译者 | 李睿
审校 | 重楼
对于入门的开发人员来说,虽然克服了最初的障碍,学会了编程,找到了理想的工作。但其编程旅程并没有就此结束。他们面临真正的挑战:如何编写更好的代码。这不仅仅是为了完善功能,还要编写出经得起时间考验的优雅、可维护的代码。

在设计糟糕的软件系统中,开发人员在后台就像迷失在一个没有地图导航的城市里一样。这些系统往往笨重、低效且令人沮丧。
开发人员可以通过设计更好的以用户为中心、高效、简单、灵活的系统来改变这种状况。他们可以使用函数、变量、类和注释来编写“不要重复自己”(DRY)和模块化的代码,设计为人们服务的系统,而不是相反。
因此开发人员的选择是明确的:编写赋能的代码而不是阻碍的代码,构建让开发人员茁壮成长的代码体系。
代码库的挑战
想象一下,如果你是一名销售主管,采用了一款新的应用程序,旨在简化工作流程,并最大限度地提高潜在客户的转化率。这款应用程序由SmartReach API提供支持,可以实时了解潜在客户,并有可能获得奖励。
但感觉这款应用程序有些问题,其代码缺乏清晰度和结构,引起了人们对其准确性和功能的担忧。分析代码变成了一项令人困惑的任务,阻碍了有效使用应用程序的能力。
与其纠结于晦涩难懂的代码行,不如以一种清晰而结构化的方式来分解代码。这将使开发人员能够识别潜在的错误,并确保应用程序顺利运行,最大限度地提高生产力和获得奖励的潜力。
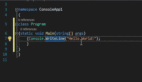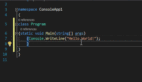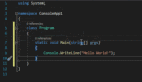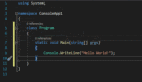
class ApiCall {
def getData(pn: Int, v: Int) = Action.async(parse.json) { request =>
ws.url(s"https://api.smartreach.io/api/v$v/prospects?page=$pn")
.addHttpHeaders(
"X-API-KEY" -> "API_KEY"
)
.get()
.flatMap(r => {
if (r.status == 200) {
Res.Success("Success!", (response.json \ "data").as[JsValue])
} else {
Res.ServerError("Error!",new Exception((response.json \ "message").as[String]))
}
})
}
}我们将重构一个用Scala编写但适用于一般编码的示例销售应用程序。那么目标是什么?是将令人头疼的混乱代码变成一部清晰可读的杰作。
以下分解重构过程,解释每个步骤并展示其积极影响。让我们一起创造激励和赋能的代码!
代码重构
命名约定和代码注释
如今,我们都在关注快速消息,但在编写代码时,这并不奏效。
为变量、类、函数和对象等使用清晰的名称是非常重要的。如果让同事帮助检查或修改代码,别忘了在代码中编写一些注释。这可能看起来没什么大不了的,但当你或你的同事试图解决出现的代码问题时,这些注释将提供很大的帮助。
让我们看看遵循这些规则之后编写代码的结果:
class ProspectsApiGet {
def getProspectListFromSmartReach(
page_number: Int,
version: Int
) = Action.async(parse.json) { request =>
//public API of SmartReach to get the prospect list by page number
//smartreach.io/api_docs#get-prospects
ws.url(s"https://api.smartreach.io/api/v$version/prospects?page=$page_number")
.addHttpHeaders(
"X-API-KEY" -> "API_KEY"
)
.get()
.flatMap(response => {
val status = response.status
if (status == 200) {
//if the API call to SmartReach was success
/*
{
"status": string,
"message": string,
"data": {
"prospects": [*List of prospects*]
}
}
*/
val prospectList: List[JsValue] = (response.json \ "data" \\ "prospects").as[List[JsValue]]
Res.Success("Success!", prospectList)
} else {
// error message
//smartreach.io/api_docs#errors
val errorMessage: Exception = new Exception((response.json \ "message").as[String])
Res.ServerError("Error", errorMessage) // sending error
}
})
}
}如果仔细观察,错误就会隐藏在代码中! 对潜在客户的分析不太正确。但是,通过提供更多的注释和使用更好的名称,可以避免这些错误。
代码库组织和模块化
直到现在都一切顺利。编写的代码很好,应用程序也很简单。既然代码运行良好并且更易于阅读,那么让我们来处理下一个挑战。
考虑在这里引入一个筛选系统。这会让事情变得更加复杂。我们真正需要的是一个更有组织的代码结构。
为了使其实现模块化,我们将代码分成更小的模块。但是如何确定每个模块的位置呢?
(1)目录结构
目录是代码的总部,本质上是一个将所有内容放在一起的文件夹。如果创建一个新文件夹,这样就有了一个目录。
在这个目录中,可以存储代码文件或创建其他子目录。在我们的例子中则选择子目录。将代码分成四个部分:模型、数据访问对象(DAO)、服务和控制器。
值得注意的是,目录结构可能会根据企业偏好或应用程序的特定需求而有所不同。你可以根据最适合企业或应用的内容来定制。
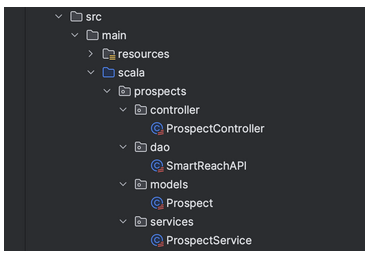
(2)模型
当我们谈论编码中的模型时,本质上是在谈论用来构建和管理数据的框架。例如在这个例子的场景中,前景模型充当了蓝图,概述了代表系统内前景的特定特征和行为。
在这个模型中,我们定义了潜在客户拥有的属性——可能是姓名、联系方式或任何其他相关信息。这不仅仅是存储数据,还是有关以一种对应用程序有效地交互和操作有意义的组织方式。
case class SmartReachProspect(
sr_prospect_id: Long, //id of the prospect in SmartReach database
p_first_name: String,
p_last_name: String,
p_email: String,
p_company: String,
p_city: String,
p_country: String,
smartreach_prospect_category: String // Prospect category in SmartReach
// can be "interested", "not_interested", "not_now", "do_not_contact" etc
)(3)数据访问对象(DAO)
这个对象被恰当地命名为数据访问对象(DAO),充当从数据库或第三方API获取数据的桥梁。
避免在这些文件中添加复杂的逻辑是至关重要的;它们应该只专注于处理输入和输出操作。当我们谈论IO操作时,指的是与外部系统的交互,其中故障的可能性更高。因此,在这里实现保障措施对于处理意外问题至关重要。
在Scala编程语言中,我们利用Monad(特别是Futures)来有效地管理和处理潜在的故障。这些工具有助于捕获和管理IO操作过程中可能发生的故障。
数据访问对象(DAO)的主要目标是从数据源检索数据,然后将其组织到适当的模型中,以便进一步处理和利用。
class SmartReachAPIService {
def getSmartReachProspects(
page_number: Int,
Version: Int
)(implicit ws: WSClient,ec: ExecutionContext): Future[List[SmartReachProspect]] = {
//public API from SmartReach to get the prospects by page number
//smartreach.io/api_docs#get-prospects
ws.url(s"https://api.smartreach.io/api/v$version/prospects?page=$page_number")
.addHttpHeaders(
"X-API-KEY" -> "API_KEY"
)
.get()
.flatMap(response => {
val status = response.status
if (status == 200) {
//checking if the API call to SmartReach was success
/*
{
"status": string,
"message": string,
"data": {
"prospects": [*List of prospects*]
}
}
*/
val prospects: List[SmartReachProspect] = (response.json \ "data" \\ "prospects").as[List[SmartReachProspect]]
prospects
} else {
//error message
//smartreach.io/api_docs#errors
val errorMessage: Exception = new Exception((response.json \ "message").as[String])
throw errorMessage
}
})
}
}(4)服务
这里是我们系统的核心——业务逻辑位于这一层。在这里将实现一种筛选机制,展示如何毫不费力地在这部分代码库中引入额外的功能。
这个部分编排驱动应用程序的核心操作和规则。在这里,根据业务需求定义应该如何处理、操作和转换数据。让添加新特性或逻辑变得相对简单,可以轻松地扩展和增强系统的功能。
class SRProspectService {
val smartReachAPIService = new SmartReachAPIService
def filterOnlyInterestedProspects(
prospects: List[SmartReachProspect]
): List[SmartReachProspect] = {
prospects.filter(p => p.prospect_category == "interested")
}
def getInterestedProspects(
page_number: Int,
version: Int
)(implicit ws: WSClient,ec: ExecutionContext): Future[List[SmartReachProspect]] = {
val allProspects: Future[List[SmartReachProspect]] = smartReachAPIService.getSmartReachProspects(page_number = page_number, version = version)
allProspects.map{list_of_prospects =>
filterOnlyInterestedProspects(prospects = list_of_prospects)
}
}
}(5)控制器
在这一层,我们与API建立直接连接——这一层充当网关。
它充当接口,通过我们的API接收来自前端或第三方用户的请求。在接到这些请求之后,收集所有必要的数据,并在处理后处理响应。
保持关注点分离是至关重要的。因此避免在这个层中实现逻辑。与其相反,该层侧重于管理传入请求流,并将它们引导到实际处理和业务逻辑发生的适当服务层。
class ProspectController {
val prospectService = new SRProspectService
def getInterestedProspects(
page_number: Int
) = Action.async(parse.json) { request =>
prospectService
.getInterestedProspects(page_number = page_number, version = 1)
.map{ intrested_prospects =>
Res.Success("Success", intrested_prospects)
}
.recover{ errorMessage =>
Res.ServerError("Error", errorMessage) // sending error to front end
}
}
}我们改进的代码库具有更高的清洁度和更强的可管理性,促进了更高效的重构工作。
此外,我们还建立了不同的标记,用于合并逻辑、执行数据库操作或无缝集成新颖的第三方API。这些清晰的划分简化了在系统中扩展功能和适应未来增强的过程。
测试和质量保证
测试可能看起来是重复的,但它的重要性怎么强调都不为过,尤其是在熟练使用的情况下,无需为重新编码而烦恼。
让我们更深入地了解构建健壮Spec文件的指导原则。
1.覆盖是关键:在为特定函数构建规范时,确保这些规范涉及该函数中的每一行代码是至关重要的。实现全面覆盖保证了在测试过程中对功能内的所有路径和场景进行仔细检查。
2.失败优先测试:Spec文件的主要作用是检查代码在不同情况下的行为。为了实现这一点,包含一系列测试用例是至关重要的,尤其是那些模拟潜在故障场景的测试用例。确保可靠的错误处理需要对所有可预见的故障实例进行测试。
3.接受集成测试:虽然单元测试擅长于评估代码的逻辑方面,但它们可能会无意中忽略与输入/输出操作相关的潜在问题。为了解决这个问题,集成和执行彻底的集成测试变得必不可少。这些测试模拟真实世界的场景,验证代码在与外部系统或资源交互时的行为。
协作与团队合作
有一条要记住的黄金法则:在遇到难以解决的问题时,可以寻求他人帮助。他人的帮助对于你自身能力实现指数增长至关重要。
创建一个健壮的代码库不是一项单独的任务,而是需要团队的努力。尽管开发人员的职业表面上看起来是内向的,但协作构成了编码的支柱。这种合作超越了企业的界限。
GitHub、LeetCode和StackOverflow等平台展示了编码社区的活跃和社交性质。如果你遇到一个以前没有遇到的问题,很可能别人也遇到过。因此请始终对寻求帮助持开放态度。
代码文档的最佳实践
无论是公共API还是内部代码,可靠的文档是游戏规则的改变者。不过,现在将重点放在了编码方面。
确保一流的文档实践不仅仅是为了简化开发人员的入职过程,而是为了向开发团队提供一个对代码库有清晰见解的宝库。这种清晰性推动了学习,使每个参与者都受益。
预先编码和研究
这是启动项目的所有要素的起点——从系统设计到指向相关文档的关键链接。
在预编码文档中,开发人员不仅可以找到新的表结构和修改,还可以找到指向第三方文档的有价值的链接。需要记住的是,充分的准备为成功奠定了基础,将会事半功倍!
编码期间
这是开发人员在代码中嵌入注释的地方。这些注释作为指南,揭示了代码功能背后的复杂性和意图。
事后编码
这是有效利用代码的指导中心,也是将来修改代码的指南。它是引导用户使用代码的指南,并概述了后续修改代码的路径。
结论
优秀的代码遵循可靠的命名约定,保持模块化,遵循“不要重复自己”(DRY)原则,确保可读性,并经过彻底的测试。编写这样的代码需要混合文档、协作以及为编码人员提供帮助。
文章标题:Tired of Messy Code? Master the Art of Writing Clean Codebases,作者:Upasana Sahu