OpenAI,永远快别人一步!
像ChatGPT成功抢了Claude的头条一样,这一次,谷歌核弹级大杀器Gemini 1.5才推出没几个小时,全世界的目光就被OpenAI的Sora抢了去。
100万token的上下文,仅靠一本语法书就学会了一门全新的语言,如此震撼的技术进步,在Sora的荣光下被衬得暗淡无光,着实令人唏嘘。
这次,不过也是之前历史的重演。
为什么ChatGPT会提前诞生?
《这就是ChatGPT》一书对此进行了揭秘:当时OpenAI管理层听说,从OpenAI「叛逃」的前员工创立的公司Anthropic Claude有意提前推出Chatbot。
管理层立马意识到这个产品潜力巨大,于是先下手为强,第一时间改变节奏,出手截胡Anthropic。
11月中旬,在研发GPT-4的OpenAI员工收到指令:所有工作暂停,全力推出一款聊天工具。两周后,ChatGPT诞生,从此改变人类历史。
或许,这也就揭示了为什么一家公司可以永载史册的原因:领导者能够发现有市场潜力的新产品,全面拦截所有成功的可能性。
对于谷歌被截胡一事,网友锐评道:OpenAI用Sora对抗Gemini发布的方式简直了,谷歌从没有受过这样的打击。

这不得不让人怀疑,OpenAI手里是不是还攥着一堆秘密武器,每当竞争对手发布新技术,他们就放出来一个爆炸级消息。
要知道,现在才刚刚是2024年2月,想想接下来要发生的事,不免觉得毛骨悚然。
为何Sora掀起滔天巨浪
Sora一出,马斯克直接大呼:人类彻底完蛋了!

马斯克为什么这么说?
OpenAI科学家Tim Brooks表示,没通过人类预先设定,Sora就自己通过观察大量数据,自然而然学会了关于3D几何形状和一致性的知识。
从本质上说,Sora的技术,就是机器模拟我们世界的一个里程碑。
外媒Decoder直言:OpenAI令人惊叹的视频模型处女作Sora的诞生,感觉就像是GPT-4时刻。

更有人表示,在Sora之中,我切实感受到了AGI。

这也就是为什么Sora会在全世界掀起滔天巨浪的原因。
要了解Sora如此强大的能力从何而来,除了OpenAI官方给出的技术报告,行业大佬也进行了进一步的解读。
LeCun转发了华人学者谢赛宁的推文,认为Sora基本上是基于谢赛宁等人在去年被ICCV 2023收录的论文提出的框架设计而成的。
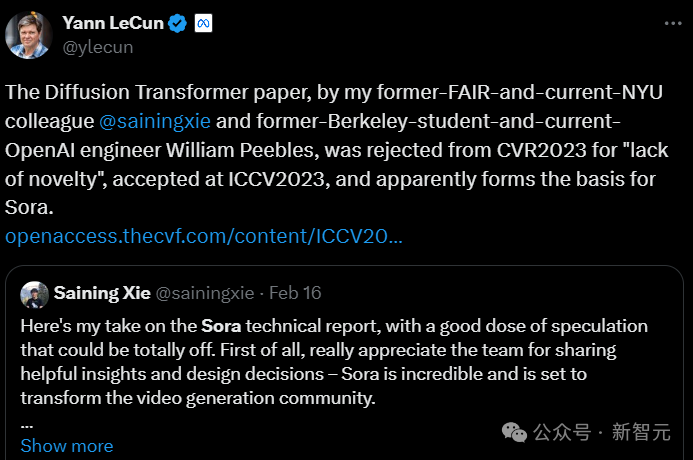
而和谢赛宁一起合著这篇论文的William Peebles之后也加入了OpenAI,领导了开发Sora的技术团队。

所以谢赛宁的对于Sora的技术解读,具备极高的参考价值。

谢赛宁:Sora很厉害,不过好像是用了我的论文成果
AI大神谢赛宁,针对Sora的技术报告谈了自己的看法。

项目地址:https://wpeebles.com/DiT
- 架构:Sora应该是基于他和Bill之前在ICCV 2023上提出的以Transformer为主干的扩散模型(DIT)
其中,DIT=[VAE编码器+VIT+DDPM+VAE解码器]。
根据技术报告,好像没有其他特别的设计了。
-「视频压缩网络」:似乎是一个VAE,但训练的是原始视频数据。
在获得良好的时间一致性方面,tokenize可能起了很重要的作用。
VAE是一个ConvNet。所以从技术上讲,DIT是一个混合模型。

谢赛宁表示,他们在DIT项目没有创造太多的新东西,但是两个方面的问题:简单性和可扩展性。
这可能就是Sora为什么要基于DIT构建的主要原因。
首先,简单意味着灵活
当涉及到输入数据时,如何使模型更加灵活。
例如,在掩码自动编码器(MAE)中,VIT帮助我们只处理可见的patch,而忽略掉被mask的。
同样,Sora可以通过在适当大小的网格中安排随机初始化的patch来控制生成的视频的大小。
UNet并不直接提供这种灵活性。
猜测:Sora可能还会使用谷歌的Patch n‘Pack(Navit),以使DIT能够适应不同的分辨率/持续时间/长宽比。
其次,可扩展性是DIT论文的核心主题
就每Flop的时钟时间而言,优化的DiT比UNet运行得快得多。
更重要的是,Sora证明了DIT缩放法则不仅适用于图像,现在也适用于视频——Sora复制了DIT中观察到的视觉缩放行为。
猜测:在Sora的演示中,第一个视频的质量相当差,谢怀疑它使用的是最基础的模型。
粗略计算一下,DIT XL/2是B/2模型的5倍GFLOPs,因此最终的16倍计算模型可能是DIT-XL模型的3倍,这意味着Sora可能有约30亿个参数。

如果真的是如此,Sora的模型规模可能没有那么大。
这可能表明,训练Sora可能不需要像人们预期的那样,有非常大的算力要求,所以他预测未来Sora迭代的速度将会很快。

进一步的,谢赛宁解释了Sora提供的关键的洞见来自「涌现的模拟能力」这一表现上。
在Sora之前,尚不清楚长期形式的一致性是否会自行涌现,或者是否需要复杂的主题驱动的其他流程,甚至是物理模拟器。
而现在OpenAI已经表明,虽然现在结果还不完美,但这些行为和能力可以通过端到端的训练来实现。
然而,有两个要点还不是很明确。
1. 训练数据:技术报告没有涉及训练的数据集,这可能意味着数据是Sora成功的最关键因素。
目前已经有很多关于游戏引擎数据的猜测。他期待包括电影、纪录片、电影长镜头等。
2. (自回归)长视频生成:Sora的一个重大突破是生成超长视频的能力。
制作一段2秒的视频和1分钟的视频之间的差异是巨大的。
Sora可能是通过允许自回归采样的联合帧预测来实现的,但这里最主要挑战是如何解决误差累积问题,并随着时间的推移保持质量/一致性。
OpenAI Sora的技术,就是机器模拟我们世界的重要下一步
AI究竟如何将静态图形转换为动态、逼真的视频?
Sora的一大创新,就是创新性地使用了时空patch。
通过底层训练和patch,Sora能够理解和开发近乎完美的视觉模拟,比如Minecraft这样的数字世界。这样,它就会为未来的AI创造出训练内容。有了数据和系统,AI就能更好地理解世界。
从此,我们可以解锁VR的新高度,因为它改变了我们看待数字环境的方式,将VR的边界推向了新的高度,创建出近乎完美的3D环境。可以在Apple Vision Pro或Meta Quest上按需与空间计算配对了。
除了谢赛宁的解读之外,AI专家Vincent Koc,也对此展开了详细分析。
Sora的独特方法如何改变视频生成
以往,生成模型的方法包括GAN、自回归、扩散模型。它们都有各自的优势和局限性。
而Sora引入的,是一种全新的范式转变——新的建模技术和灵活性,可以处理各种时间、纵横比和分辨率。
Sora所做的,是把Diffusion和Transformer架构结合在一起,创建了diffusion transformer模型。
于是,以下功能应运而生——
文字转视频:将文字内容变成视频
图片转视频:赋予静止图像动态生命
视频风格转换:改变原有视频的风格
视频时间延展:可以将视频向前或向后延长
创造无缝循环视频:制作出看起来永无止境的循环视频
生成单帧图像视频:将静态图像转化为最高2048 x 2048分辨率的单帧视频
生成各种格式的视频:支持从1920 x 1080到1080 x 1920之间各种分辨率格式
模拟虚拟世界:创造出类似于Minecraft等游戏的虚拟世界
创作短视频:制作最长达一分钟的视频,包含多个短片
这就好比,我们正在厨房里。
传统的视频生成模型,比如Pika和RunwayML,就像照着食谱做饭的厨师一样。
他们可以做出好吃的菜肴(视频),但会受到他们所知的食谱(算法)所限。
使用特定的成分(数据格式)和技术(模型架构),它们只擅长烘焙蛋糕(短片)或烹饪意大利面(特定类型的视频)。

而与他们不同的是,Sora是一位基础知识扎实的新型厨师。
它不仅能照着旧食谱做菜,还能自己发明新食谱!
这位住大厨多才多艺,对于食材(数据)和技术(模型架构)的掌握十分灵活,因而能够做出各种高质量的视频。
探寻Sora秘密成分的核心:时空patch
时空patch,是Sora创新的核心。

它建立在Google DeepMind早期对NaViT和ViT(视觉Transformer)的研究之上。

论文地址:https://arxiv.org/abs/2307.06304
而这项研究,又是基于一篇2021年的论文「An Image is Worth 16x16 Words」。

论文地址:https://arxiv.org/abs/2010.11929
传统上,对于视觉Transformer,研究者都是使用一系列图像patch来训练用于图像识别的Transformer模型,而不是用于语言Transformer的单词。
这些patch,能使我们能够摆脱卷积神经网络进行图像处理。

然而,视觉Transforemr对图像训练数据的限制是固定的,这些数据的大小和纵横比是固定的,这旧限制了质量,并且需要大量的图像预处理。

而通过将视频视为patch序列,Sora保持了原始的纵横比和分辨率,类似于NaViT对图像的处理。
这种保存,对于捕捉视觉数据的真正本质至关重要!
通过这种方法,模型能够从更准确的世界表示中学习,从而赋予Sora近乎神奇的准确性。
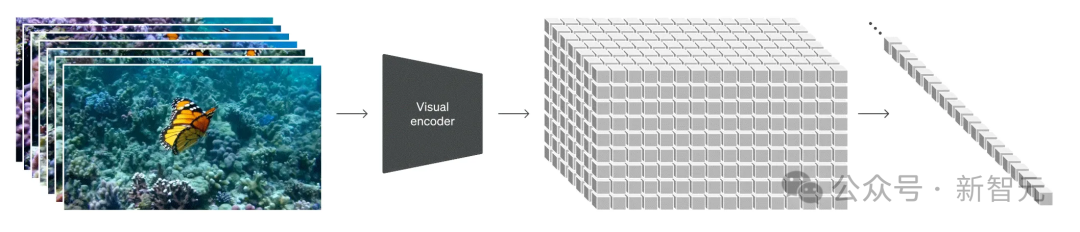
时空patch的可视化
这种方法使Sora能够有效地处理各种视觉数据,而无需调整大小或填充等预处理步骤。
这种灵活性确保了每条数据都有助于模型的理解,就像厨师可以使用各种食材,来增强菜肴的风味特征一样。
时空patch对视频数据详细而灵活的处理,为精确的物理模拟和3D一致性等复杂功能奠定了基础。
从此,我们可以创建看起来逼真且符合世界物理规则的视频,人类也得以一窥AI创建复杂、动态视觉内容的巨大潜力。
多样化数据在训练中的作用
训练数据的质量和多样性,对于模型的性能至关重要。
传统的视频模型,是在限制性更强的数据集、更短的长度和更窄的目标上进行训练的。
而Sora利用了庞大而多样的数据集,包括不同持续时间、分辨率和纵横比的视频和图像。
它能够重新创建像Minecraft这样的数字世界,以及来自Unreal或Unity等系统的模拟世界镜头,以捕捉视频内容的所有角度和各种风格。

这样,Sora就成了一个「通才」模型,就像GPT-4对于文本一样。
这种广泛的训练,使Sora能够理解复杂的动态,并生成多样化、高质量的内容。
这种方法模仿了在各种文本数据上训练LLM的方式,将类似的理念应用于视觉内容,实现了通才功能。

可变Patches NaVit与传统的视觉Transformer
NaViT模型通过将来自不同图像的多个patch打包到单个序列中,得到了显著的训练效率和性能提升一样。
同样地,Sora利用时空patch在视频生成中实现类似的效率。
这种方法允许模型从庞大的数据集中更有效地学习,提高了模型生成高保真视频的能力,同时降低了与现有建模架构相比所需的计算量。
让物理世界栩栩如生:Sora对3D和连续性的掌握
3D空间和物体的一致性,是Sora演示中的关键亮点。
通过对各种视频数据进行训练,无需对视频进行调整或预处理,Sora就学会了以令人印象深刻的精度对物理世界进行建模,原因就在于,它能够以原始形式使用训练数据。
在Sora生成的视频中,物体和角色在三维空间中令人信服地移动和交互,即使它们被遮挡或离开框架,也能保持连贯性。
从此,现实不存在了,创造力和现实主义的界限被突破。
并且,Sora为模型的可能性设立了全新的标准,开源社区很可能会掀起视觉模型的全新革命。
而现在,Sora的旅程才刚刚开始呢,正如OpenAI所说,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的道路。
前方,就是AGI和世界模型了。
不过好在,OpenAI员工透露说,Sora短期内不会面世。
一位OpenAI员工发推表示,现在Sora只会在有限的范围内试用,现在放出的demo主要是为了获得社会大众对它能力的反应
现在,标榜要开发负责任AGI的OpenAI,应该不会冒着风险给大众抛出一个潘多拉魔盒。