












作者 | 汪昊
审校 | 重楼
推荐系统诞生于1992 年的一篇论文。自推荐系统诞生以来,无数的科学家和工程师为这一领域倾注了心血。在过去32 年里,许多大学成立了研究推荐系统的研究组(比如科罗拉多大学的THAT 组),而各种各样的公司(百度、字节跳动等)也充分利用了推荐系统的获客属性,实现了低成本高收益的引流渠道。据报道,推荐系统能够帮助大型网站实现30% 到40% 的流量提升。据咨询公司Modor Intelligence 预测, 2024 年推荐系统的世界市场份额会达到500 亿元人民币以上。

目前,全世界推荐引擎增长最快的地区是亚太地区,而推荐系统的主要玩家都是大规模的云计算公司和老牌巨头企业。在过去几年中,没有哪家创业公司能够快速发展,吃掉大公司的市场份额。因此,我们可以初步认为,推荐系统在全球范围内的发展已经进入了稳定期。
2017 年以来,越来越多的专家关注到了推荐系统算法性能之外的问题,特别是推荐系统的公平性。然而有一个非常棘手的问题,推荐专家们一直没能很好的解决。那就是推荐系统的冷启动问题。在没有数据的情况下,我们该怎么解决推荐的难题?为了介绍相关知识,我们先介绍一下零样本学习的发展历程。零样本学习发端自21 世纪的头十年,然而过去20 年的零样本算法,基本都需要迁移学习或者元学习,没有一个算法能成为真正的零样本学习。这一状况一直等到了2021 年ZeroMat 被发明出来后才得以改变(ZeroMat 的源代码地址:https://github.com/haow85/ZeroMat),后续陆陆续续有新的零样本算法出现,让人们意识到即便不使用任何数据,我们也可以把推荐做的很好。
2023 年 Ratidar Technologies LLC 公司 (公司官网:http://ratidar.mysxl.cn)推出了一款不需要数据的推荐系统算法 LogitMat(论文下载地址:https://arxiv.org/ftp/arxiv/papers/2307/2307.05680.pdf)。该算法利用了逻辑回归和矩阵分解结合的方式,在不使用输入数据的情况下,完美地完成了推荐的任务。下面我们来看一下这个算法的细节:
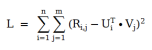
上面这个公式是矩阵分解的损失函数。简单来说,就是我们需要计算出用户特征向量 U 和物品特征向量V, 以便使得他们的点乘和用户评分的差值最小。可以看出来,矩阵分解算法本质上是一个降维算法。我们利用向量点乘将用户评分矩阵的O(mn) 空间复杂度降为 O(k(m+n)),其中m 是用户数、n 是物品数、k 是向量长度。通常k 远小于m 或 n ,因此矩阵分解算法有效的降低了算法的空间复杂度。
我们发现电影评分服从幂律分布,因此我们可以用评分值本身来替换评分的分布。如果我们用逻辑回归来表示评分的分布,也就等价于用逻辑回归来计算评分值。我们得到下面的公式:
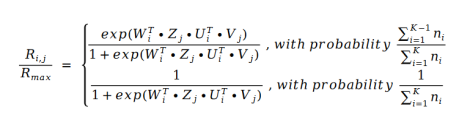
其中 U 和 V 就是矩阵分解中的 U 和 V,而 W 和Z 是系数。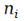 的值就是下标I 本身。那么我们把这个公式带入到矩阵分解的损失函数公式中去,得到下面的损失函数公式:
的值就是下标I 本身。那么我们把这个公式带入到矩阵分解的损失函数公式中去,得到下面的损失函数公式:
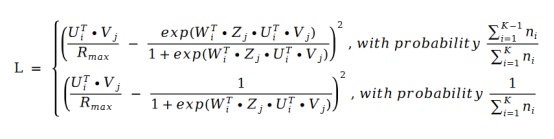
利用随机梯度下降对该损失函数求导。我们得到了如下的公式:
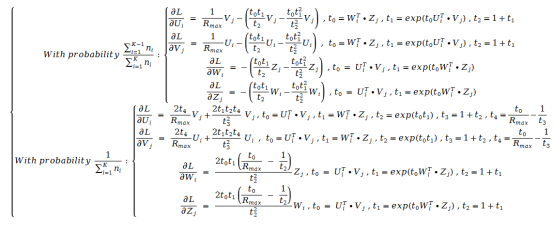
虽然公式看起来非常复杂,但其实实现起来只需要比对公式正常输入就可以,因此实现难度并不大。
LogitMat 的发明人随后在MovieLens 1 Million Dataset 和 LDOS-CoMoDa Dataset 两个不同的数据集合上验证了该算法的准确率和公平性。MovieLens 1 Million Dataset 由6040 名用户和3952 部电影的评分组成,而LDOS-CoMoDa Dataset 是个更小的数据集合。作者在测评准确率的时候使用了MAE 指标。之所以作者使用 MAE 指标,是因为该指标历史最为悠久,能够和海量论文实验数据作对比。而在测评公评性的时候,作者采用了 Degree of Matthew Effect。
实验结果如下:
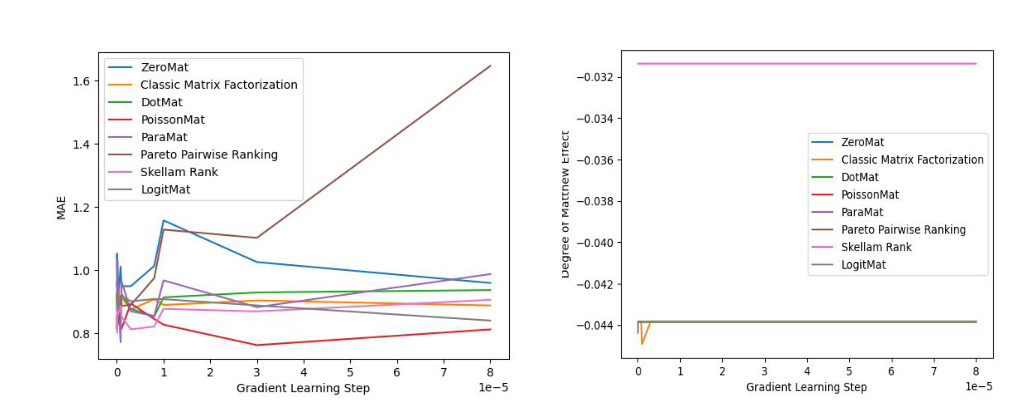
上图显示了LogitMat 和4 种零样本学习,2 种排序学习和经典的矩阵分解算法的对比效果,LogitMat 取得了第2 名的好成绩。
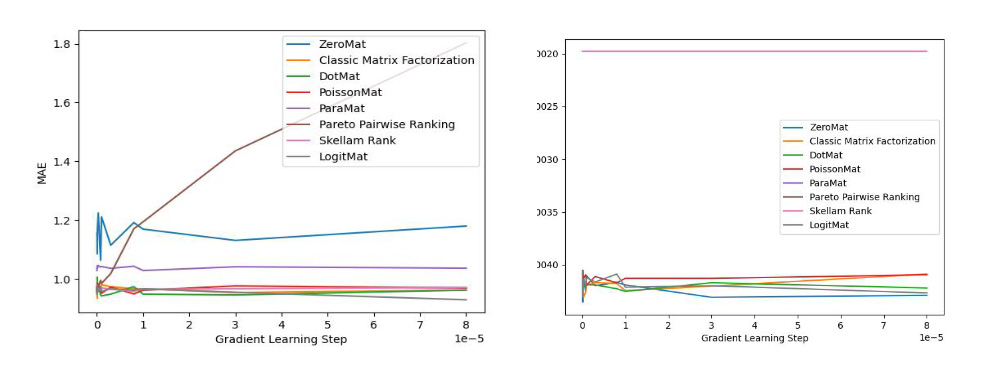
上图显示了算法在 LDOS-CoMoDal 数据集合上的测评结果。同样的,LogitMat 算法的效果非常理想,让人拍案叫绝。
LogitMat 是不需要数据的推荐系统算法,因为在算法的求解过程中没有出现评分矩阵的评分值 R。利用这个思路,我们可以设计出许多新的零样本学习算法。这一切听上去似乎非常可怕——我们可以不利用任何数据预测我们喜欢什么电影。而这并不需要花多少的计算资源就可以实现。事实上,我只要有一台 2024 年的手提电脑就可以预测成千上万人的兴趣爱好。
需要注意的是,我们只需要修改 W 和 Z ,把他们改成更为复杂的形式,就可以把 LogitMat 变为深度学习模型。基于深度学习的零样本学习算法,其实离我们也并不太遥远了。也许有一天,我们会发现,所谓的推荐系统和评分体系不过是一场人类历史上的美丽误会。仅仅因为我们跑的太快,我们忘了自己的数学根基并不牢靠。或许,推荐系统有着我们长久忽略的社会学意义,就像下面这篇论文中描述的:Human Culture: A History Irrelevant and Predictable Experience (论文下载地址:https://arxiv.org/ftp/arxiv/papers/2307/2307.13882.pdf),人类的文化因为幂律现象和时间无关现象被锁死了。
作者简介
汪昊,前 Funplus 人工智能实验室负责人。曾在 ThoughtWorks、豆瓣、百度、新浪等公司担任技术和技术高管职务。在互联网公司和金融科技、游戏等公司任职 13 年,对于人工智能、计算机图形学和区块链等领域有着深刻的见解和丰富的经验。在国际学术会议和期刊发表论文 42 篇,获得IEEE SMI 2008 最佳论文奖、ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 2024最佳论文报告奖。















