一、高可用架构介绍
1. 高可用架构是什么
首先来看一个问题,正常访问网络上一个服务的流程是,提交一个 request,然后服务进行一定的处理,返回给我们一个 success 的 response。但有时会因为网络阻塞、资源不足,甚至黑客网络攻击或硬件毁损等原因,导致服务不能返回一个正确的 response,那么这时作为一个线上的业务,就是不可用的,可能会造成非常巨大的损失。

2. 高可用性代表系统的可用性程度,是进行系统设计时的准则之一
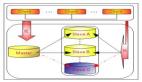
怎样去衡量系统的可用性和不可用性呢?这就引出了高可用性的概念。高可用性代表系统的可用性程度,是进行系统设计的准则之一。高可用性,是系统的一个非常重要的能力,通常是通过提高系统的容错能力来实现的。可用性的一个度量方式是根据系统损毁无法提供服务的时间和系统正常运行时间的比值来得到的。下图右侧表格展示了衡量一个系统可用性和不可用性的等级。
TuGraph-DB 对于可用性的要求,至少是 4 个 9 级别,也就是一年之内宕机时间不能超过 53 分钟。我们在开源之前服务的一个银行用户就已经达到了一个极高可用的等级,也就是 5 个 9 的等级。

3. 常用高可用架构--主备复制
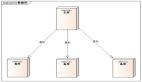
以上是高可用性的定义,为了达到高可用性,就需要去设计高可用架构。比较简单的高可用架构,就是主备复制模式。主备复制模式有一个对外提供服务的主服务器,其它服务器作为其备机。主备复制模式最重要的特点是定期复制主机的数据给备机,比如一个小时、一天。当主机宕机之后,可以通过人工手段,也可以通过 NGINX 做请求转发等自动的方式,让备节点成为主节点。
这种模式非常简单,只复制数据,也因为客户只通过 URL 访问对应的服务,因此是没有感知的。但其弊端是需要人工干预,而更重要的问题是可能会丢失部分数据。不管以多快的频率进行备份,一个小时,甚至十几分钟,都可能会丢失一部分数据,也就无法达成高可用的要求。这种模式比较适合于管理系统,比如学生管理系统,没有高频率的写更新。MySQL、Redis、Mongodb 的高可用架构,基本上官方开源提供的都是这种模式。

4. TuGraph-DB 高可用架构—Raft 共识算法
针对上述缺点,我们选用了 Raft 算法来实现高可用架构。Raft 算法的优点包括:
- 首先,它保持了一主多备的易用性。它有一个强 leader 可以对外提供服务。
- 第二是一致性。一主多备的模式是通过定期复制的方式去进行数据备份。但是 Raft 算法采用的是日志复制方式,复制的是日志并不是数据,当写请求的日志到来之后,会逐个按顺序发送给每一个节点,当超过半数的节点达成一致之后才会提交,所以它不仅不会丢失数据,甚至也不会存在日志空洞或乱序的情况。
- 有了一致性的保证后,安全性也就有了保证,当超过半数的节点达成一致之后,才应用日志,这样就能解决网络分区延迟、丢包、冗余和乱序的错误。
- 基于一致性和安全性,它的可用性也就得到了保证,只要少于半数的节点宕机,即使主机宕机,也可以快速恢复应用,通过一次选举的时间就可以重新选出一个 leader 对外提供服务。
PPT 右下角的表格是国标对于高可用系统的指标评估,RTO 和 RPO 分别是恢复时间指标和恢复点目标,有 6 个等级,TuGraph-DB 已经达到了最高等级。当少量节点故障时,RPO 是 0,也就是没有数据损失,数据恢复时间点指标是小于 15 秒。即使是在部署的时候,无论是在同城的两中心、三中心,还是多地的多中心,都可以达成 RTO 小于 15 秒的标准。

二、TuGraph-DB 高可用架构与规划
1. Server 架构设计—启动集群
上面是我们选择的一个基础算法,下面介绍 TuGraph-DB 具体的高可用架构是怎样设计的。通过一个 CASE 来进行讲解。
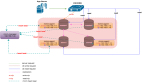
首先建立一个集群,启动集群的方式跟单机版几乎是一致的,只不过要加上 enable_ha 参数和 ha_conf 参数去指定集群里面所有节点的 URL,并且要保证三个或者五个节点是可以进行通信的。在三个节点同时启动后,最先启动的节点的计时器会超时,把自己选成一个候选者,之后向其它节点发送一个投票请求,其它节点接收到请求之后,会返回给候选者一个 success 的 response,当超过半数之后,这个 leader 就当选了。一般来说,在同城的情况下,延迟不会超过 2 毫秒,在两地的情况下,比如上海到深圳,最高延迟不会超过 30 毫秒,所以集群建立的时间和选举的时间是非常快的。

2. Server 架构设计—请求同步
集群建立好之后,可以向其发送读写请求。发送读请求非常简单,client 发送一个读请求给 TuGraph server,server 接到读请求之后,去进行处理。图中给出的一个 cypher 语句,是查询图中边的 label 的数量。在 server 端,会对 cypher 语句进行解析,辨别它是一个只读的请求,一旦确定就会直接发送给 TuGraph-DB,由 TuGraph-DB 进行响应。

写请求会涉及到 DB 数据的变化。Client 发送给 server 之后,server 会通过一些自有的逻辑去判断,如果是一个写请求,那么它会传给内部的一个 raft node,这个 raft node 可以看作是一个 client。因为是三个节点,每个节点持有其它节点的一个 client,每个节点既是 server,也是 client。当收到这个请求之后,只有 leader 节点会处理写请求。它并不会直接应用到 TuGraph-DB 上面,而是先调用客户端把日志去发送给其它节点,当超过半数的节点响应之后,才会应用到 TuGraph-DB 内部,保证写请求日志的一致性。
在高可用集群使用过程中,有很多不可预知的情况,比如正好在应用日志的时候,集群突然挂了或者突然重启了。即使这种情况发生的概率非常低,但在大规模应用中仍然有可能发生。因此,写请求必须是幂等的,请求的 log index 必须是一致的,当它应用到 DB 里时,不能产生重复的提交。所以我们在 DB 内部持有 log 的 index,当 client 由于超时重发或节点的状态发生变化而重复提交时,都不会对 DB 状态产生污染。

3. Server 架构设计—集群成员变更
接下来要考虑的是集群成员变更的情况。首先来看增加节点。增加的节点以 follower 的角色加入集群,和启动的命令一致就可以将节点加入集群。增加节点时还需要同步日志。
再来看删除节点的情况。我们如果使用 Meta Server 去控制集群成员的变更,那么这个 Meta Server 也要是高可用的。如果这个 Meta Server 发生了宕机,会导致整体的不可用。为了简化设计,我们直接让 leader 去控制集群成员的变更。
要删除节点时,可以直接调用下图中给出的命令,让节点离开集群。正常情况下是由 leader 向 follower 发送心跳,为了维护集群正常的状态,follower 也会向 leader 发送心跳,让 leader 感知到它的存在。当 follower 超过一定的时间没有给 leader 发送心跳时,就会把这个 follower 从集群中去除,从而完成了集群成员的变更。
当然需要注意的是,比如有 7 个节点,不能同时删掉 4 个节点,这就相当于有 4 个节点宕机了。

4. Server 架构设计—快照
前文中提到,加入 follower 时,需要同步日志。但是一个集群经过长期的服务,日志一定是非常多的,如果每加入一个 follower,都从一年之前、两年之前的日志开始同步,同步过来除了 Append,还需要应用到 Server 里面,是非常耗时的。所以需要定期对节点打快照,对数据库状态做一个保存。再去加入 follower 时,直接传输快照就可以了。
Tugraph-DB 不管是安装快照还是打快照,都是非常快速的。因为 Tugraph-DB 底层支持 MVCC 多版本,生成快照的时候并不会去阻塞读写请求。

5. Client 架构设计
以上对 server 端的设计进行了介绍,接下来介绍 client 端的设计。Client 端最重要的有两点,第一点是 client 必须持有集群中所有节点的连接,不能只有一个节点。既然持有所有节点的连接,也就是连接池,那么它必须要知道谁是 leader,所以 client 必须要支持在连接上这个集群的时候,自动定位到 leader,通过这种方式,只需要去指定集群中任意一个节点的 URL,就可以连接上整个集群,并自动找到集群中的 leader。
第二个重要的点就是负载均衡。因为 leader 数据是最全的,并且只有它能写。但是整个高可用架构,并不只提供数据的安全性,还要提供读写的功能,并且能更好的利用硬件资源,所以我们要对读请求做负载均衡,以轮询的方式去循环地发送给每一个节点,来提高访问性能。

6. 未来规划
未来规划,主要有三个方面。
第一个是 Witness 角色。这个角色起源于一个场景,假如一个企业没有很多机器,比如只有两台机器,但是它又想用高可用的架构,那应该怎么办?引入 Raft 扩展角色,就是 witness 角色,这个角色有一个特点,它只参与选举,但是不参与日志复制。也就是可以在一个机器里面运行两个节点,一个节点不复制日志,只参与选举。那么在另外一个机器里面去运行一个节点,这样两台机器就可以启动高可用集群了。这样不仅可以减少数据的传输量,而且可以提高可用性和性能,因为它不用应用日志了。
第二个是按需快照。大家在使用图数据库的时候,数据量可能是非常庞大的。比如我们内部有一个 1.2T 的线上业务,当它去打 snapshot 的时候,时间非常长,大概要两个小时。虽然它并不阻塞读写请求,但对性能的影响还是非常严重的,并且会放大存储空间,原来数据是 1.2T,打完之后可能就变成 2.4T 了。所以我们希望改造 Raft 协议,去提供按需生成快照的功能,只有在 follower 加入节点的时候才进行快照,因为只有 follower 加入这个节点时需要快照来加速数据同步。
第三个是高可用工具链。因为 TuGraph-DB 的高可用功能是 3.6 版本才开源,它提供的工具链现在还有一些待完善的地方,比如在线导入,只提供了单机的功能,我们希望可以提供一个集群在线导入,这样就不用去对多机执行在线导入的功能了。还有快照生成工具,client 的接口完善等等。

三、TuGraph-DB 高可用集群部署与应用
1. TuGraph-DB 高可用(V3.6)
关于 TuGraph-DB 高可用集群的部署方式和 client 应用,相关文档已经放到了 tugraph-db.readthedocs.io 网站上。
现在支持 C++、Java 和 Python 多种版本的 client SDK。
2. 高可用集群部署
当原始数据一致的时候,可以直接指定 HA configure 参数启动集群。当初始数据不一致的时候,假如有一个节点有数据,其它节点没有数据,需要把数据同步到其它节点,但是又不能通过 SCP 传,那么就可以通过初始数据不一致的方式去启动。有数据的节点用 bootstrap 方式启动,预先生成一个快照,然后其它节点以 follower 的身份加入集群,加入集群时会安装快照,安装快照之后才会进行选举和 follower 身份的确认。

3. Client 连接应用
启动完集群之后,前端会有一个高可用的列表,client 有直接方式和间接方式连接的区别,主要是考虑到在亚马逊云部署和阿里云部署的区别。连接完了之后就可以去执行请求,比如执行写请求的时候,要先写到 leader 再同步到 follower,可以看到是有日志同步的。