













译者 | 李睿
审校 | 重楼
检索增强生成(RAG)是使用大型语言模型(LLM)的关键工具。RAG使LLM能够将外部文档合并到它们的响应中,从而更紧密地与用户需求保持一致。这个功能在传统上使用LLM犹豫不决的领域尤其有益,尤其是在事实很重要的时候。
自从ChatGPT和类似的LLM推出以来,出现了大量的RAG工具和库。以下是需要了解的关于RAG如何工作以及如何开始使用它与ChatGPT、Claude或选择的LLM。
RAG提供的好处
当开发人员与大型语言模型交互时,它会利用其训练数据中嵌入的知识来制定响应。然而,规模庞大的训练数据往往超过模型的参数,导致响应可能不完全准确。此外,训练中使用的各种信息可能会导致LLM混淆细节,可能提供看似合理但不正确的答案,这种现象被称为“幻觉”。
在某些情况下,开发人员可能希望LLM使用未包含在其训练数据中的信息,例如最近发布的新闻文章、学术论文或专有公司文档。这就是RAG发挥重要作用的地方。
RAG通过在LLM生成响应之前为其提供相关信息来解决这些问题。这包括从外部源检索文档(因此得名),并将其内容插入到对话中,以向LLM提供场景。
这一过程增强了模型的准确性,并使其能够根据提供的内容制定响应。实验表明,RAG能显著减少“幻觉”。在需要最新或客户特定信息的应用程序中,它也被证明是有益的,这些信息不包括在训练数据集中。
简单地说,标准LLM和支持RAG的LLM之间的区别可以比喻成两个人回答问题。标准LLM就像一个人根据记忆做出回应,而支持RAG的LLM则像获得文件的另一个人,可以根据文件内容阅读和回答问题。
RAG是如何工作的
RAG的工作原理很简单。它标识与查询相关的一个或多个文档,将它们合并到提示中,并修改提示以包含模型基于这些文档的响应的说明。
开发人员可以手动实现RAG,其方法是将文档的内容复制粘贴到提示中,并指示模型根据该文档制定响应。
RAG管道将这一过程实现自动化以提高效率。它首先将用户的提示与文档数据库进行比较,检索与主题最相关的提示。然后,RAG管道将它们的内容集成到提示符中,并添加指令以确保LLM符合文档的内容。
RAG管道需要什么?
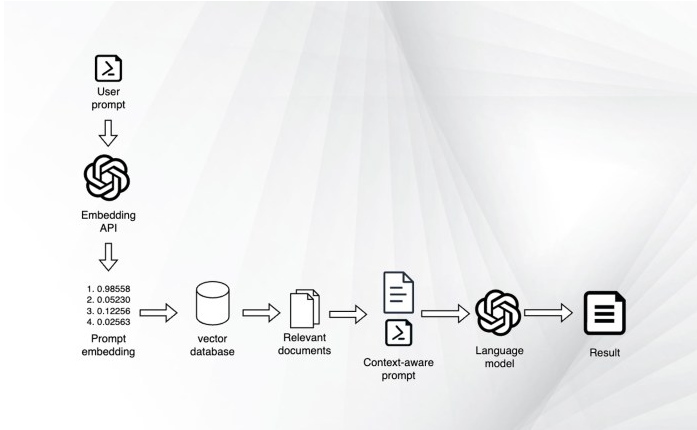
图1 使用嵌入和矢量数据库检索相关文档
虽然RAG是一个直观的概念,但它的执行需要多个组件的无缝集成。
首先,需要生成响应的主要语言模型。除此之外,还需要一个嵌入模型将文档和用户提示编码为表示其语义内容的数字列表或“嵌入”。
接下来,需要一个矢量数据库来存储这些文档嵌入,并在每次收到用户查询时检索最相关的文档嵌入。在某些情况下,排序模型还有助于进一步细化向量数据库提供的文档的顺序。
对于某些应用程序,开发人员可能希望合并一种额外的机制,将用户提示分为几个部分。这些部分中的每一个都需要自己独特的嵌入和文档,从而提高所生成响应的准确性和相关性。
如何在无代码的情况下开始使用RAG
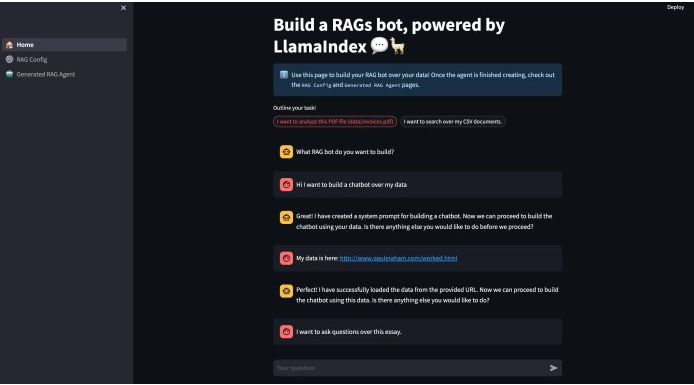
图2 无代码RAG与LlamaIndex和ChatGPT
LlamaIndex最近发布了一个开源工具,它允许开发人员开发基本的RAG应用程序,几乎不需要编写代码。虽然目前仅限于单个文件的使用,但未来的增强功能可能包括对多个文件和矢量数据库的支持。
这个名为RAG的项目建立在Streamlit web应用程序框架和LlamaIndex之上,LlamaIndex是一个强大的Python库,对RAG特别有用。如果开发人员熟悉GitHub和Python,其安装很简单:只需克隆存储库,运行安装命令,然后将OpenAI API令牌添加到自述文档中指定的配置文件中。
目前,RAG被配置为与OpenAI模型一起工作。但是,可以修改代码以使用其他模型,例如Anthropic Claude、Cohere模型或服务器上托管的开源模型(如Llama 2)。LlamaIndex支持所有这些模型。
应用程序的初始运行需要设置RAG代理。这涉及到确定设置,包括文件、将文件分成块的大小,以及为每个提示检索的块的数量。
块在RAG中起着至关重要的作用。当处理一个大文件时,例如一本书或一篇多页的研究论文,有必要把它分解成可管理的块,例如500个令牌。这允许RAG代理定位文档中与提示相关的特定部分。
在完成这些步骤之后,应用程序将为RAG代理创建一个配置文件,并用它来运行代码。RAG是一个有价值的工具,可以从增强检索开始并在此基础上进行构建。人们可以在相关网站上找到完整的指南。
原文标题:No-code retrieval augmented generation (RAG) with LlamaIndex and ChatGPT,作者:Ben Dickson
链接:https://bdtechtalks.com/2023/11/22/rag-chatgpt-llamaindex/






























