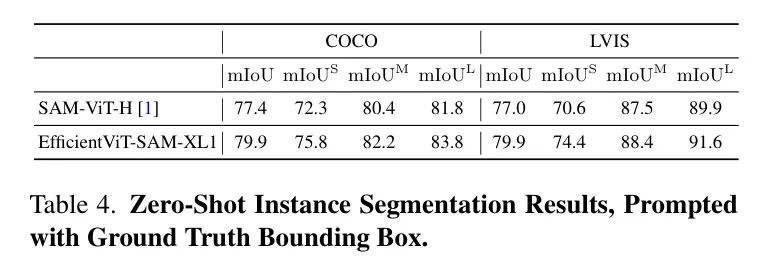
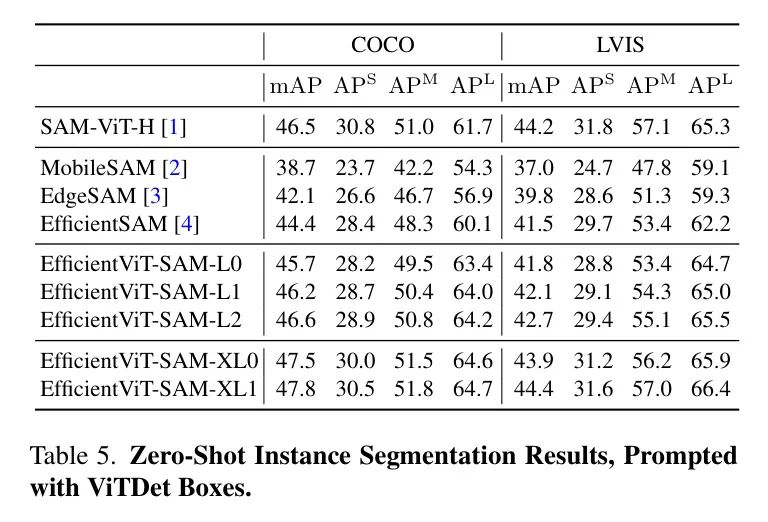
所有目标都报告了mIoU(平均交并比),并且分别为小型、中型和大型目标分别报告。EfficientViT-SAM在COCO和LVIS数据集上显著超过了SAM。接下来,作者采用一个目标检测器ViT-Det,并使用其输出框作为模型的提示。表5的结果显示,EfficientViT-SAM相比于SAM取得了更优的性能。值得注意的是,即使是EfficientViT-SAM的最轻版本,也显著优于其他加速工作。
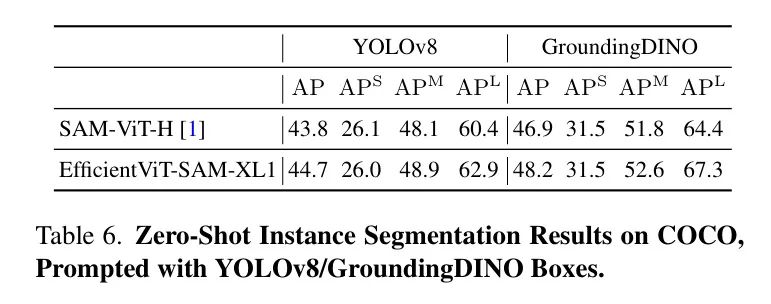
另外,作者使用YOLOv8和GroundingDINO 作为目标检测器,在COCO数据集上评估了EfficientViT-SAM的性能。YOLOv8是一种实时目标检测器,适用于实际应用场景。另一方面,GroundingDINO能够使用文本提示来检测目标,这使得作者可以基于文本线索进行目标分割。表6中展示的结果表明,EfficientViT-SAM相比于SAM具有卓越的性能。
Zero-Shot In-the-Wild Segmentation
野外分割基准包含25个零样本野外分割数据集。作者将EfficientViT-SAM与Grounding-DINO结合,作为框提示,执行零样本分割。每个数据集的全面性能结果在表3中展示。SAM达到48.7的mAP,而EfficientViT-SAM获得了更高的48.9分。
Qualitative Results.
图3展示了当提供点提示、框提示以及SAM模式时,EfficientViT-SAM的定性分割结果。结果显示,EfficientViT-SAM不仅在分割大型物体上表现出色,也能有效处理小型物体。这些发现强调了EfficientViT-SAM卓越的分割能力。

5 Conclusion
在这项工作中,作者引入了EfficientViT-SAM,它使用EfficientViT来替代SAM的图像编码器。EfficientViT-SAM在无需牺牲各种零样本分割任务性能的情况下,显著提高了SAM的效率。























