













离职OpenAI的技术大神karpathy,终于上线了2小时的AI大课。
——「让我们构建GPT Tokenizer(分词器)」。

其实,早在新课推出两天前,karpathy在更新的GitHub项目中,就预告了这件事。

这个项目是minbpe——专为LLM分词中常用的BPE(字节对编码)算法创建最少、干净以及教育性的代码。
目前,GitHub已经狂揽6.1k星,442个fork。
 项目地址:https://github.com/karpathy/minbpe
项目地址:https://github.com/karpathy/minbpe
网友:2小时课程含金量,相当于大学4年
不得不说,karpathy新课发布依然吸引了业内一大波学者的关注。
他总是可以把相当复杂的LLM概念,用非常好理解的方式讲出来。
有网友直接取消了晚上的约会,去上课了。

与karpathy的约会之夜。
AI机器学习研究员Sebastian Raschka表示,「我喜欢从头开始的实现,我真的很期待看到这个视频」!

英伟达高级科学家Jim Fan表示,「Andrej的大脑是一个大模型,它能将复杂的事物标记化为简单的token,让我们小型思维语言模型可以理解。

还有UCSC的助理教授Xin Eric Wang表示,「就个人而言,我非常欣赏他多年前发表的关于RL的文章:http://karpathy.github.io/2016/05/31/rl/,这篇文章帮助我进入了RL领域」。

还有人直言这两个小时课程的含金量,堪比4年制大学学位。

「Andrej是最好的AI老师」。

为什么是分词器?
为什么要讲分词器?以及分词器为什么这么重要?
正如karpathy所言,分词器(Tokenizer)是大模型pipeline中一个完全独立的阶段。
它们有自己的训练集、算法(字节对编码BPE),并在训练后实现两个功能:从字符串编码到token,以及从token解码回字符串。

另外,大模型中许多怪异行为和问题,其实都可以追溯到分词器。
就比如:
- 为什么LLM拼不出单词?
- 为什么LLM无法完成超级简单的字符串处理任务,比如反转字符串?
- 为什么LLM不擅长非英语语言方面的任务?
- 为什么LLM不擅长简单算术?
- 为什么GPT-2在用Python编码时遇到了超出必要的麻烦?
- 为什么LLM在看到字符串<lendoftextl>时突然停止?
- 为什么大模型实际上并不是端到端的语言建模
......

视频中,他将讨论许多这样的问题。讨论为什么分词器是错误的,以及为什么有人理想地找到一种方法来完全删除这个阶段。
两小时大课走起
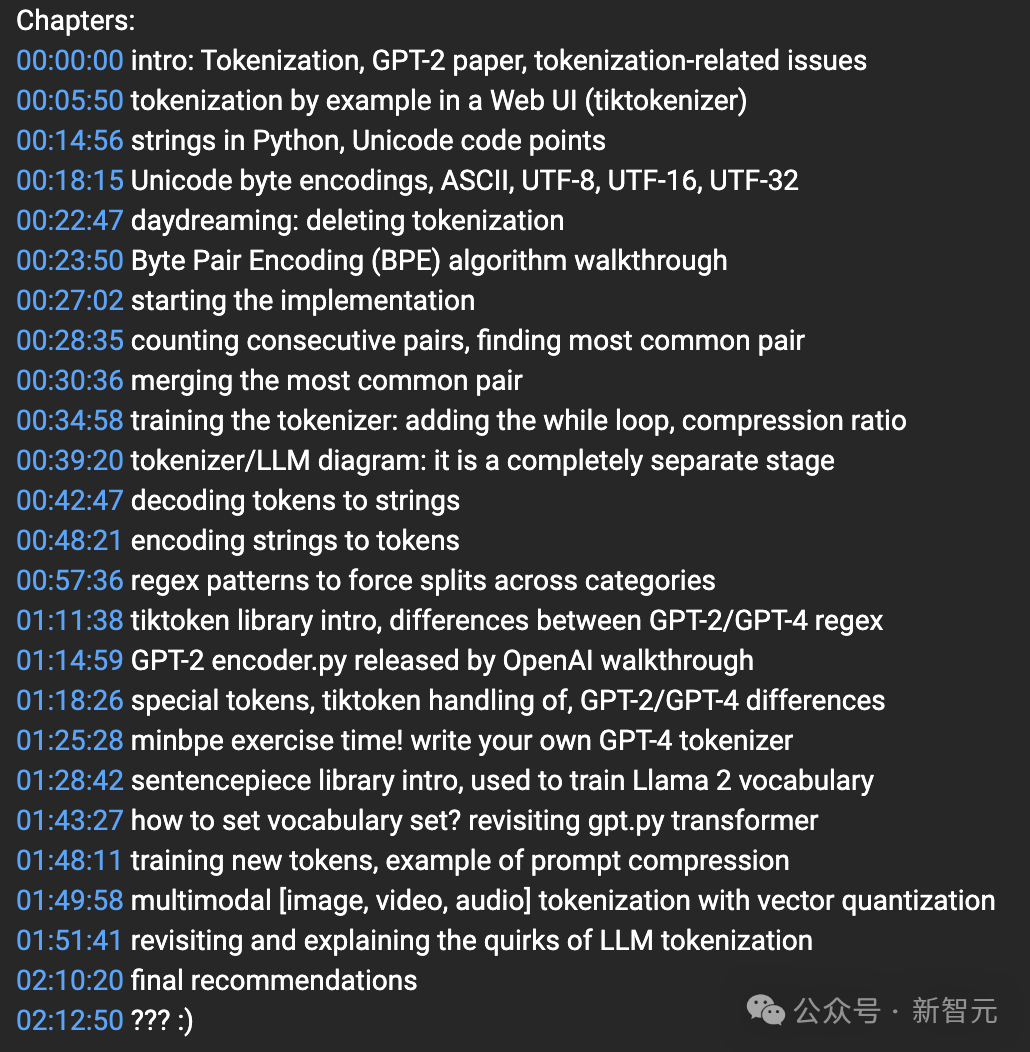
在本讲座中,他将从头开始构建OpenAI GPT系列中使用的Tokenizer。
根据YouTube课程章节介绍,一共有20多个part。
其中包括引言介绍、字节对编码 (BPE) 算法演练、分词器/LLM 图:这是一个完全独立的阶段、minbpe练习时间!编写自己的GPT-4分词器等等。
从讲解到习题演练贯穿了全部课程。
以下是从演讲内容中总结的部分要点。
在视频结尾,Karpathy重新回顾了LLM分词器带来的怪异问题。
首先,为什么LLM又时拼不正确词,或者做不了其他与拼写相关的任务?
从根本上说,这是因为我们看到这些字符被分割成了一个个token,其中有些token实际上相当长。
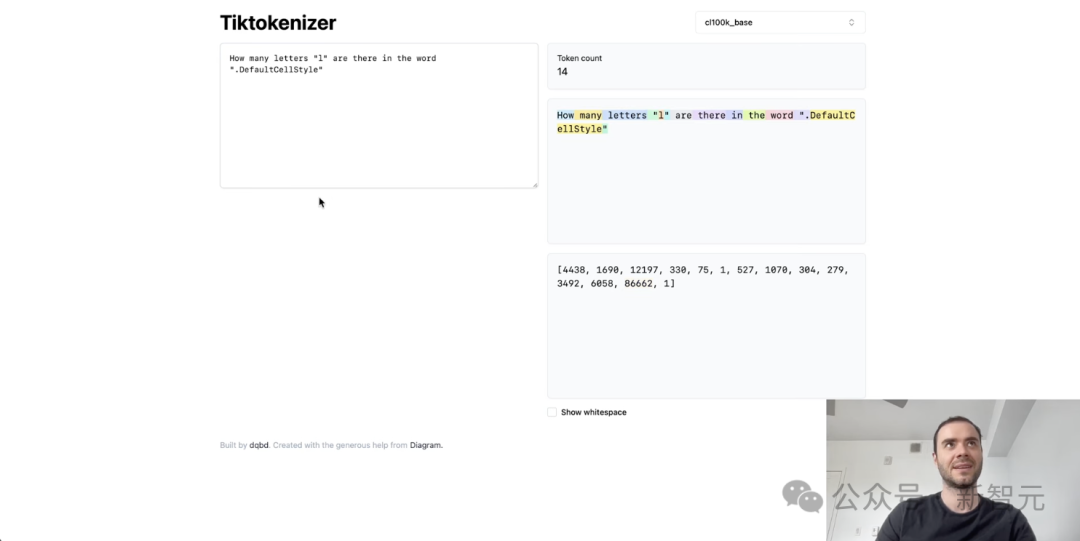
因此,我怀疑这个单个token中塞进了太多的字符,而且我怀疑该模型在与拼写这个单个token相关的任务方面应该不是很擅长。
当然,我的提示是故意这样做的,你可以看到默认风格将是一个单一的token,所以这就是模型所看到的。
事实上,分词器不知道有多少个字母。

那么,为什么大模型在非英语任务中的表现更差?
这不仅是因为LLM在训练模型参数时,看到的非英语数据较少,还因为分词器没有在非英语数据上得到充分的训练。
就比如,这里「hello how are you」是5个token,而它的翻译是15个token,相当与原始的3倍大。
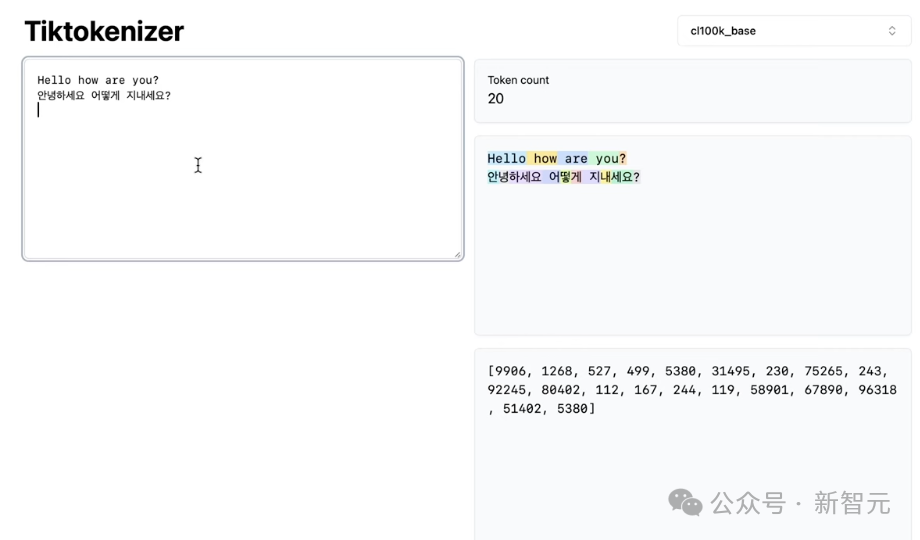
「안녕하세요」在韩语中代表着「你好」,但最终只有3个token。
事实上,我对此感到有点惊讶,因为这是一个非常常见的短语,只是典型的问候语,如你好,最终是三个token。
而英语中的「你好」是一个单一的token。这是我认为LLM在非英语任务中表现差的原因之一便是分词器。
另外,为什么LLM会在简单的算术上栽跟头,也是与数字的token有关。
比如一个类似于字符级别的算法来进行加法,我们先会把一加起来,然后把十加起来,再把百加起来。
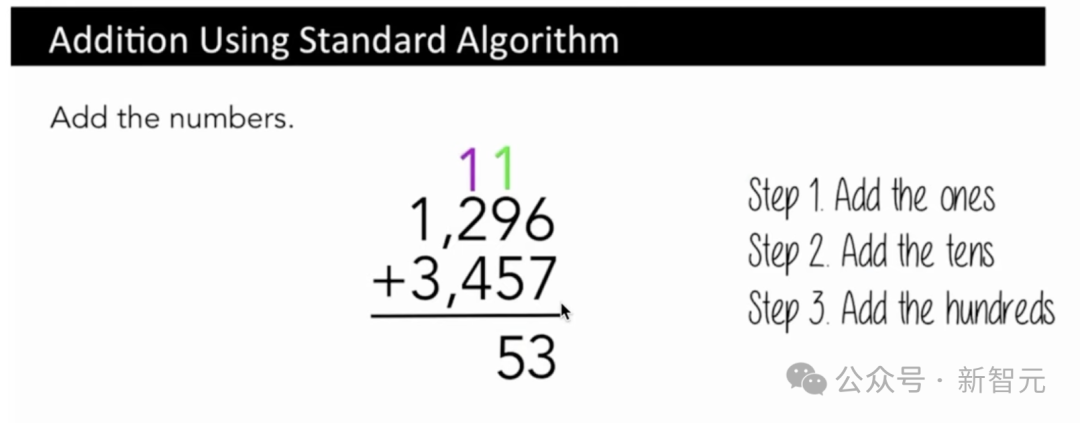
你必须参考这些数字的特定部分,但这些数字的表示完全是任意的,主要是基于在分词过程中发生的合并或不合并。
你可以看看,它是一个单一的token,还是2个token,即1-3、2-2、3-1的组合。
因此,所有不同的数字,都是不同的组合。
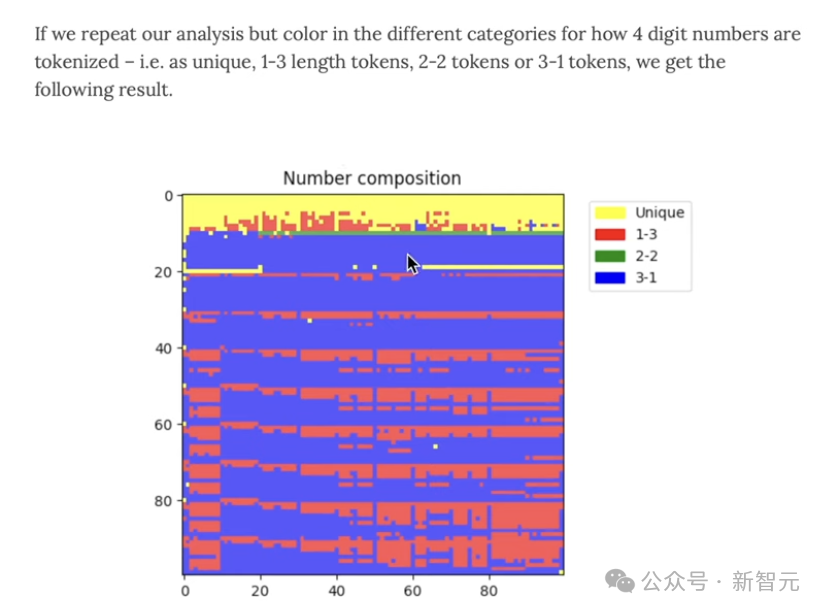
不幸的是,有时我们会看到所有四位数字的四个token,有时是三个,有时是两个,有时是一个,而且是以任意的方式。
但这也并不理想。
所以这就是为什么我们会看到,比如说,当训练Llama 2算法时,作者使用句子片段时,他们会确保把所有的数字都分割开来,作为Llama 2的一个例子,这部分是为了提高简单算术的性能。
最后,为什么GPT-2在Python中的表现不佳,一部分是关于架构、数据集和模型强度方面的建模问题。
但也有部分原因是分词器的问题,可以在Python的简单示例中看到,分词器处理空格的编码效率非常糟糕。
每个空格都是一个单独的token,这大大降低了模型可以处理交叉的上下文长度,所以这几乎是GPT-2分词的错误,后来在GPT-4中得到了修复。

课后习题
在课程下方,karpathy还给在线的网友们布置了课后习题。
快来打卡吧。
























