译者 | 朱先忠
审校 | 重楼
简介
目前推荐系统中最重要的模型类型之一是双塔神经网络。它们的结构如下:神经网络的一部分(塔)负责处理有关查询的所有信息(用户、上下文),而另一部分处理有关对象的信息。这些塔的输出内容是嵌入,然后这些嵌入进行乘法运算(点积或余弦运算,正如我们在论文中已经讨论过的方式)。
在一篇关于YouTube的非常好的论文中,可以找到最早提到应用此类网络进行推荐的文章之一。我称这篇文章为经典之作,因为它提出了最适合应用于推荐领域的神经网络模型。
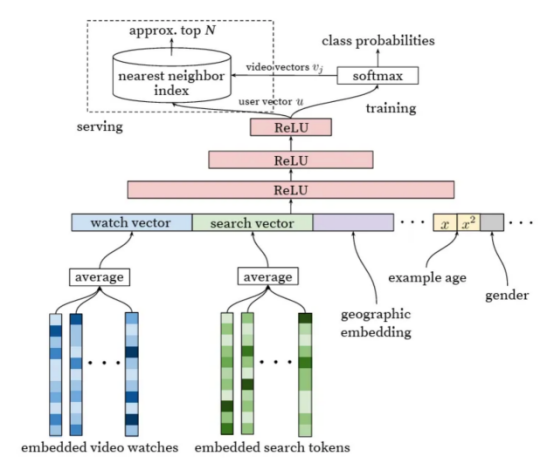
图片来自论文《Deep Neural Networks for YouTube Recommendations》(适用于YouTube推荐的深度神经网络)
这种网络的特征有哪些呢?具体来看,它们与矩阵分解非常相似,矩阵分解实际上是一种特殊情况,只将user_id和item_id作为输入。然而,如果我们将它们与任意神经网络进行比较,对延迟交叉的限制(直到最后一层才允许来自不同塔的输入融合)使两个塔网络在应用中非常高效。要为单个用户构建推荐,我们仅需要计算一次查询塔,然后将此嵌入与文档的嵌入相乘,文档的嵌入通常是预先计算的。这个过程非常快。
此外,这些预先计算的文档嵌入可以被组织到ANN(人工神经网络,是研究生物学上的神经网络,又叫生物神经网络,详见:https://en.wikipedia.org/wiki/Nearest_neighbor_search)索引(例如,HNSW图算法:https://github.com/nmslib/hnswlib)中,以快速找到好的候选者,而不必遍历整个数据库。
有兴趣的读者可以参考文章《Similarity Search, Part 4: Hierarchical Navigable Small World (HNSW)》(相似性搜索,第4部分:分层导航小世界(HNSW))。其中,分层导航小世界(HNSW)是一种先进的算法,适用于在高维空间中进行高效人工神经网络搜索的数据结构和算法,可以有效地找到近似的最近邻。文章地址是:
https://towardsdatascience.com/similarity-search-part-4-hierarchical-navigable-small-world-hnsw-2aad4fe87d37?source=post_page-----fdc88411601b--------------------------------。
我们可以通过计算用户部分来获得更高的效率,不是针对每个查询,而是异步计算,并具有一定的规律性。然而,这意味着牺牲了对实时历史和上下文的考虑。
塔楼本身可能相当复杂。例如,在用户部分,我们可以使用自注意力机制来处理历史,这导致了个性化的转换。但是,实行延迟交叉限制的代价是什么呢?它会影响质量。在同样的注意力机制中,我们不能使用我们目前希望推荐的项目。理想情况下,我们希望关注用户历史记录中的类似项目。因此,具有早期交叉的网络通常用于排名的后期阶段,此时只剩下几十或几百个候选者,而具有后期交叉的网络(双塔)则用于排名的早期阶段和候选者生成。
(有一个纯粹的理论论点认为,针对不同查询的文档的任何合理排序都可以通过足够维度的嵌入进行编码。此外,NLP中的解码器实际上遵循相同的原理,只为每个令牌重新计算查询塔。)
损失函数与负采样
一个令人特别感兴趣的问题是用于训练两个塔网络的损失函数。原则上,他们可以用任何损失函数进行训练,针对不同的结果,甚至对不同的头部有多个不同的结果(每个塔中有不同的嵌入)。然而,一个有趣的变体是在批量负例上进行softmax损失训练。对于数据集中的每个查询文档对,在softmax损失中,同一小批中的其他文档与同一查询一起用作负例文档。这种方法是一种非常有效的困难负例挖掘形式。
但是,重要的是要考虑对这种损失函数的概率解释,这一点并不总是得到很好的理解。在经过训练的网络中,在下面公式中,
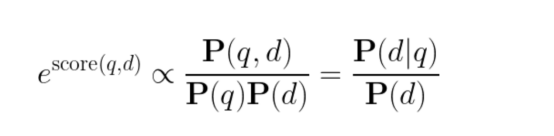
得分的指数不是与给定查询的文档的先验概率成比例,而是与查询特有的PMI(Pointwise Mutual Information,点间互信息:https://en.wikipedia.org/wiki/Pointwise_mutual_information)成比例。这种模型不一定会更频繁地推荐更受欢迎的文档,因为在训练过程中,它们按比例更频繁地显示为负例文档。使用得分作为一个特征可能是有益的,但对于最终排名和候选生成来说,这可能会导致非常具体但质量较差的文档。
谷歌在一篇论文中建议在训练期间通过logQ校正来解决这个问题。另一方面,我们通常在应用阶段而不是在训练期间通过简单地乘以文档P(d)的先验概率来解决这个问题。不过,我们从未比较过这些方法,这确实是一个有趣的比较。
隐式正则化:连接ALS和现代神经网络
有一种协作过滤算法被称为隐式ALS(IALS)。我以前已经提到过了。在前神经网络时代,它可以说是最流行的算法之一。它的显著特点是有效地“挖掘”负例:所有没有交互历史的“用户-对象”对都被视为负例(尽管权重比实际交互小)。此外,与实际挖掘不同的是,这些负例不会被采样,而是在每次迭代中全部使用。这种方法被称为隐式正则化。
这怎么可能呢?给定合理的任务大小(用户和对象的数量),应该有太多的负例,即使列出它们也需要比整个训练过程更长的时间。该算法的美妙之处在于,通过使用MSE损失和最小二乘法,可以在每次完全迭代之前分别为所有用户和所有对象预计算某些元素,这足以执行隐式正则化。通过这种方式,该算法避免了二次方大小。(更多细节,请参阅我当时最喜欢的一篇论文)。
几年前,我思考是否有可能将隐式正则化的美妙想法与更先进的双塔神经网络技术相结合。这是一个复杂的问题,因为存在随机优化而不是全批量,并且不愿意恢复到MSE损失(至少对于整个任务;特别是对于正则化,这可能没问题),因为它往往会产生较差的结果。
我想了很久,终于想出了一个解决办法!几周来,我一直很兴奋,急切地期待着我们将如何用这种方法代替批量负样。
然后,当然(在这种情况下经常发生),我在一篇论文中读到,三年前一切都已经得到解答。再次,是谷歌的贡献。后来,在关于logQ校正的同一篇论文中,他们证明了具有批内负样的softmax损失比隐式正则化效果更好。
这就是为什么我们不再浪费时间来测试这个想法的原因。
我们真的需要推荐模型的负采样吗?
毕竟,我们曾经使用过推荐印象的真实例子,如果用户没有与它们互动,这些可以被视为强负例的典型。(这里不考虑推荐服务本身尚未推出而且还没有印象的情况。)
这个问题的答案并不那么琐碎;这取决于我们打算如何准确地应用训练后的模型:用于最终排名、候选生成,或者仅仅作为输入到另一个模型的特征。
当我们只根据实际印象训练模型时会发生什么?出现了相当强烈的选择偏差,模型只学会很好地区分那些在特定上下文中显示的文档。对于未显示的文档(或者更准确地说,查询文档对),该模型的性能会差得多:它可能对某些文档预测过高,而对其他文档预测过低。当然,这种影响可以通过在排名中应用探索来减轻,但通常这只是部分解决方案。
如果以这种方式训练候选生成器,它可能会生成过多的文档来响应查询,这些文档在这种情况下从未见过,而且它高估了对这些文档的预测。在这些文档中,通常都是无用的信息。如果最终的排名模型足够好,它会过滤掉这些文档,而不会向用户显示它们。然而,我们仍然不必要地在它们身上浪费候选名额(而且可能根本没有留下任何合适的文档)。因此,候选生成器应接受训练,使其了解大部分文档库质量较差,不应推荐(作为候选提名)。针对此问题,负采样是一个很好的方法。
在这方面,最终排名的模型与候选生成非常相似,但有一个重要的区别:它们从错误中吸取教训。当模型因高估某些文档的预测而出错时,这些文档会显示给用户,然后可能被包括在下一个训练数据集中。我们可以在这个新的数据集上重新训练模型,并再次向用户推出。新的误报将会出现。数据集的收集和再训练过程可以重复进行,从而产生一种主动学习。在实践中,只需几次再训练迭代就足以使过程收敛,并使模型停止推荐废话。当然,必须权衡随机推荐的危害,有时值得采取额外的预防措施。但总的来说,这里不需要负采样。相反,它可能会损害探索,导致系统保持在局部最优状态。
如果该模型用于输入到另一个模型的特征,那么同样的逻辑也适用,但高估随机候选文档的预测所带来的危害甚至不那么严重,因为其他特征可以帮助调整最终预测。(如果一个文档甚至没有进入候选列表,我们就不会为它计算特征。)
有一次,我们直接测试并发现,作为特征,标准ALS比IALS工作得更好,但不应用于候选生成。
小结
在本文探索分析中,我们强调了双塔网络在推荐排名中的有效性,检验了损失函数和负采样在模型精度中的重要性,通过隐式正则化弥补了与经典协同过滤的差距,并讨论了负采样在推荐系统中的重要作用。同时,这次讨论强调了推荐系统技术不断发展的复杂性和复杂性。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Two-Tower Networks and Negative Sampling in Recommender Systems,作者:Michael Roizner