最近几天,我们接连被谷歌的多模态模型 Gemini 1.5 以及 OpenAI 的视频生成模型 Sora 所震撼到,前者可以处理的上下文窗口达百万级别,而后者生成的视频能够理解运动中的物理世界,被很多人称为「世界模型」。然而,这些刷屏无数的模型真的能很好的理解世界吗?我们就拿 Sora 来说,该模型在给大家带来惊叹的同时,却不能很好的模拟复杂场景的物理原理,如一位健身的男子倒着跑跑步机。

不仅 Sora,现如今大模型虽然发展迅速,然而其自身也存在缺点,比如在现实世界中不容易用语言描述的内容,模型理解起来非常困难,又比如这些模型难以处理复杂的长程任务。视频模型的出现在一定程度上缓解了这个问题,其能提供语言和静态图像中所缺少的时间信息,这种信息对 LLM 非常有价值。随着技术的进步,模型开始变得对文本知识和物理世界有了更好的理解,从而帮助人类。
然而,由于内存限制、计算复杂性和有限的数据集,从数百万个视频和语言序列的 token 中进行学习挑战巨大。
为了应对这些挑战,来自 UC 伯克利的研究者整理了一个包含各种视频和书籍的大型数据集,并且提出了大世界模型( Large World Model ,LWM),利用 RingAttention 技术对长序列进行可扩展训练,逐渐将上下文大小从 4K 增加到 1M token。

- 论文地址:https://arxiv.org/pdf/2402.08268.pdf
- 项目主页:https://github.com/LargeWorldModel/LWM?tab=readme-ov-file
- 论文标题:WORLD MODEL ON MILLION-LENGTH VIDEO AND LANGUAGE WITH RINGATTENTION
项目 5 天揽获 2.5K 星标。

本文的贡献可总结为如下几个方面:
(a)该研究在长视频和语言序列上训练了一个拥有极大上下文尺寸的 transformers 模型,从而设立了新的检索任务和长视频理解方面的标杆。
(b) 为了克服视觉 - 语言训练带来的挑战,该研究采取了以下措施,包括使用掩码序列以混合不同长度的序列、损失加权以平衡语言和视觉、以及使用模型生成的问答数据来处理长序列对话。
(c) 通过 RingAttention、掩码序列打包等方法,可以训练数百万长度的多模态序列。
(d) 完全开源 7B 参数系列模型,其能够处理超过 100 万 token 的长文本文档(LWM-Text、LWM-Text-Chat)和视频(LWM、LWM-Chat)。
LWM 可以基于文本提示自动生成图像,例如黑色的小狗:

LWM 还可以基于文本提示生成视频,例如在夜空中绽放的烟花在天空中绽放:

接下来,LWM 还能深入理解图片、回答关于图片的问题,例如 LWM 能对经典艺术作品的二次创作进行解读:

值得一提的是,LWM 可以回答时长为 1 小时的 YouTube 视频。比如在示例中,当用户询问「那个穿着霸王龙服装的人骑的是什么车」?GPT-4V 不能提供支持,Gemini Pro Vision 回答错误。只有 LWM 给了「那个穿着霸王龙服装的人骑的是摩托车」正确答案。显示出 LWM 在长视频理解中的优势。

更多示例结果如下,我们可以得出,即使是最先进的商业模型 GPT-4V 和 Gemini Pro 在回答有关视频的问题时都失败了,只有 LWM 仍能回答长达 1h 的 YouTube 视频问题。

这项研究的作者共有四位, 其中一位是深度强化学习大牛、UC 伯克利教授 Pieter Abbeel 。Abbeel 在业余时间还出了很多课程,其中 Intro to AI 课程在 edX 上吸引了 10 万多名学生学习,他的深度强化学习和深度无监督学习教材是 AI 研究者的经典学习资料,包括 CS294-158(Deep Unsupervised Learning)、CS188(Introduction to Artificial Intelligence)、CS287(Advanced Robotics)等。
方法介绍
该研究在 Llama2 7B 的基础上训练了一个大型自回归 Transformer 模型,该模型具有长达 100 万个 token 的超大上下文窗口。为了实现这一点,研究团队采用多种策略:使用书籍资料将上下文扩展到 100 万个 token,然后在长多模态序列上进行联合训练,包括文本 - 图像、文本 - 视频数据和书籍资料。

计算注意力权重的二次复杂度会带来内存限制,因此在长文档上进行训练异常昂贵。为了解决这些计算限制,研究团队采用 RingAttention 实现,利用具有序列并行性的块式计算。理论上这种方法可以将上下文窗口扩展到无限长度,仅受可用设备数量的限制。该研究还使用 Pallas 进一步将 RingAttention 与 FlashAttention 融合,以优化模型性能。
如下表 1 所示,为了扩展上下文窗口的长度,该研究采用渐进式训练的方法。直观地讲,这使得模型可以通过首先学习较短范围的依赖关系,然后再转移到较长的序列上来节省计算量。

LWM 模型的整体架构如下图 4 所示,总体上讲是一个数百万长度 token 序列上的自回归 transformer。视频中的每个帧使用 VQGAN tokenized 为 256 个 token,这些 token 会与文本 token 连接起来,并输入到 transformer 中,以自回归方式预测下一个 token。输入和输出的顺序反映了不同的训练数据格式,包括图像 - 文本、文本 - 图像、视频、文本 - 视频和纯文本格式。

实验结果
该研究将 LWM 与谷歌的 Gemini Pro 和 OpenAI 的 GPT-4 进行了实验比较,实验结果表明 LWM 模型在检索方面能够媲美 GPT-4,如下表 3 所示。

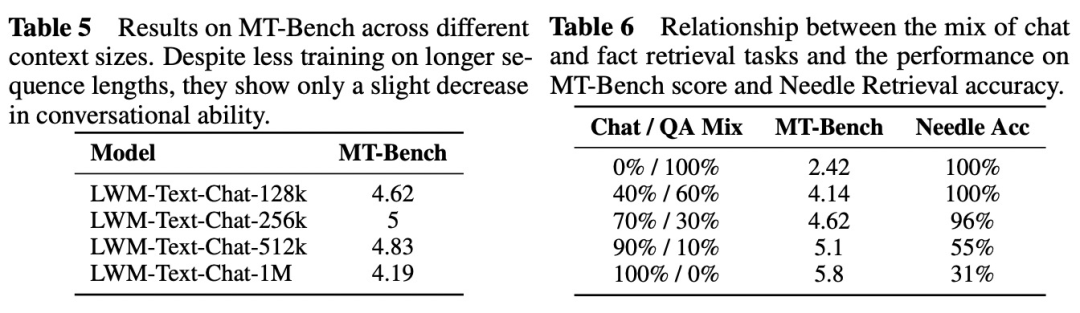
该研究还在 MT-Bench 上评估了模型的对话能力。表 5 显示了模型获得的 MT-Bench 分数。表 6 说明了模型的对话能力与事实检索能力的关系。
在准确性方面,LWM 在上下文窗口为 1M 时优于 GPT-4V 和 Gemini Pro。


感兴趣的读者可以阅读论文原文,了解更多研究内容。