众所周知,对于大语言模型来说,规模越大,所需的算力越大,自然占用的资源也就越多。
研究人员于是乎把目光转到了这片领域,即模型的稀疏化(Sparsification)。
今天要介绍的SliceGPT,则可以实现模型的事后稀疏。也就是说,在一个模型训练完了以后再进行稀疏化操作。
该模型由微软研究院和苏黎世联邦理工学院联合发表在了arXiv上。

目前主流的稀疏化技术面临着挺多挑战和困难。比方说,需要额外的数据结构,而且在当下的硬件条件下,速度有限。
SliceGPT就能很好的解决这些问题——它能用一个较小的矩阵来替换每个权重矩阵,从而降低网络的嵌入维度。
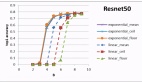
而实际结果也是非常不错的,在LLAMA-2 70B、OPT 66B和Phi-2模型上,SliceGPT去除了多达25%的模型参数,还保证了模型本身99%、99%以及90%的零样本任务的性能。
此外,SliceGPT还可以在更少的GPU上运行,无需额外的代码优化。
在24GB的消费级GPU上,SliceGPT可以将LLAMA-2 70B总的推理计算量减少到密集模型的64%。
而在40GB的A100 GPU上,这个数字达到了66%。
而在SliceGPT背后的,则是Transformer网络中的计算不变性。
下面,就让我们走进论文来一探究竟。
优势所在
大语言模型(LLM)是拥有数十亿个参数的神经网络,以数万亿词库为基础进行训练。
这种过高的成本就导致人们会转向在多个任务中重复使用预先训练好的模型,我们称为基础模型范式。
LLM的规模越来越大,这使得部署预训练模型成为一项昂贵的工作。许多模型需要多个GPU才能计算出预测结果,而且由于模型是自回归的,因此需要神经网络的多次前向传递才能生成文本响应。
因此,降低这些模型的计算要求就大有市场了。
目前,大多数主流的模型压缩技术分为四类:蒸馏(distillation)、张量分解(tensor decomposition,包括低阶因式分解)、剪枝(pruning)和量化(quantization)。
研究人员表示,虽然剪枝方法已经存在了一段时间,但许多方法需要在剪枝后进行恢复微调(RFT)以保持性能,这使得整个过程成本十分高昂,且难以进行扩展。
有了SliceGPT,开发人员现在只需几个小时就能使用单个GPU来压缩大型模型,即使没有RFT的帮助,也能在生成和下游任务中继续保持有竞争力的性能。
剪枝方法的工作原理是将LLM中权重矩阵的某些元素设置为零,并更新矩阵的周围元素以进行补偿。
结果就是,形成了稀疏模式,意味着在神经网络前向传递所需的矩阵乘法中,可以跳过一些浮点运算。运算速度的相对提升取决于稀疏程度和稀疏模式。
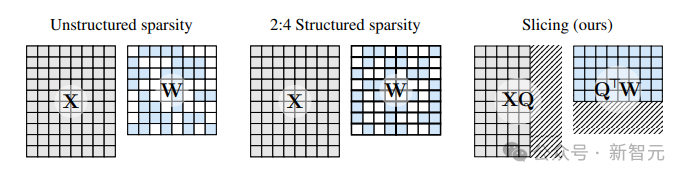
与其他剪枝方法不同,SliceGPT会彻底剪掉(slice的由来)权重矩阵的整行或整列。在切分之前,研究人员会对网络进行一次转换,使预测结果保持不变,因此切分只会产生很小的影响。
结果就是权重矩阵变小了,神经网络块之间传递的信号也变小了,成功降低神经网络的嵌入维度。
下图比较了SliceGPT和现有的稀疏性方法之间的优势,主要体现在以下四个方面:
1. 引入了计算不变性的概念:证明了可以对Transformer中的每个权重矩阵进行正交矩阵变换,而无需改变模型。
2. 利用这一点来编辑Transformer架构中的每个区块,从而将区块间的信号矩阵1投影到其自身上,之后移除变换后权重矩阵的列或行,以减小模型的大小。
3. 研究人员在OPT和LLAMA-2等模型上进行了多次实验,最终结果表明,SliceGPT能够将这些模型压缩到高达30%。此外,在下游任务中,研究人员还对Phi-2模型进行了实验,结果表明所有模型的压缩率最高可达30%,同时还能保持 90%以上的密集性能。
计算不变性
SliceGPT依赖Transformer架构中所固有的计算不变性(computational invariance)。
意思就是,研究人员可以对一个组件的输出进行正交变换,只要在下一个组件中撤销即可。
在网络区块之间执行的 RMSNorm操作不会影响变换,原因在于这些操作是相通的。
首先,研究人员介绍了在RMSNorm连接的Transformer网络中,是如何实现不变性的。然后说明如何将使用 LayerNorm连接训练的网络转换为RMSNorm。
研究人员引入了主成分分析法(PCA)计算各层变换的方法,从而将区块间的信号投射到其主成分上。
最后,再讲讲删除次要主成分和剪掉修改后网络的行或列是如何对应上的。
第一,假设Q是一个正交矩阵,那么有:

而用向量x乘以Q并不会改变向量的常模,因为:

这里,Q的尺寸总是与Transformer D的嵌入尺寸相匹配。
现在假设Xℓ是Transformer一个区块的输出,经过RMSNorm的处理后,以RMSNorm(Xℓ)的形式输入到下一个区块。
如果在RMSNorm之前插入具有正交矩阵Q的线性层,并在RMSNorm之后插入Q⊤,网络将保持不变,因为信号矩阵的每一行都要乘以Q,然后进行归一化处理,再乘以Q⊤。就有:
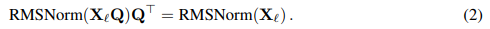
现在,由于网络中的每个注意力(attention)或FFN模块都对输入和输出进行了线性运算,我们可以将额外的运算 Q吸收到模块的线性层中。
由于网络包含残差连接,此时还必须将Q应用于所有前层(一直到嵌入)和所有后续层(一直到LM Head)的输出。
不变函数是指输入变换不会导致输出改变的函数。
在举例中,研究人员可以对transformer的权重应用任何正交变换Q而不改变其结果,因此计算可以在任何变换状态下进行。
这就是所谓的计算不变性,如下图定理所示。

接下来,由于transformer网络的计算不变性仅适用于RMSNorm连接的网络,因此在处理LayerNorm网络之前,研究人员先将LayerNorm的线性块吸收到相邻块中,从而将网络转换为RMSNorm。
下图表示了transformer网络的这种转换。
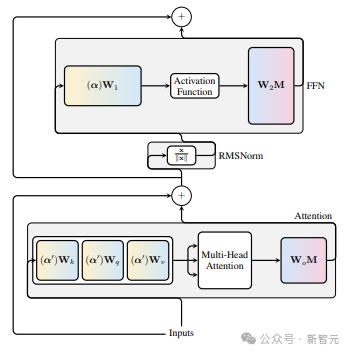
在每个区块中,研究人员将输出矩阵W(out)与均值减法矩阵M相乘,后者考虑了后续LayerNorm中的均值减法。
输入矩阵W(in)被前一个LayerNorm块的比例预乘。嵌入矩阵W(embd)必须进行均值减法,而W(head)必须按最后一个LayerNorm的比例重新缩放。
这里只是操作顺序的简单改变,不会影响输出。
现在transformer中的每个LayerNorm都转换为了RMSNorm,研究人员就可以选择任意的Q来修改模型。
他们需要在每个区块应用不同的正交矩阵Qℓ。
此外,残差连接和区块的输出必须具有相同的旋转(rotation)。为了解决这个问题,研究人员通过对残差进行线性变换Q⊤ ℓ-1Qℓ来修改残差连接。
下图显示了如何通过对残差连接进行额外的线性运算,对不同的区块进行不同的旋转。
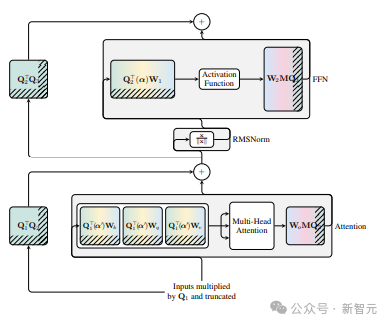
与权重矩阵的修改不同,这些附加运算无法预先计算。
尽管如此,研究人员还是需要这些操作来对模型进行切分,而且可以看到整体速度确实加快了。
为了计算矩阵Qℓ,研究人员使用了PCA。首先从训练集中选择一个校准数据集,通过模型运行该数据集(在将LayerNorm运算转换为RMSNorm 之后),并提取层的正交矩阵。
研究人员使用转换后的网络输出来计算下一层的正交矩阵。
举例来说,如果Xℓ,i是校准数据集中第i个序列的第ℓ个RMSNorm块的输出,那么:

然后再将Qℓ设为Cℓ的特征向量,按特征值递减排序。
主成分分析的目标通常是获取数据矩阵X,并计算其低维表示Z和X的近似重构。
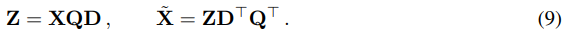
其中第二个等式的左半部分,即代表X的近似重构。
其中Q是X⊤X的特征向量,D是一个D×D(small)的删除矩阵,用于删除矩阵左边的一些列。
下图算式的最小化的线性映射是QD。

从这个意义上说,重构L(2)是最佳的。
而当对区块间的信号矩阵X应用PCA时,研究人员从未将N×D信号矩阵具体化,而是将删除矩阵D,应用于构建该矩阵之前和之后的运算。
这些运算在上述运算中已乘以Q。
之后研究人员删除W(in)的行以及W(out)和 W(embd)的列,同时还删除了插入到剩余连接中的矩阵的行和列,矩阵如下所示: